Text-CNN 文本分类
1.简介
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 (见参考[1]) 中提出. 是2014年的算法.
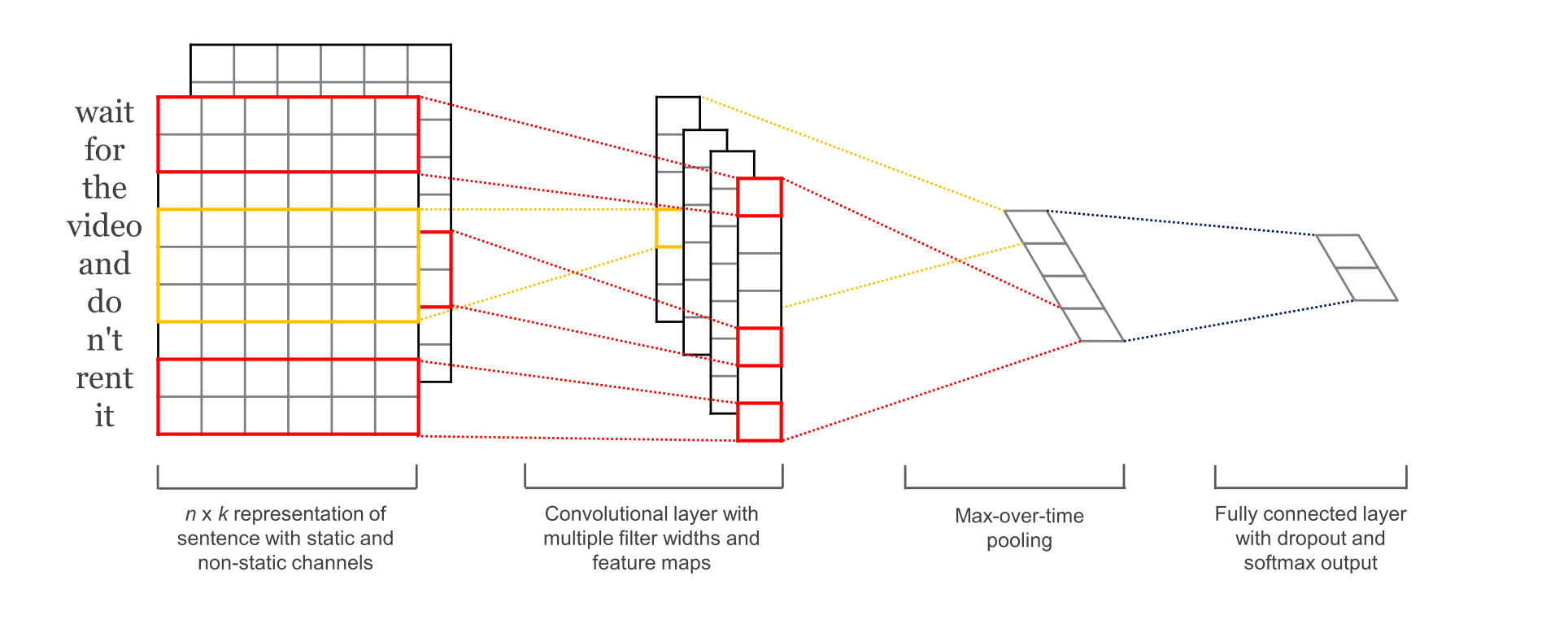
图1-1 参考[1] 中的论文配图
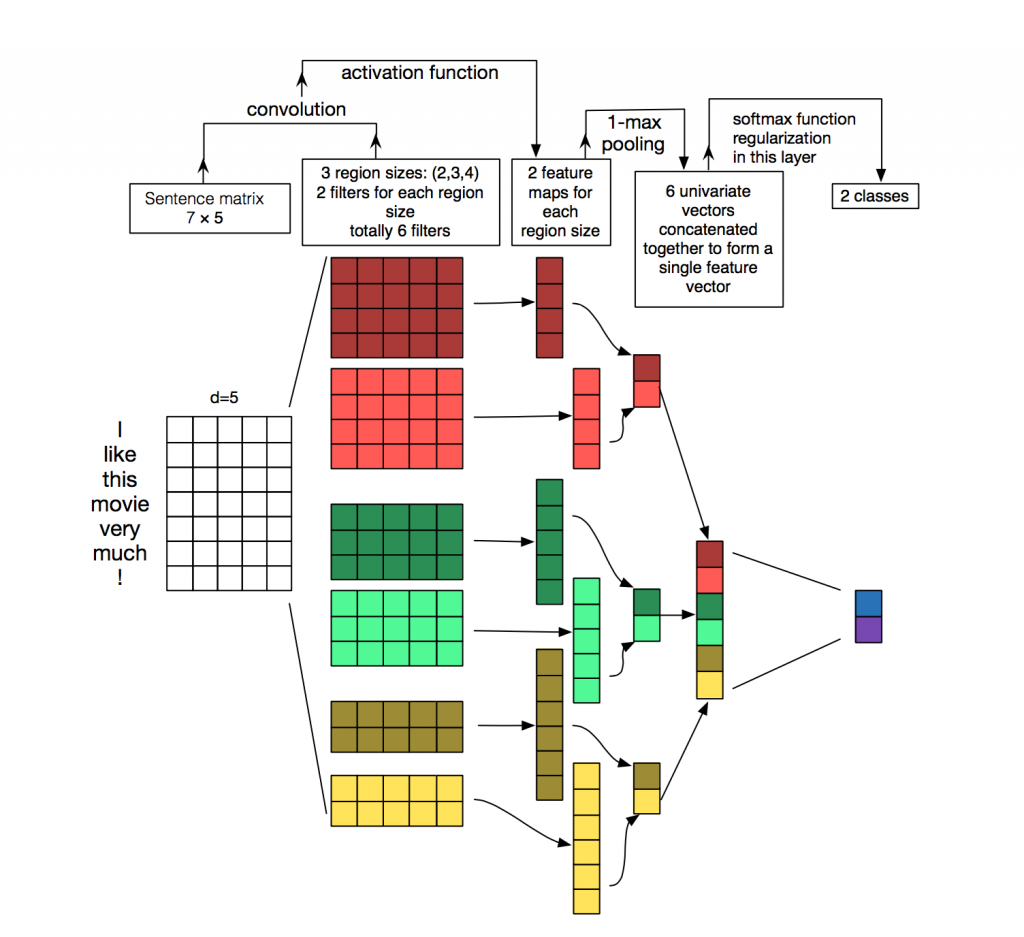
图1-2 网络盗图
合理性:
深度学习模型在计算机视觉与语音识别方面取得了卓越的成就. 在 NLP 也是可以的.
卷积具有局部特征提取的功能, 所以可用 CNN 来提取句子中类似 n-gram 的关键信息.
2.参数与超参数
- sequence_length
Q: 对于CNN, 输入与输出都是固定的,可每个句子长短不一, 怎么处理?
A: 需要做定长处理, 比如定为n, 超过的截断, 不足的补0. 注意补充的0对后面的结果没有影响,因为后面的max-pooling只会输出最大值,补零的项会被过滤掉. - num_classes
多分类, 分为几类. - vocabulary_size
语料库的词典大小, 记为|D|. - embedding_size
将词向量的维度, 由原始的 |D| 降维到 embedding_size. - filter_size_arr
多个不同size的filter.
3.Embedding Layer
通过一个隐藏层, 将 one-hot 编码的词 投影 到一个低维空间中.
本质上是特征提取器,在指定维度中编码语义特征. 这样, 语义相近的词, 它们的欧氏距离或余弦距离也比较近.
4.Convolution Layer
为不同尺寸的 filter 都建立一个卷积层. 所以会有多个 feature map.
图像是像素点组成的二维数据, 有时还会有RGB三个通道, 所以它们的卷积核至少是二维的.
从某种程度上讲, word is to text as pixel is to image, 所以这个卷积核的 size 与 stride 会有些不一样.
- xi
xi∈Rk
, 一个长度为n的句子中, 第 i 个词语的词向量, 维度为k.
- xi:j
xi:j=xi⊕xi+1⊕...⊕xj
表示在长度为n的句子中, 第 [i,j] 个词语的词向量的拼接.
- h
卷积核所围窗口中单词的个数, 卷积核的尺寸其实就是 hk
.
- w
w∈Rhk
, 卷积核的权重矩阵.
- ci
ci=f(w⋅xi:i+h−1+b)
, 卷积核在单词i位置上的输出. b∈RK
, 是 bias. f
是双曲正切之类的激活函数.
- c=[c1,c2,...,cn−h+1]
filter在句中单词上进行所有可能的滑动, 得到的 feature map
.
5.Max-Pooling Layer
max-pooling只会输出最大值, 对输入中的补0 做过滤.
6.SoftMax 分类 Layer
最后接一层全连接的 softmax 层,输出每个类别的概率。
7.小的变种
在 word representation 处理上会有一些变种.
- CNN-rand
设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整. - static
拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量. 这也算是迁移学习的一种思想. - non-static
pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调. - multiple channel
类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来搞.
一些结果表明,max-pooling 总是优于 average-pooling ,理想的 filter sizes 是重要的,但具体任务具体考量,而用不用正则化似乎在NLP任务中并没有很大的不同。
8. Text CNN 的tf实现
参见[4], [6]. 挺详细的。
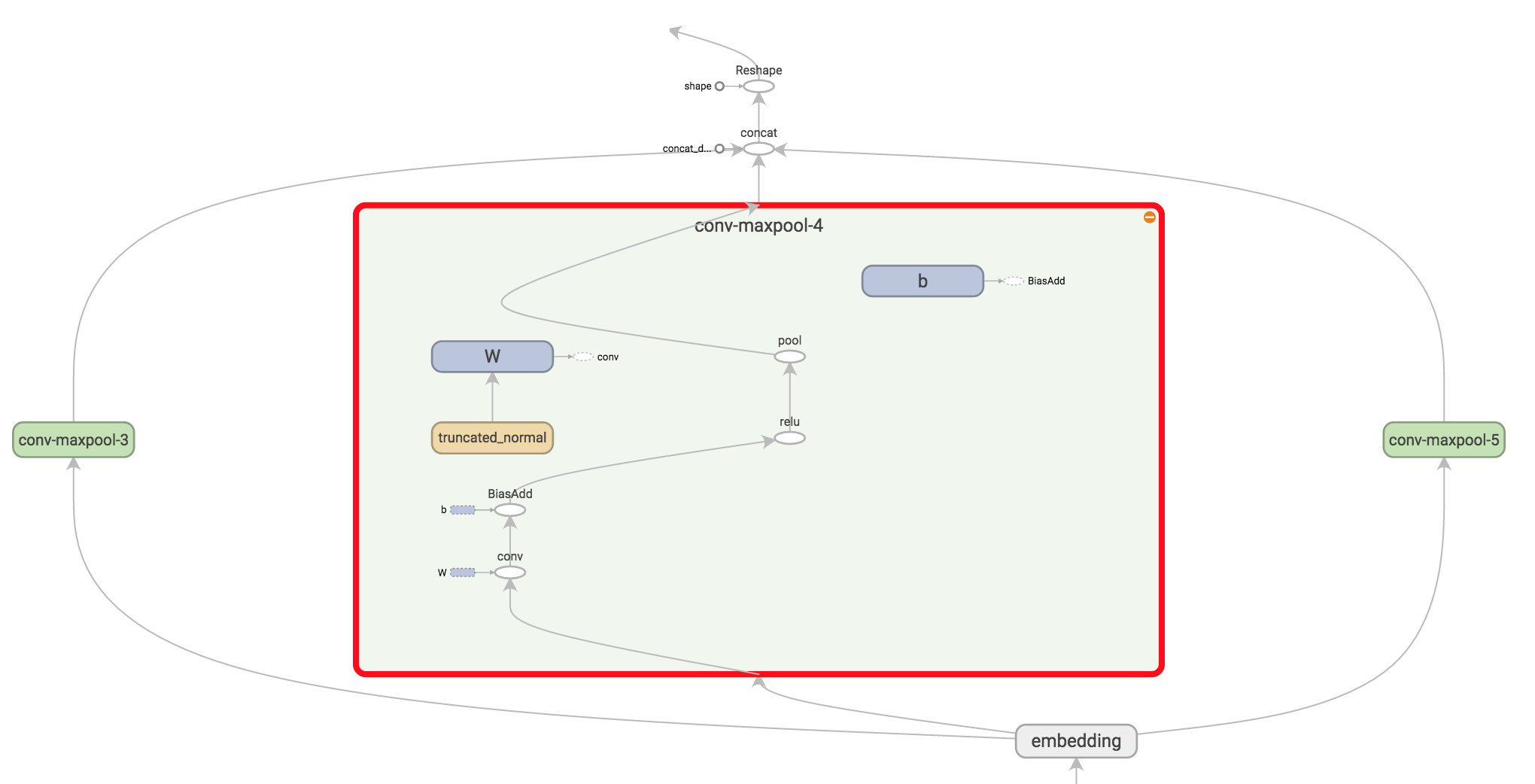
图 8-1 Text CNN 网络中的卷积与池化 结构
需要注意的细节有。 tf.nn.embedding_lookup() creates the actual embedding operation. The result of the embedding operation is a 3-dimensional tensor of shape [None, sequence_length, embedding_size].
TensorFlow’s convolutional conv2d operation expects a 4-dimensional tensor with dimensions corresponding to batch, width, height and channel. The result of our embedding doesn’t contain the channel dimension, so we add it manually, leaving us with a layer of shape [None, sequence_length, embedding_size, 1].
9. 与 LeNet 作比较
# LeNet5
conv1_weights = tf.get_variable(
"weight",
[CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
input_tensor,
conv1_weights,
strides=[1, 1, 1, 1],
padding='SAME')
tf.nn.max_pool(
relu1,
ksize = [1,POOL1_SIZE,POOL1_SIZE,1],
strides=[1,POOL1_SIZE,POOL1_SIZE,1],
padding="SAME")
#TextCNN
conv1_weights = tf.get_variable(
"weight",
[FILTER_SIZE, EMBEDDING_SIZE, 1, NUM_FILTERS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.nn.conv2d(
self.embedded_chars_expanded,
conv1_weights,
strides=[1, 1, 1, 1],
padding="VALID")
tf.nn.max_pool(
h,
ksize=[1, SEQUENCE_LENGTH - FILTER_SIZE + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID')先来比较卷积
Lenet是正方形的, 且每一层都只用了同一种尺寸的卷积核.
Text中, filter是矩形, 长度有好几种, 一般取 (2,3,4), 而宽度是定长的, 同word的embedding_size 相同. 每种尺寸都配有 NUM_FILTERS 个数目, 类比于Lenet中的output_depth. 所以得到的featuremap是长条状, 宽度为1.
因为是卷积, 所以stride每个维度都是1.
再说池化层.
Lenet的kernel是正方形, 一般也是2*2等, 所以会把卷积后的featurmap尺寸缩小一半.
TextCNN依旧是长方形, 将整个featuremap映射到一个点上. 一步到位, 只有一个池化层.
全连接层
都是多分类, 这一步的处理比较类似. 将池化后的矩阵 reshape为二维, 用 tf.nn.sparse_softmax_cross_entropy_with_logits() 计算损失.
10. TextCNN 论文中的网络结构
windows size 分别取 (3,4,5), 每个尺寸都会有100个filter.
3.1 Hyperparameters and Training
For all datasets we use: rectified linear units, filter
windows (h) of 3, 4, 5 with 100 feature maps each,
dropout rate (p) of 0.5, l2 constraint (s) of 3, and
mini-batch size of 50. These values were chosen
via a grid search on the SST-2 dev set.Text-CNN 文本分类的更多相关文章
- CNN 文本分类
谈到文本分类,就不得不谈谈CNN(Convolutional Neural Networks).这个经典的结构在文本分类中取得了不俗的结果,而运用在这里的卷积可以分为1d .2d甚至是3d的. 下面 ...
- CNN文本分类
CNN用于文本分类本就是一个不完美的解决方案,因为CNN要求输入都是一定长度的,而对于文本分类问题,文本序列是不定长的,RNN可以完美解决序列不定长问题, 因为RNN不要求输入是一定长度的.那么对于C ...
- pytorch -- CNN 文本分类 -- 《 Convolutional Neural Networks for Sentence Classification》
论文 < Convolutional Neural Networks for Sentence Classification>通过CNN实现了文本分类. 论文地址: 666666 模型图 ...
- CNN tensorflow text classification CNN文本分类的例子
from:http://deeplearning.lipingyang.org/tensorflow-examples-text/ TensorFlow examples (text-based) T ...
- CNN 文本分类模型优化经验——关键点:加卷积层和FC可以提高精度,在FC前加BN可以加快收敛,有时候可以提高精度,FC后加dropout,conv_1d的input维度加大可以提高精度,但是到256会出现OOM。
network = tflearn.input_data(shape=[None, max_len], name='input') network = tflearn.embedding(networ ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 文本分类需要CNN?No!fastText完美解决你的需求(后篇)
http://blog.csdn.net/weixin_36604953/article/details/78324834 想必通过前一篇的介绍,各位小主已经对word2vec以及CBOW和Skip- ...
- 文本分类需要CNN?No!fastText完美解决你的需求(前篇)
http://blog.csdn.net/weixin_36604953/article/details/78195462?locationNum=8&fps=1 文本分类需要CNN?No!f ...
随机推荐
- 【react】input输入框可输入的最好实现方式
使用的是refs.react中输入框不能直接定义value.输入框是可变的,react会提示报错.需要使用的inChange事件(输入框内容被改变时触发). 要定义输入框初始值,需要在componen ...
- github局部不同图片合并插件
用于解决游戏开发时,一套图里有局部地区图片不同其他地方相同,导致资源重复过大的问题 地址:https://github.com/Elringus/SpriteDicing
- 【VS开发】浅谈UDP(数据包长度,收包能力,丢包及进程结构选择)
UDP数据包长度 UDP数据包的理论长度 udp数据包的理论长度是多少,合适的udp数据包应该是多少呢?从TCP-IP详解卷一第11章的udp数据包的包头可以看出,udp的最大包长度是2^16-1的个 ...
- [总集] LOJ 分块1 – 9
目录 分块9题 出题人hzw的解析 数列分块入门 1 修改:区间加 查询:单点值查询 代码 数列分块入门 2 修改:区间加 查询:区间排名 代码 数列分块入门 6 修改:单点插入 查询:单点值 代码 ...
- P1550打井
这是USACO2008年的一道最小生成树题,感谢dzj老师那天教的图论. 要引渠让每一个村庄都可以接到水,然后从某一个村庄到另一个村庄修剪水道要花费w元,并且还要打井(至少一个)(而输入数据也包括了在 ...
- mybatis工作原理及实现
对数据库的连接 使用时就创建连接,不使用就立即释放,对数据库进行频繁连接开启和关闭,造成数据库的资源浪费,影响数据库的性能: 解决办法:使用数据库连接池,管理数据库的连接. 2 将sql语句硬编码到j ...
- 微信小程序里多出来的奇怪宽度
最近在看微信小程序相关的东西,写页面的时候,因为一直以Iphone6作为标准调试(微信官方建议以Iphone6调试),下面以实际的案例讲解以rpx会引发的问题 wxml: <view class ...
- node(koa2)跨域与获取cookie
欲做一个node 的网关服务,通过 cookie 做信息传递,选择框架 koa2,这里简单记录跨域处理以及 cookie 获取. 首先:解决跨域问题,使用 koa2-cros 来处理,跨域问题后端处理 ...
- ABAP中TAB分隔符的使用
在ABAP开发中,存在很多特殊字符,使用情况也不同,下面及时SAP中的TAB分隔符的使用案例: 46C以下的版本: DATA: gc_result(50) type c. constants: con ...
- Laravel 向公共模板赋值
开发过程中许多时候都会向公共模板赋值,比如顶部导航栏,页面底部等等,不可能在每个控制器中都赋值一遍. Laravel 中解决办法如下:修改 App\Providers\AppServiceProvid ...