mode|平均数|方差|标准差|变异系数|四分位数|几何平均数|异众比率|偏态|峰态
应用统计学
数据的概括性度量
集中趋势
Mode众数是唯一描述无序类别数据,由图可知众数便是图形中的峰。


对于类别变量,众数就是某一种类别。
中位数和平均数都可能不是样本中的值。
中位数不受极值影响,对于类别数据来说,中位数是某一类别(同mode),各变量值与中位数的离差绝对值之和最小,与均数不同。
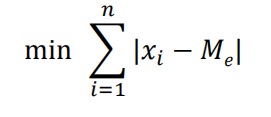
平均数的求法,令函数等于各变量值与平均数的离差平方之和,该函数表达如下式。
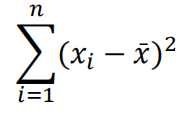
对该函数求一阶导,如下式,
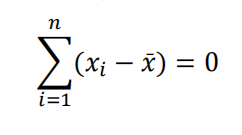
当一阶导为零时该函数取到最小值,此时样本均值表达式为:
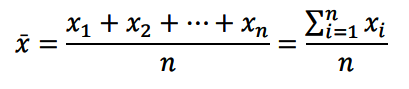
各变量值与平均数的离差平方之和最小,各变量值与中位数的离差绝对值之和最小。两性质验证如下表:
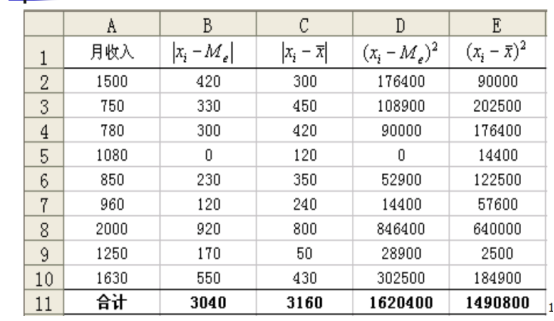
平均值可代数计算且无偏有效,所以数学属性比中位数好。
四分位数中上下四分位数有不同算法,算法的准确度也不同,但是n变大则各算法之间差距变小,同时变的更精确。
几何平均数推导:由以下公式转换,其中x值为比率。
100(1+G)=100(1+x1)(1+x2)(1+x3),等式变换之后得到G的表达式,该G值即为

应用:一种测量多次的平均数比一次测量更准确,样本均值的方差比随机变量的方差小,更准确。所以用样本均值的分布比总体分布的方差小。样本均值方差是总体分布方差/n.
离散趋势
因为平均值不能代表大多数情况,所以引入描述离散程度的特征值。
异众比率即与众数不一样观测值的比率,如下式。
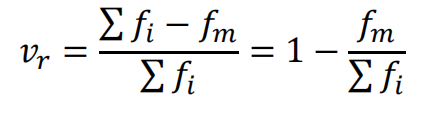
如果异众比率大,则其代表性不是很好。
四分位差:inter quartile range,即3/4处值-1/4处值。
极差:未考虑数据分布
平均差:离均差总和除以总数
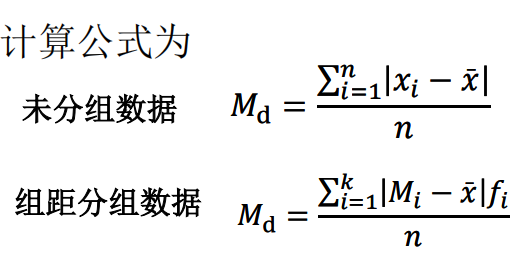
方差&标准差
为什么样本方差的分母为n-1?
若使用n作为分母,则用样本方差估计总体方差有偏。若使用样本方差则无偏。

2.自由度degree of freedom:指数据个数与附加给独立的观测值的约束或限制的个
数之差,即n-(约束个数)。所以就此例可知,要求样本方差,但其中除已知特征值外,还有一个样本均值的约束,所以样本方差的自由度为n-1。
除此之外还有变异系数,消除了数据水平高低和计量单位的影响。
偏态和峰态
偏态系数即表现数据分布的较正态分布的偏斜程度:

峰态系数即表现与标准正态分布比峰值的高低:

mode|平均数|方差|标准差|变异系数|四分位数|几何平均数|异众比率|偏态|峰态的更多相关文章
- 比率(ratio)|帕雷托图|雷达图|轮廓图|条形图|茎叶图|直方图|线图|折线图|间隔数据|比例数据|标准分数|标准差系数|离散系数|平均差|异众比率|四分位差|切比雪夫|右偏分布|
比率是什么? 比率(ratio) :不同类别数值的比值 在中文里,比率这个词被用来代表两个数量的比值,这包括了两个相似却在用法上有所区分的概念:一个是比的值:另一是变化率,是一个数量相对于另一数量的变 ...
- 方差+标准差+四分位数+z-score公式
一.方差公式 $S^2 = \frac{1}{N}\sum_{i=1}^{N}(X_i - \mu)^2 = \frac{1}{N}[(X_1-\mu)^2 + (X_2-\mu)^2 + ... + ...
- C语言之文件操作07——读取文件数据并计算均值方差标准差
//文件 /* =============================================================== 题目:从文本文件"high.txt" ...
- 数据分析First week(7.15~7.21)
描述统计学 当我们面对大量信息的时候,经常会出现数据越多,事实越模糊的情况,因此我们需要对数据进行简化,描述统计学就是用几个关键的数字来描述数据集的整体情况. 1.集中趋势 1.1 众数 众数是样本观 ...
- R语言笔记005——计算描述性统计量
数据的分布特征: 分布的集中趋势,反应各数据向其中心值靠拢或聚集的程度(平均数,中位数,四分位数,众数) 分布的离散程度,反应各数据远离其中心值的趋势(极差,四分位差,方差,标准差,离散系数) 分布的 ...
- 数据分析second week(7.22~7.28)
描述性统计Python实现 这周学习时间也就几个小时,由于python也正在学习,Anaconda也有,所以那些安装啥的就偷懒下不写了,直接贴出python代码 数据是随机生成,计算是调用库里的函数. ...
- 【Udacity】数据的集中程度:众数、平均数和中位数
重视Code Review 极致--目标是成为优秀的开发者 Data tells a story!(数据会讲故事) 分析过程对于建模非常的重要,可以帮助我们减少实际上不相关的特征被错误的加入到模型中, ...
- SPSS 2019年10月31日 20:20:53今日学习总结
◆描述性统计分析 概念:描述性统计分析方法是指应用分类.制表.图形及概括性数据指标(去均值,方差等)来概括数据分布特征的方法. 而推断性统计分析方法则是通过随机抽样,应用统计方法把从样本数据得到的结论 ...
- 描述性统计分析-用脚本将统计量函数批量化&分步骤逐一写出
计算各种描述性统计量函数脚本(myDescriptStat.R)如下: myDescriptStat <- function(x){ n <- length(x) #样本数据个数 m &l ...
随机推荐
- Spring Cloud Alibaba 教程 | Nacos(五)
扩展配置(extended configurations) 通过之前的学习,我们知道应用引入nacos配置中心之后默认将会加载Data ID= ${prefix} - ${spring.profile ...
- LA 6621 /ZOJ 3736 Pocket Cube 打表+暴力
这道题是长沙区域赛的一道简单题,当时题目在ZOJ重现的时候就做了一次,但是做的好复杂,用的BFS暴力,而且还没打表,最后还是莫名其妙的爆栈错误,所以就一直没弄出来,昨天做到大白书上例题05年东京区域赛 ...
- chrome安装switchyomega
由于在国外网站找不到下载链接,在国内招了个crx文件,以下为安装crx教程 首先修改后缀为zip,再解压, 得到以下文件 然后在chrome里找到扩展程序, 打开开发者模式,点击-加载已解压的扩展程序 ...
- spring学习之依赖注入DI与控制反转IOC
一 Ioc基础 1.什么是Ioc? Ioc(Inversion of Control)既控制反转,Ioc不是一种技术,而是一种思想,在Java开发中意味着将设计好的对象交给容器来进行控制,并不是像传统 ...
- 吴裕雄--天生自然 PHP开发学习:表单验证
<!DOCTYPE HTML> <html> <head> <meta charset="utf-8"> <title> ...
- Linux应用编程之lseek详解
Linux应用编程之lseek详解 1.lseek函数介绍 (1).文件指针:当我们要对一个文件进行读写时,一定要先打开这个文件,所以我们读写的所有文件都是动态文件.动态文件在内存中的形态就是文件流的 ...
- webpack--删除dist目录
1.安装clean-webpack-plugin插件 npm install clean-webpack-plugin --D 2.在webpack.dev.conf.js或者webpack.conf ...
- 反射(hasattr和setattr和delattr)
反射(hasattr和setattr和delattr) 一.反射在类中的使用 反射就是通过字符串来操作类或者对象的属性, 反射本质就是在使用内置函数,其中反射有以下四个内置函数: hasattr:通过 ...
- iOS 一个新方法:- (void)makeObjectsPerformSelector:(SEL)aSelector;
NSArray 里面的一个方法, - (void)makeObjectsPerformSelector:(SEL)aSelector: 这是一个类似于执行for循环的方法,可以这样用,当需要删除一个v ...
- 论文翻译——Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection
Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection 动态池和展开递归自动编码器的意译检测 论文地 ...