Storm之WordCount初探
刚接触Strom,记录下执行过程
1、pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>org.toda.demo</groupId>
<artifactId>demo</artifactId>
<version>1.0-SNAPSHOT</version> <name>demo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
<!-- <scope>provided</scope>-->
</dependency> <dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.9.3</version>
</dependency>
</dependencies> <build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
2、WordCountSpout.java文件
package org.toda.demo.wordcout; import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
//执行顺序:open() --> nextTuple() -->declareOutputFields()
public class WordCountSpout extends BaseRichSpout {
private Map map;
private TopologyContext context;
private SpoutOutputCollector collector; String text[]={
"你好 谢谢 再见",
"哈哈 再见 吃饭",
"再见 你好 睡觉",
"上班 谢谢 辛苦",
"开心"
};
Random random=new Random();
@Override
public void nextTuple() {
Values line = new Values(text[random.nextInt(text.length)]);
//发送tuple消息,并返回起发送任务的task的序列号集合
collector.emit(line);
Utils.sleep(1000);
System.err.println("splot----- emit------- "+line);
} @Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
//数据初始化
this.map=map;
this.context=context;
this.collector=collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义元组中变量结构的名字
declarer.declare(new Fields("newFields"));
}
}
3\WordCountBolt.java文件
package org.toda.demo.wordcout; import java.util.List;
import java.util.Map; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
//执行顺序: prepare() --> execute() --> declareOutputFields()
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector; @Override
public void execute(Tuple input) {
//随机获取单行数据,
//String line = input.getString(0);
//也可以用下面的代码通过field获取,这里0是返回这个String的0号位置
String line=input.getStringByField("newFields");
//切分字符串单词
String[] words = line.split(" ");
//向后发送tuple
for(String word : words){
List w=new Values(word);
collector.emit(w);
}
} @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
//数据初始化
this.collector=collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} }
4\WordFinalBolt.java文件
package org.toda.demo.wordcout; import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple; public class WordFinalBolt extends BaseRichBolt {
private OutputCollector collector;
Map<String, Integer> map=new HashMap<String,Integer>(); @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector){
this.collector=collector;
} @Override
public void execute(Tuple input) {
int count =1;
//获取切分后的每一个单词
String word = input.getStringByField("word");
if(map.containsKey(word)) {
count=(int) map.get(word)+1;
}
map.put(word, count);
//输出
System.err.println(word+"============="+count);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
} }
5、Test.java文件(main函数)
package org.toda.demo.wordcout; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields; public class Test { public static void main(String[] args) {
//创建一个拓扑
TopologyBuilder tb=new TopologyBuilder();
//拓扑设置 喷嘴以及个数
tb.setSpout("ws", new WordCountSpout());
//拓扑设置 Bolt以及个数,shuffleGrouping表示随机分组
tb.setBolt("wordcountbolt", new WordCountBolt(),3).shuffleGrouping("ws");
//fieldsGrouping表示按照字段分组,即是同一个单词只能发送给一个Bolt
tb.setBolt("wc", new WordFinalBolt(),3).fieldsGrouping("wordcountbolt",new Fields("word") );
//本地模式,测试
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordconut",new Config(), tb.createTopology());
}
}
总结:
从代码可看出,Spout是将数据源封装成Tuple,而Bolt主要是对Tuple进行逻辑处理,可以有多个Bolt执行,最后一个Bolt是最后所需数据。
执行过程:
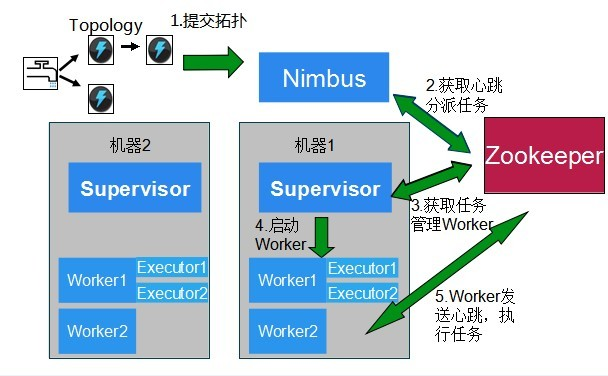
Storm之WordCount初探的更多相关文章
- 基于Storm的WordCount
Storm WordCount 工作过程 Storm 版本: 1.Spout 从外部数据源中读取数据,随机发送一个元组对象出去: 2.SplitBolt 接收 Spout 中输出的元组对象,将元组中的 ...
- Storm系列(三):创建Maven项目打包提交wordcount到Storm集群
在上一篇博客中,我们通过Storm.Net.Adapter创建了一个使用Csharp编写的Storm Topology - wordcount.本文将介绍如何编写Java端的程序以及如何发布到测试的S ...
- 3、SpringBoot 集成Storm wordcount
WordCountBolt public class WordCountBolt extends BaseBasicBolt { private Map<String,Integer> c ...
- STORM_0002_在做好的zookeeper集群上搭建storm的开发环境
参考文献http://www.cnblogs.com/panfeng412/archive/2012/11/30/how-to-install-and-deploy-storm-cluster.htm ...
- storm的数据源编程单元Spout学习整理
Spout呢,是Topology中数据流的源头,也是Storm针对数据源的编程单元.一般数据的来源,是通过外部数据源来读取数据项(Tuple),并读取的数据项传输至作业的其他组件.编程人员一般可通过O ...
- storm安装以及简单操作
storm的安装比较简单,下面以storm的单节点为例说明storm的安装步骤. 1.storm的下载 进入storm的官方网站http://storm.apache.org/,点击download按 ...
- Storm 运行例子
1.建立Java工程 使用idea,添加lib库,拷贝storm中lib到工程中 2.拷贝wordcount代码 下载src包,解压找到 apache-storm-0.9.4-src\apache-s ...
- Storm的并行度
在Storm集群中,运行Topolopy的实体有三个:工作进程,executor(线程),task(任务),下图可以形象的说明他们之间的关系. 工作进程 Storm集群中的一台机器会为一个或则多个To ...
- 三:Storm设计一个Topology用来统计单词的TopN的实例
Storm的单词统计设计 一:Storm的wordCount和Hadoop的wordCount实例对比
随机推荐
- 模块之-os模块
模块之-os模块 >>> import os >>> os.getcwd() #获取当前工作目录 'C:\\Users\\Administrator' >&g ...
- 你所不知的VIM强大功能
1. 可视化区块(Visual Block) (1)cd ~ 切换到自己的家目录(本范例中为root用户) (2)touch test1 test2 建立两个文件做演示(3)last > tes ...
- tensorflow 源码编译tensorflow 1.1.0到 tensorflow 2.0,ver:1.1.0rc1、1.4.0rc1、1.14.0-rc1、2.0.0b1
目录 tensorflow-build table 更多详细过程信息及下载: tensorflow-build tensorflow 源码编译,提升硬件加速,支持cpu加速指令,suport SSE4 ...
- osworkflow 入门基础
OSWorkFlow入门指南目的 这篇指导资料的目的是介绍OSWorkflow的所有概念,指导你如何使用它,并且保证你逐步理解OSWorkflow的关键内容. 本指导资料假定你已经部署OSWorkfl ...
- java8学习之Stream深度解析与源码实践
继续对流进行学习,首先先说明一下流的特点: 1.Collection提供了新的stream()方法. 2.流不存储,通过管道的方式获取值. 3.本质是函数式的,对流的操作会生成一个结果,不过并不会修改 ...
- 面试题:Dubbo中zookeeper做注册中心,如果注册中心集群全都挂掉,发布者和订阅者之间还能通信么?
1.[提供者]在[启动]时,向注册中心zk [注册]自己提供的服务. 2.[消费者]在[启动]时,向注册中心zk [订阅]自己所需的服务. 可以的,消费者在启动时,消费者会从zk拉取注册的生产者的 ...
- 使用pdo,使用pdo无法插入数据怎么办
如果你使用了最新版的XAMPP,那么你几乎不用改变php.ini的设置,就可以使用pdo but,插了一晚上,程序既不报错也不插入数据,真是气死人,后来发现是实例化pdo对象的时候没有指定字符集.所以 ...
- LightOJ-1027-A Dangerous Maze(概率)
链接: https://vjudge.net/problem/LightOJ-1027#author=634579757 题意: You are in a maze; seeing n doors i ...
- SIM800c收发短信及AT指令
一.sim800设备安装 淘宝搜索sim800,差不多就是这么个样子 购买之后,安装手机卡,卡的缺口向外插入,会有卡住的感觉,再按一下卡会弹出 安装usb转串口驱动(CH340),设备的指示灯先是快闪 ...
- 【leetcode】1234. Replace the Substring for Balanced String
题目如下: You are given a string containing only 4 kinds of characters 'Q', 'W', 'E' and 'R'. A string i ...