namenode和datanode的高可用性和故障处理
一、Hadoop单点故障问题如何解决
Hadoop 1.0内核主要由两个分支组成:MapReduce和HDFS,众所周知,这两个系统的设计缺陷是单点故障,即MR的JobTracker和HDFS的NameNode两个核心服务均存在单点问题,该问题在很长时间内没有解决,这使得Hadoop在相当长时间内仅适合离线存储和离线计算。
Hadoop 2.0内核由三个分支组成,分别是HDFS、MapReduce和YARN,而Hadoop生态系统中的其他系统,比如HBase、Hive、Pig等,均是基于这三个系统开发的。
(1) HDFS:仿照google GFS实现的分布式存储系统,由NameNode和DataNode两种服务组成,其中NameNode是存储了元数据信息(fsimage)和操作日志(edits),由于它是唯一的,其可用性直接决定了整个存储系统的可用性;
(2)YARN:Hadoop 2.0中新引入的资源管理系统,它的引入使得Hadoop不再局限于MapReduce一类计算,而是支持多样化的计算框架。它由两类服务组成,分别是ResourceManager和NodeManager,其中,ResourceManager作为整个系统的唯一组件,存在单点故障问题;
(3)MapReduce:目前存在两种MapReduce实现,分别是可独立运行的MapReduce,它由两类服务组成,分别是JobTracker和TaskTraker,其中JobTracker存在单点故障问题,另一个是MapReduce On YARN,在这种实现中,每个作业独立使用一个作业跟踪器(ApplicationMaster),彼此之间不再相互影响,不存在单点故障问题。本文提到的单点故障实际上是第一种实现中JobTracker的单点故障。
Hadoop中的HDFS、MapReduce和YARN的单点故障解决方案架构是完全一致的,分为手动模式和自动模式,其中手动模式是指由管理员通过命令进行主备切换,这通常在服务升级时有用,自动模式可降低运维成本,但存在潜在危险。
在Hadoop HA中,主要由以下几个组件构成:
(1)MasterHADaemon:与Master服务运行在同一个进程中,可接收外部RPC命令,以控制Master服务的启动和停止;
(2)SharedStorage:共享存储系统,active master将信息写入共享存储系统,而standby master则读取该信息以保持与active master的同步,从而减少切换时间。常用的共享存储系统有zookeeper(被YARN HA采用)、NFS(被HDFS HA采用)、HDFS(被MapReduce HA采用)和类bookeeper系统(被HDFS HA采用)。
(3)ZKFailoverController:基于Zookeeper实现的切换控制器,主要由两个核心组件构成:ActiveStandbyElector和HealthMonitor,其中,ActiveStandbyElector负责与zookeeper集群交互,通过尝试获取全局锁,以判断所管理的master进入active还是standby状态;HealthMonitor负责监控各个活动master的状态,以根据它们状态进行状态切换。
(4)Zookeeper集群:核心功能通过维护一把全局锁控制整个集群有且仅有一个active master。当然,如果ShardStorge采用了zookeeper,则还会记录一些其他状态和运行时信息。
实现高可用性时,可能会出现的问题:
(1)脑裂(brain-split):脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和Slave误以为出现两个active master,最终使得整个集群处于混乱状态。解决脑裂问题,通常采用隔离(Fencing)机制,包括三个方面:
共享存储fencing:确保只有一个Master往共享存储中写数据。
客户端fencing:确保只有一个Master可以响应客户端的请求。
Slave fencing:确保只有一个Master可以向Slave下发命令。
Hadoop公共库中对外提供了两种fenching实现,分别是sshfence和shellfence(缺省实现),其中sshfence是指通过ssh登陆目标Master节点上,使用命令fuser将进程杀死(通过tcp端口号定位进程pid,该方法比jps命令更准确),shellfence是指执行一个用户事先定义的shell命令(脚本)完成隔离。
(2)切换对外透明:为了保证整个切换是对外透明的,Hadoop应保证所有客户端和Slave能自动重定向到新的active master上,这通常是通过若干次尝试连接旧master不成功后,再重新尝试链接新master完成的,整个过程有一定延迟。在新版本的Hadoop RPC中,用户可自行设置RPC客户端尝试机制、尝试次数和尝试超时时间等参数。
HA解决的难度取决于Master自身记录信息的多少和信息可重构性,如果记录的信息非常庞大且不可动态重构,比如NameNode,则需要一个可靠性与性能均很高的共享存储系统,而如果Master保存有很多信息,但绝大多数可通过Slave动态重构,则HA解决方法则容易得多,典型代表是MapReduce和YARN。从另外一个角度看,由于计算框架对信息丢失不是非常敏感,比如一个已经完成的任务信息丢失,只需重算即可获取,使得计算框架的HA设计难度远低于存储类系统。
datanode损坏如何恢复:
关闭处于dead状态节点的相关hadoop进程:
1、关闭datanode进程;sbin/hadoop-daemon.sh stop datanode2、关闭该节点yarn资源管理进程sbin/yarn-daemon.sh stop nodemanager
重启dead状态节点的相关hadoop进程(同样适用于动态新增节点启动):
1、重启回复datanode进程;sbin/hadoop-daemon.sh start datanode2、重启回复该节点yarn资源管理进程sbin/yarn-daemon.sh start nodemanager 3、使用jps命令查看重启进程情况
二、Hadoop的高可用性(从单点故障问题解决)
(1)高可用性架构图如下所示。
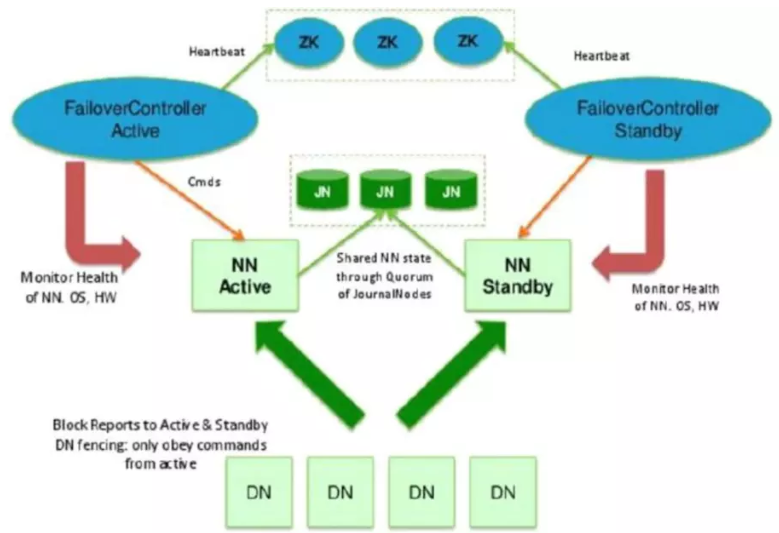
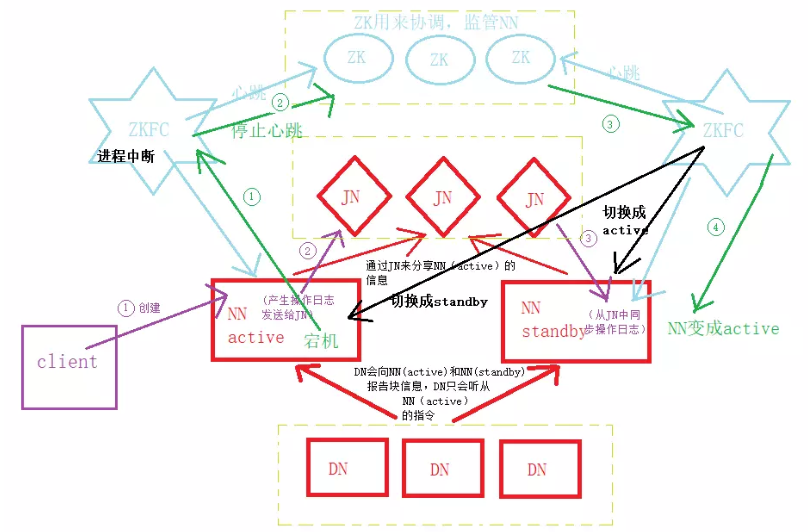
1、JN实现主备NN 间的数据共享(解决单点故障)
主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换,所有DataNode同时向两个NameNode汇报数据块信息(位置)
standby:备用namenode,完成了edits.log文件的合并产生新的fsimage,推送回ActiveNN
2、基于Zookeeper自动切换方案
ZooKeeper Failover Controller(zkfc):监控NameNode健康状态,并向Zookeeper注册NameNode,当主NameNode挂掉后,ZKFC(备)为NameNode竞争锁,获得ZKFC(备)锁的NameNode(备)变为active。
3、ZKFC的作用
健康检测:zkfc会周期性的向它监控的namenode(只有namenode才有zkfc进程,并且每个namenode各一个)发生健康探测命令,从而鉴定某个namenode是否处于正常工作状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于不健康的状态;
会话管理:如果namenode是健康的,zkfc机会保持在zookeeper中保持一个打开的会话,如果namenode是active状态的,那么zkfc还会在zookeeper中占有一个类型为短暂类型的znode,当这个namenode挂掉时,这个znode将会被删除,然后备用的namenode得到这把锁,升级为主的namenode,同时标记状态为active,当宕机的namenode,重新启动,他会再次注册zookeeper,发现已经有znode了,就自动变为standby状态,如此往复循环,保证高可靠性,但是目前仅支持最多配置两个namenode.
master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断哪个namenode为active状态。
namenode和datanode的高可用性和故障处理的更多相关文章
- hadoop中NameNode、DataNode和Client三者之间协作关系及通信方式介绍
<ignore_js_op> 1)NameNode.DataNode和Client NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间.集群 ...
- namenode和datanode 的namespaceID导致的问题
namenode和datanode 的namespaceID导致,datanode无法正常的启动,经过查资料,解决的办法就是更改datanode的VERSION之中的namespace namenod ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- Hadoop介绍-4.Hadoop中NameNode、DataNode、Secondary、NameNode、JobTracker TaskTracker
Hadoop是一个能够对大量数据进行分布式处理的软体框架,实现了Google的MapReduce编程模型和框架,能够把应用程式分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行.在MapR ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- namenode和datanode机制
转自:https://www.cnblogs.com/DarrenChan/p/6416043.html?utm_source=itdadao&utm_medium=referral 首先我们 ...
- 初识HDFS(10分钟了解HDFS、NameNode和DataNode)
概览 首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通 ...
- 什么是NameNode和DataNode?他们是如何协同工作的?
[学习笔记] 什么是NameNode和DataNode?他们是如何协同工作的? 马克-to-win @ 马克java社区:一个HDFS集群包含一个NameNode和若干的DataNode(start- ...
- 04 namenode和datanode
namenode元数据管理 1.什么是元数据? hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>) 2.元数据由谁负责管理? namenod ...
随机推荐
- kafka操作命令
kafka启动 bin/kafka-server-start.sh -daemon config/server.properties 创建topic bin/kafka-topics.sh -zook ...
- 【flask】项目集成Sentry收集线上错误日志
flask集成sentry分为4个步骤: 首先在sentry官网注册1个账号 然后创建1个新的项目,这里我选择的是flask,这会得到一些关于sdk的使用说明 接下来创建一个简单的flask项目使用s ...
- Delphi XE2 之 FireMonkey 入门(36) - 控件基础: TForm
Delphi XE2 之 FireMonkey 入门(36) - 控件基础: TForm 当我第一次读取 Form1.StyleLookup 并期待出现 "formstyle" 时 ...
- Delphi DbgridEh实现鼠标拖动选中列,并使复选框选中
1.先设置表格列的属性 procedure TForm_TaskToDW.InitGrid;var MyCol: TColumnEh;begin with DBGridEh_Task do be ...
- 以非root身份安装Python的Module或者Package以及pip安装指定路径
因为要远程访问公司的服务器,没有sudo的权限,所以在安装python的一些包的时候就不能安去默认路径了(比如以/usr/local/lib/为prefix的路径). 一般来讲用easy_instal ...
- appium常见问题01_android筛选下拉框无法定位问题
近期用appium做android自动化的过程中,遇到一种筛选下拉框,神奇的是,定位工具定位怎样都定位不到. 首先尝试用uiaotomator工具定位,无法定位到下拉框元素,只能定位到底层元素: 询问 ...
- R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN
最近在看 Mask R-CNN, 这个分割算法是基于 Faster R-CNN 的,决定看一下这个 R-CNN 系列论文,好好理一下 R-CNN 2014 1. 论文 Rich feature hie ...
- (一)VS2015下配置OpenGL
刚开始用OpenGL,一开始不太明白配置库的原理,在VS2015下耗费了大量时间.这里将配置过程做个笔记,以供日后查看.配置过程中,需要下载cmake构建工具以及glew和glfw库. 下载地址为: ...
- MySQL-快速入门(11)用户管理
1.权限表 存储用户权限信息表主要有:user.db.host.tables_priv.columns_priv.procs_priv. 1>user表: 记录允许连接到服务器的账号信息,里面的 ...
- Zend_Cache的使用
一.Zend_Cache快速浏览 Zend_Cache 提供了一个缓存任何数据的一般方法. 在Zend Framework中缓存由前端操作,同时通过后端适配器(File, Sqlite, Memcac ...