【摩天大楼平地起】基础篇 09 简述N种查找算法
引言
在开始之前首先可以先思考一下假如没有查找算法会是什么情况?所有数据结构都需要全部遍历一遍,每次都一遍又一遍的查,从本质而言查找算法就是为了提高效率。
经过前人一代又一代的努力,目前的查找算法大致可以分为静态查找和动态查找。从名字上就很容易理解,静态查找通俗而言就是查找的时候数据不变,而动态查找也可以理解为查找的时候数据发生了改变。
所以这就衍生了个推论,即静态查找和动态查找算法不能通用,或者说在静态算法中使用动态算法不划算。
还可以从顺序的维度来划分,可以划分为无序查找和有序查找。当然其中的顺序是相对的,也就是说是依据某个参照物来比是有序或者无序。
平时大多数开发人员所编写的代码基本都是顺序查找,也就是说O(n)操作。
接下去就让我们站在前人的肩膀上,改进一下我们的思路吧。
二分查找
二分查找,平时在工作中应该或多或少都有听说过,这也算是除了顺序查找以外,最容易想到的查找算法了。
核心思路就是不断的除2,直到找到为止,就类似于以前电视节目里面的猜价格,每次猜中间的值。
但是这个算法前提就是给定的数据必须是有序的,如果无序的话,就没有办法决定是选上半截的中间值或是选下半截的中间值了。
在这里贴上一张与顺序查找的对比图:

代码实现:
public class BinarySearch
{
public static int Demo(List<int> data, int key)
{
int low = , mid = ;
int high = data.Count - ;
while (low <= high)
{
mid = (low + high) / ;
if (data[mid] == key)
{
return mid;
}
else if (data[mid] > key)
{
high = mid - ;
}
else if (data[mid] < key)
{
low = mid + ;
}
}
return -;
}
}
BinarySearch
使用场景:
.net已经提供的二分实现:BinarySearch
二分法适用于数据较为连续较为均匀的,如内存地址,索引等
算法复杂度 O(logn)
斐波那契查找
提到斐波那契,具有大学经历的小伙伴一定不会陌生,第一反应肯定就是斐波那契数列,而斐波那契查找可能有些小伙伴就没有听过了。
其实这个查找就是利用了斐波那契的黄金比例来减少分的次数。可以理解为是二分法的一个优化。
ps:没有找到gif,来个png先顶上(捂脸)
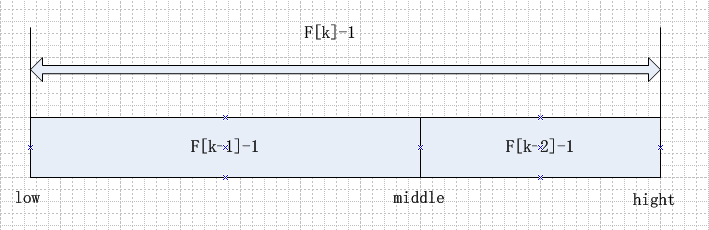
从图中可以看到斐波那契查找改变的是如何切分数据的问题。
代码如下:
public class FibonacciSearch
{
public static int Demo(List<int> data, int key)
{
int low = ;
int high = data.Count - ; var myFibonacciSearch = new List<int>(new int[]);
myFibonacciSearch[] = ;
myFibonacciSearch[] = ;
for (int i = ; i < myFibonacciSearch.Count; ++i)
{
myFibonacciSearch[i] = myFibonacciSearch[i - ] + myFibonacciSearch[i - ];
} int relativePosition = ;
while (data.Count > myFibonacciSearch[relativePosition] - )
{
++relativePosition;
}
int[] temp = new int[myFibonacciSearch[relativePosition] - ];
data.CopyTo(temp); for (int i = data.Count; i < myFibonacciSearch[relativePosition] - ; ++i)
{
temp[i] = data[data.Count - ];
} while (low <= high)
{
int mid = low + myFibonacciSearch[relativePosition - ] - ;
if (key < temp[mid])
{
high = mid - ;
relativePosition -= ;
}
else if (key > temp[mid])
{
low = mid + ;
relativePosition -= ;
}
else
{
if (mid < data.Count)
{
return mid;
}
else
{
return data.Count - ;
}
}
}
return -;
}
}
FibonacciSearch
算法复杂度 O(logn)
插值查找
这个可能一般的小伙伴没有听过这个查找算法,其实这个算法也是定义了如何去找。
可以类比为查找字典的时候我们找X开头的单词总是会从后面开始找而找B开头的则会从头开始找。
插值查找就是定义了这么一个规则,通过公式 搜索键值 = left + parseInt( ( key - data[left] ) / ( data[right] - data[left] ) )*( right - left ) )
然后不停的切分,直到找到所需要的内容。
下面附上维基百科里提供的JS程序段,感兴趣的可以翻译为自己常用的语言。
var interpolationSearch = function(data, key){
var left = ;
var right = data.length - ;
var m = ;
while(left <= right){
var m = parseInt((right - left)*(key - data[left])/(data[right] - data[left])) + left;
if( m < left || m > right)
break;
if(key < data[m])
right = m - ;
else if(key > data[m])
left = m + ;
else
return m;
}
return -;
};
//執行
var data = getRandomData();
quickSort(data, , data.length-);
interpolationSearch(data, ); // (data, key)
interpolationSearch
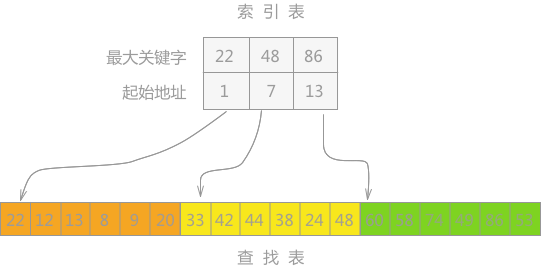
分块查找
顺序查找的增强版,有点桶排序的味道。
分开查找的要求就是分成N块每块内部可以无序但是块与块之间必须有序。
这个就可以利用cpu的并行并发进行查找加速。
如下图所示:
哈希查找
哈希对于各位开发小伙伴一定不陌生,哈希查找目的也很简单就是用空间来换时间。
1) 用给定的哈希函数构造哈希表;
2) 根据选择的冲突处理方法解决地址冲突;
3) 在哈希表的基础上执行哈希查找。
实用场景也很多:
1.文件查找
比如百度网盘秒传功能,适用诸如sha256等哈希算法就可以快速的找到文件是否存在(md5冲突率相对较高,不适合用做文件判重)
2.网络通信(微信消息算法)
数据中组装一个随机的int值然后再组装所需要的参数如id 组装成long,即后半截有序前半截随机,再使用基数对比法,只对比后部分。最终实现数据不重复的情况下查找id
用图解释就是
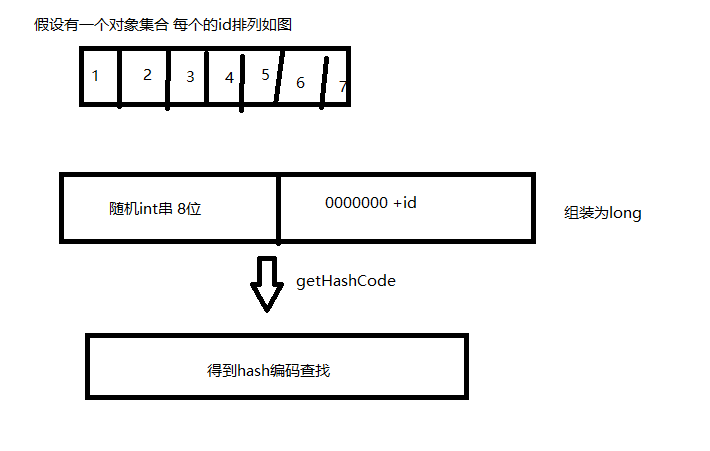
有点类似于雪花算法的感觉。
树查找
.net提供了教科书式的用法 感兴趣可以自行查看core源码中的SortedDictionary
二叉树的查询性能还行,平均查询是O(Logn),但是最坏的情况会退化为O(n),在二叉树的基础上,
又出来什么AVL,2-3-4,2-3(就是红黑,准确说 红黑树是2-3树的简单高效的实现)等等.
而B/B+平衡树其实是2-3查找树的扩展,在文件系统中好用. 所以树而言,只管用,你自己的实现根本跟不上大佬们的性能.
【摩天大楼平地起】基础篇 09 简述N种查找算法的更多相关文章
- iOS系列 基础篇 09 开关、滑块和分段控件
iOS系列 基础篇 09 开关.滑块和分段控件 目录: 案例说明 开关控件Switch 滑块控件Slider 分段控件Segmented Control 1. 案例说明 开关控件(Switch).滑块 ...
- Java多线程系列--“基础篇”09之 interrupt()和线程终止方式
概要 本章,会对线程的interrupt()中断和终止方式进行介绍.涉及到的内容包括:1. interrupt()说明2. 终止线程的方式2.1 终止处于“阻塞状态”的线程2.2 终止处于“运行状态” ...
- Java多线程系列 基础篇09 Object.wait/notifyJVM源码实现
转载 https://www.jianshu.com/p/f4454164c017 作者 占小狼 最简单的东西,往往包含了最复杂的实现,因为需要为上层的存在提供一个稳定的基础,Object作为java ...
- python 基础篇 09 函数初识
<<<<<<<<<<<<<<<------------------------------函 ...
- Python学习笔记——基础篇【第五周】——算法(4*4的2维数组和冒泡排序)、时间复杂度
目录 1.算法基础 2.冒泡排序 3.时间复杂度 (1)时间频度 (2)时间复杂度 4.指数时间 5.常数时间 6.对数时间 7.线性时间 1.算法基础 要求:生成一个4*4的2维数组并将其顺时针旋 ...
- 简述N种排序算法
排序算法概述 排序算法是程序员日常很常见的算法,基本上每天都会使用排序,在这里将进行一下总结. 排序算法大致可分为比较类排序和非比较类排序二种,其核心区别可以简单的理解为非比较类排序是对比较类排序之前 ...
- Java多线程系列--“基础篇”11之 生产消费者问题
概要 本章,会对“生产/消费者问题”进行讨论.涉及到的内容包括:1. 生产/消费者模型2. 生产/消费者实现 转载请注明出处:http://www.cnblogs.com/skywang12345/p ...
- Java多线程系列--“基础篇”10之 线程优先级和守护线程
概要 本章,会对守护线程和线程优先级进行介绍.涉及到的内容包括:1. 线程优先级的介绍2. 线程优先级的示例3. 守护线程的示例 转载请注明出处:http://www.cnblogs.com/skyw ...
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
随机推荐
- Python:扫描目录下的所有文件
扫描目录下的所有文件并返回文件的绝对路径 def fileListFunc(filePathList): fileList = [] for filePath in filePathList: for ...
- 性能分析之工具使用——cpu、io 、mem【工具分析】
nmon nmon 是一种在aix 与各种 Linux 操作系统上广泛使 用的监控与与分析工具,他主要记录以下内容: • cpu 占用率 • 内存使用情况 • 磁盘I/O 速度.传输和读写比率 • 文 ...
- IOC初始化销毁的2种实现方式
IOC初始化销毁的2种实现方式 1.bean内调用init-method 和destroy-method 2.通过注解实现@PostConstruct 和@PreDestroy ----------- ...
- spring给予XML配置的声明式事务
步骤: 1.添加aop.tx命名空间声明: 2.配置事务管理器: 3.配置增强: 4.配置aop 具体xml设置如下: <?xml version="1.0" encodin ...
- 吴裕雄--天生自然python学习笔记:Python3 命名空间和作用域
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的. 命名空间提供了在项目中避免名字冲突的一种方法.各个命名空间是独立的,没有任何关系的,所以一个 ...
- springMVC对静态资源访问的处理
在restful 风格下springMVC会进行如下配置 <servlet> <servlet-name>mvc</servlet-name> <servl ...
- JSP9个内置对象和3个常用指令
一.9个内置对象: 1.request对象客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应.2.response对象包含了响应客户请求的有关信息,但在JSP中很少 ...
- connect() failed (111: Connection refused) while connecting to upstream报错处理
新lnmp环境调试项目时,nginx报错如下: 解决: 发现php-fpm.conf是以套接字方式通信,而nginx是以端口方式通信,见下图: 将nginx.conf修改为如下,重新reload即可
- 【基础篇】hexo博客搭建教程
[基础篇]搭建hexo博客(一) 作者:Huanhao bilibili:Mrhuanhao 前言 你是否想拥有属于自己的博客?你是否无奈与自己不会写网站而烦恼? 不要担心,本系列教程将会实现你白嫖的 ...
- HTML标签学习总结(2)
点我:HTLM标签学习总结(1) 11. 在网页制作过程过中,可以把一些独立的逻辑部分划分出来,放在一个<div>标签中,这个<div>标签的作用就相当于一个容器. 语法: & ...