Python爬虫之记录一次下载验证码的尝试
好久没有写过爬虫的文章了,今天在尝试着做验证码相关的研究时,遇到了验证码的收集问题。
一般,验证码的加载都有着比较复杂的算法和加密在里边,但是笔者今天碰到的验证码却比较幸运,有迹可循。在此,给出本爬虫的相关记录。
注意,文章和代码中均不会给出相关的真实网站的信息,避免不道德的行为。
首先,让我们来看一看该验证码的页面,如下:
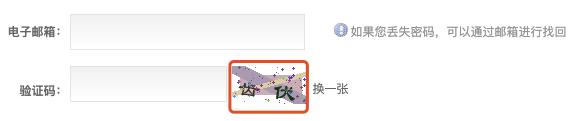
如果我们尝试着查看该验证码加载时的源代码,会发现源码如下:

我们可以发现,该验证码的加载机制其实并不复杂,只是在网址后面跟了一个时间戳,而这个时间戳,是由JavaScript中的方法产生的,函数内容为new Date().getTime()。
知道了验证码背后加载的原理,那么我们不难通过Python来实现验证码的下载。
可惜的是,上述JS函数产生的时间戳是13位数字,而Python的time.time()方法产生的时间戳为浮点数,小数点前10位,小数点后6位。那么,我们如果来产生符合上述JS函数产生的时间戳呢?
一个简单的想法是,我们让Python来调用JS。真的可以吗?幸运的是,前人已经提我们做好了这个工作,有个神奇的Python第三方模块,叫做PyExecJS。顾名思义,这个模块就是用来执行JS代码的。
该模块的源码中给出了一个例子,我们可以尝试下,代码如下:
# -*- coding: utf-8 -*-
import execjs
print(execjs.eval("'red yellow blue'.split(' ')"))
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
""")
print(ctx.call("add", 1, 2))
输出结果如下:
['red', 'yellow', 'blue']
3
OK,有了上面的例子,我们就知道如何使用该模块了,我们可以轻松地写出下面的代码来下载验证码了:
# -*- coding: utf-8 -*-
import execjs
import urllib.request
js_func = """
function get_milliseconds(){
return new Date().getTime();
}
"""
ctx = execjs.compile(js_func)
result = ctx.call("get_milliseconds")
print(len(str(result)))
# 注意,网址已经隐藏
url = "http://***/captcha/?%s" % result
urllib.request.urlretrieve(url, "1.png")
下载的验证码如下:
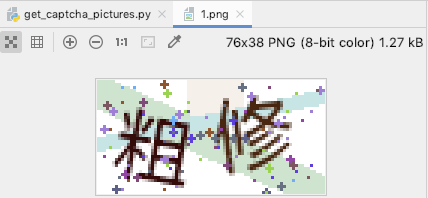
通过我们这次的尝试,发现如下:
- PyExecJS支持Python对JavaScript的操作,所以下次有机会,可以在Python中执行JS函数;
- 验证码的加载算法不宜简单,要注意加密。
本次分享到此结束,感谢大家的阅读~
Python爬虫之记录一次下载验证码的尝试的更多相关文章
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- python爬虫学习过程记录
项目为爬取Python词条的信息. 项目代码在我的码云仓库. https://gitee.com/libo-sober/learn-python/tree/master/baike_spider 1. ...
- python爬虫学习记录
爬虫基础 urllib,urllib2,re都是python自带的模块 urllib,urllib2区别是urllib2可以接受一个Request类的实例来设置url请求的headers,即可以模拟浏 ...
- Python爬虫实践 -- 记录我的第二只爬虫
1.爬虫基本原理 我们爬取中国电影最受欢迎的影片<红海行动>的相关信息.其实,爬虫获取网页信息和人工获取信息,原理基本是一致的. 人工操作步骤: 1. 获取电影信息的页面 2. 定位(找到 ...
- Python爬虫学习记录【内附代码、详细步骤】
引言: 昨天在网易云课堂自学了<Python网络爬虫实战>,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐! 另外,在网上看到一位学友整理的课程记录,非常详细,可以优先 ...
- Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记
涉及关键词:requests库 requests.post方法 cookies登陆 version 1.5(附录):使用post方法登陆豆瓣,成功! 缺点:无法获得登陆成功后的cookie,要使用js ...
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
随机推荐
- 7.Metasploit后渗透
Metasploit 高阶之后渗透 01信息收集 应用场景: 后渗透的第一步,更多地了解靶机信息,为后续攻击做准备. 02进程迁移 应用场景: 如果反弹的meterpreter会话是对方打开了一个你预 ...
- C/C++知识总结 三 C/C++数据类型与输入输出
C/C++数据类型与输入输出 基本数据类型 输入与输出 复合数据类型(将在下几篇博客中总结) C/C++数据类型 数据类型总图 数据类型差别 数据类型不同的意义 1)指明数据的大小,以便正确分配,访问 ...
- IntelliJ IDEA 激活码 [已购买,分享给码友]
一.前言 笔者在网上找了一圈,各种方法都试过了,之前那种在网上随便找个注册码,过了一段时间就被封了,想了想还是经常用的和朋友一起购买了,方便日后使用 二.下载最新的 IDEA 其实也可以从老版本直接升 ...
- [原创] 关于步科eview人机界面HMI的使用 - HMI做Slave - Modbus RS485通讯
做测试设备,或者自动化设备常常用到HMI 触摸屏 我有个案子用到了 步科的eview 触摸屏 型号 ET070 我的是单片机主板 控制 HMI显示,通讯用485 MODBUS 单片机板充当 主控 , ...
- 1048 Find Coins (25分)
Eva loves to collect coins from all over the universe, including some other planets like Mars. One d ...
- (二) vim的Tabbar插件
关闭Tabbar中一个buffer的技巧: 如果你使用Tabbar的同时还集成了某种窗口分割插件(如 Winmanager,NERDTree)或者vim处于分栏显示状态,这时你想用传统的 :bd 或 ...
- 这些基本的 HTML5 标签你不能不知道
HTML5元素 HTML5是HTML最新的修订版本,2014年10月由万维网联盟(W3C)完成标准制定. HTML5是用来写网页的一门标记语言. 使用的时候需要在首行声明HTML,如:<!DOC ...
- wireshark抓包实战(二),第一次抓包
1.选择网卡. 因为wireshark是基于网卡进行抓包的,所以这时候我们必须选取一个网卡进行抓包.选择网卡一般有三种方式 (1)第一种 当我们刚打开软件是会自动提醒您选择,例如: (2)第二种 这时 ...
- 非PDC角色DC强制NTP
前一阵,公司其他部门员工告诉我,他们的系统无法通过LDAP搜索账户了 经过检查,发现该服务器的时间居然比我们的时间服务器PDC快了将近20分钟,而且该问题机器的 时间源并非PDC,而是另外一台普通DC ...
- HBase-2.2.3源码编译-Windows版
源码环境一览 windows: 7 64Bit Java: 1.8.0_131 Maven:3.3.9 Git:2.24.0.windows.1 HBase:2.2.3 Hadoop:2.8.5 下载 ...