Python爬虫之记录一次下载验证码的尝试
好久没有写过爬虫的文章了,今天在尝试着做验证码相关的研究时,遇到了验证码的收集问题。
一般,验证码的加载都有着比较复杂的算法和加密在里边,但是笔者今天碰到的验证码却比较幸运,有迹可循。在此,给出本爬虫的相关记录。
注意,文章和代码中均不会给出相关的真实网站的信息,避免不道德的行为。
首先,让我们来看一看该验证码的页面,如下:
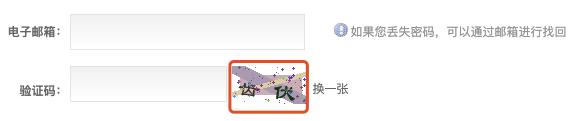
如果我们尝试着查看该验证码加载时的源代码,会发现源码如下:

我们可以发现,该验证码的加载机制其实并不复杂,只是在网址后面跟了一个时间戳,而这个时间戳,是由JavaScript中的方法产生的,函数内容为new Date().getTime()。
知道了验证码背后加载的原理,那么我们不难通过Python来实现验证码的下载。
可惜的是,上述JS函数产生的时间戳是13位数字,而Python的time.time()方法产生的时间戳为浮点数,小数点前10位,小数点后6位。那么,我们如果来产生符合上述JS函数产生的时间戳呢?
一个简单的想法是,我们让Python来调用JS。真的可以吗?幸运的是,前人已经提我们做好了这个工作,有个神奇的Python第三方模块,叫做PyExecJS。顾名思义,这个模块就是用来执行JS代码的。
该模块的源码中给出了一个例子,我们可以尝试下,代码如下:
# -*- coding: utf-8 -*-
import execjs
print(execjs.eval("'red yellow blue'.split(' ')"))
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
""")
print(ctx.call("add", 1, 2))
输出结果如下:
['red', 'yellow', 'blue']
3
OK,有了上面的例子,我们就知道如何使用该模块了,我们可以轻松地写出下面的代码来下载验证码了:
# -*- coding: utf-8 -*-
import execjs
import urllib.request
js_func = """
function get_milliseconds(){
return new Date().getTime();
}
"""
ctx = execjs.compile(js_func)
result = ctx.call("get_milliseconds")
print(len(str(result)))
# 注意,网址已经隐藏
url = "http://***/captcha/?%s" % result
urllib.request.urlretrieve(url, "1.png")
下载的验证码如下:
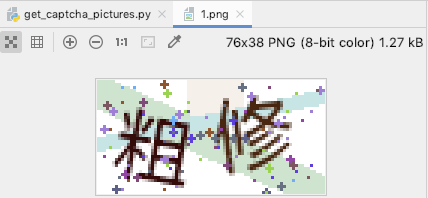
通过我们这次的尝试,发现如下:
- PyExecJS支持Python对JavaScript的操作,所以下次有机会,可以在Python中执行JS函数;
- 验证码的加载算法不宜简单,要注意加密。
本次分享到此结束,感谢大家的阅读~
Python爬虫之记录一次下载验证码的尝试的更多相关文章
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- python爬虫学习过程记录
项目为爬取Python词条的信息. 项目代码在我的码云仓库. https://gitee.com/libo-sober/learn-python/tree/master/baike_spider 1. ...
- python爬虫学习记录
爬虫基础 urllib,urllib2,re都是python自带的模块 urllib,urllib2区别是urllib2可以接受一个Request类的实例来设置url请求的headers,即可以模拟浏 ...
- Python爬虫实践 -- 记录我的第二只爬虫
1.爬虫基本原理 我们爬取中国电影最受欢迎的影片<红海行动>的相关信息.其实,爬虫获取网页信息和人工获取信息,原理基本是一致的. 人工操作步骤: 1. 获取电影信息的页面 2. 定位(找到 ...
- Python爬虫学习记录【内附代码、详细步骤】
引言: 昨天在网易云课堂自学了<Python网络爬虫实战>,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐! 另外,在网上看到一位学友整理的课程记录,非常详细,可以优先 ...
- Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记
涉及关键词:requests库 requests.post方法 cookies登陆 version 1.5(附录):使用post方法登陆豆瓣,成功! 缺点:无法获得登陆成功后的cookie,要使用js ...
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
随机推荐
- Innodb的三大关健特性
今天看<MySql技术内幕InnoDB存储引擎>一书,学习了Mysql的三大关健特性,并记录如下: 插入缓冲 双写(double write) 自适应Hash索引 在记录这些特性之前,先对 ...
- php设计模式总结
#1 使用设计模式(如建造者.外观.原型和模板模式)更快速.更有效地创建对象 #2 使用数据访问对象和代理设计模式分离体系结构 #3 使用委托.工厂和单元素设计模式改善代码流和控制 #4 在不修改对象 ...
- docker win10 推送镜像问题
镜像制作 docker build -t gameniuniu:v1.1 . 一.推送 1.docker images 中查找IMAGE ID镜像 2.docker commit <IMAGE ...
- IO操作与IO模型
目录 一 .IO操作本质 二. IO模型 BIO – 阻塞模式I/O NIO – 非阻塞模式I/O IO Multiplexing - I/O多路复用模型 AIO – 异步I/O模型 三.同步I/O与 ...
- k8s yaml示例
Kind选择 https://kubernetes.io/zh/docs/concepts/workloads/controllers/ Pod示例 apiVersion : v1 #版本v1 kin ...
- python3(九) Section
# list或tuple的部分元素 L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack'] # -----------------传统方法 print([L[ ...
- docker中的dockerfile
什么是dockerfile? Dockerfile是一个包含用于组合映像的命令的文本文档.可以使用在命令行中调用任何命令. Docker通过读取Dockerfile中的指令自动生成映像. docker ...
- 一个不错的java学习博客
http://iteye.blog.163.com/blog/static/18630809620131484835129/
- java 第七周课后作业0417
定义一个矩形类Rectangle:(知识点:对象的创建和使用)1 定义三个方法:getArea()求面积.getPer()求周长,showAll()分别在控制台输出长.宽.面积.周长.2 有2个属性: ...
- 【draft】Team project :Bing dictionary plug-in
课后~ 开会调研开会调研开会~ 在和Bing词典负责人进行了可行性的深入磋商后,我们对本次选题有了更加清晰的认识~困难好多~然而终于敲定了项目内容,我们的目标是这样一款神奇的插件,它帮你记录下新近查询 ...