[深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)
一、visdom可视化工具
安装:pip install visdom
启动:命令行直接运行visdom

打开WEB:在浏览器使用http://localhost:8097打开visdom界面
二、使用visdom
# 导入Visdom类
from visdom import Visdom
# 定义一个env叫Mnist的board,如果不指定,则默认归于main
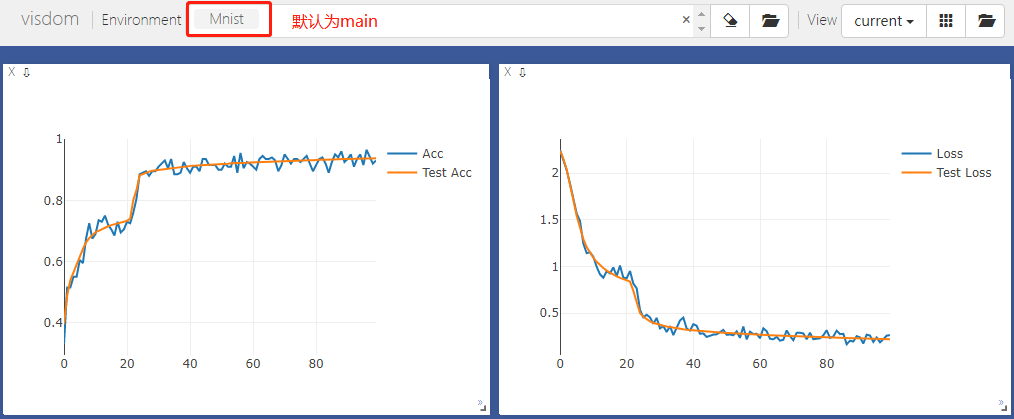
viz = Visdom(env='Mnist') # 在window Accuracy中画train acc和test acc,x坐标都是epoch
viz.line(Y=np.column_stack((acc, test_acc)),
X=np.column_stack((epoch, epoch)),
win='Accuracy',
update='append',
opts=dict(markers=False, legend=['Acc', 'Test Acc']))
# 在window Loss中画train loss和test loss,x坐标都是epoch
viz.line(Y=np.column_stack((loss.cpu().item(), test_loss.cpu().item())),
X=np.column_stack((epoch, epoch)),
win='Loss',
update='append',
opts=dict(markers=False, legend=['Loss', 'Test Loss']))
三、使用正则化
正则化也叫权重衰减(Weight Decay)
L1和L2正则化可以参考:https://blog.csdn.net/red_stone1/article/details/80755144
在代码中,我们只需要在优化器中使用weight_decay参数就可以启用L2正则化
# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
由于在Pytorch中没有纳入L1正则化,我们可以通过手工实现:
# 正则化超参数lambda
lambd = 0.01
# 所有参数的绝对值的和
regularization_loss = 0 for param in model.parameters():
regularization_loss += torch.sum(torch.abs(param)) # 自己手动在loss函数后添加L1正则项 lambda * sum(abs)
loss = F.cross_entropy(z, target) + lambd * regularization_loss
optimizer.zero_grad()
loss.backward()
四、使用Momentum动量
使用Momentum,即在使用SGD时指定momentum参数,如果不指定,默认为0,即不开启动量优化模式。
# 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01)
使用Adam时,由于Adam包含了Monmentum,所以他自己指定了Momentum参数的大小,无需我们指定。
五、学习率衰减 Learning rate decay

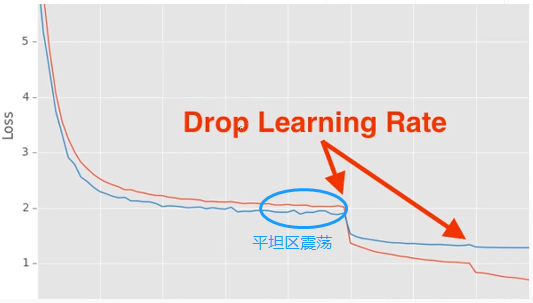
当学习率太小时,梯度下降很慢。当学习率太大时,可以在某个狭窄区间震荡,难以收敛。
学习率衰减就是为了解决学习率多大这种情况。
当我们在训练一个模型时,发现Loss在某个时间不发生变化(在一个平坦区),则我们要考虑是否是在一个狭窄区间震荡,导致的难以收敛。
我们在pytorch中可以使用ReducelROnPlateau(optimizer,'min')来监控loss的值:
from torch.optim.lr_scheduler import ReduceLROnPlateau # 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01) # 使用一个高原监控器,将optimizer交给他管理,LR衰减参数默认0.1即一次缩小10倍,patience是监控10次loss看是否变化
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10) # 后面的optimizer.step()使用scheduler.step(loss)来代替,每次step都会监控一下loss
# 当loss在10次(可以设置)都未变化,则会使LR衰减一定的比例
另外,除了上述使用ReducelROnPlateau,还可以使用更为粗暴的StepLR函数,我们可以直接指定在多少step后下降一次LR的值:
from torch.optim.lr_scheduler import StepLR # 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01) # 使用StepLR,指定step_size即每多少步衰减一次,gamma为衰减率,0.1代表除以10
scheduler = StepLR(optimizer, step_size = 10000, gamma=0.1) # 后面的optimizer.step()使用scheduler.step()
六、在全连接层使用batchnorm
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z' import torch
from visdom import Visdom
import numpy as np import torch.nn.functional as F
from torch.nn import Module, Sequential, Linear, LeakyReLU, BatchNorm1d
from torchvision import datasets, transforms
from torch.utils.data import DataLoader batch_size = 200
learning_rate = 0.001
epochs = 100 train_data = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])) test_data = datasets.MNIST('../data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])) train_db, val_db = torch.utils.data.random_split(train_data, [50000, 10000]) train_loader = DataLoader(train_db,
batch_size=100, shuffle=True)
val_loader = DataLoader(val_db,
batch_size=10000, shuffle=True)
test_loader = DataLoader(test_data,
batch_size=10000, shuffle=True) # 网络结构
class MLP(Module):
def __init__(self):
super(MLP, self).__init__() self.model = Sequential(
Linear(784, 200),
#===================== BN-start ======================
# 这里对第一层全连接层使用BN1d,在多个样本上对每一个神经元做归一化
BatchNorm1d(200, eps=1e-8),
# ===================== BN-end =======================
LeakyReLU(inplace=True),
Linear(200, 200),
#===================== BN-start ======================
# 这里对第二层全连接层使用BN1d,在多个样本上对每一个神经元做归一化
BatchNorm1d(200, eps=1e-8),
# ===================== BN-end =======================
LeakyReLU(inplace=True),
Linear(200, 10),
LeakyReLU(inplace=True)
) def forward(self, x):
x = self.model(x)
return x # 定义一个env叫Mnist的board,如果不指定,则默认归于main
viz = Visdom(env='TestBN') # 定义GPU设备
device = torch.device('cuda')
# model放到GPU
net = MLP().to(device) # 选择一个优化器,指定需要优化的参数,学习率,以及正则化参数,是否使用momentum
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.01) for idx, (val_data, val_target) in enumerate(val_loader):
val_data = val_data.view(-1, 28 * 28)
val_data, val_target = val_data.to(device), val_target.to(device) for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader):
# data转换维度为[200,784],target的维度为[200]
data = data.view(-1, 28 * 28)
# 将data和target放到GPU
data, target = data.to(device), target.to(device)
# data为输入,net()直接执行forward
# 跑一次网络,得到z,维度为[200,10],200是batch_size,10是类别
# 由于net在GPU,data也在GPU,计算出的z就在GPU
# 调用net(data)的时候相当于调用Module类的__call__方法
z = net(data).to(device) # 将loss放到GPU
loss = F.cross_entropy(z, target).to(device)
# 每次迭代前将梯度置0
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 相当于执行w = w - dw,也就是更新权值
optimizer.step() ### 每一轮epoch,以下代码是使用分割出的val dataset来做测试
# 先计算在train dataset上的准确率
eq_mat = torch.eq(z.argmax(dim=1), target)
acc = torch.sum(eq_mat).float().item() / eq_mat.size()[0]
print('Loss:', loss)
print('Accuracy:', acc) # 用val跑一遍网络,并计算在val dataset上的准确率
# ===================== BN-start =====================
# 跑网络之前,先将BN层设置为validation模式
# BN层会自动使用在训练时累计的running_mean和running_var
net.eval()
#net.model[1].eval()
#net.model[4].eval()
# ===================== BN-end ======================= val_z = net(val_data).to(device)
val_loss = F.cross_entropy(val_z, val_target).to(device)
val_eq_mat = torch.eq(val_z.argmax(dim=1), val_target)
val_acc = torch.sum(val_eq_mat).float().item() / val_eq_mat.size()[0]
print('Val Loss:', val_loss)
print('Val Accuracy:', val_acc) # 将loss和acc画到visdom中
viz.line(Y=np.column_stack((acc, val_acc)),
X=np.column_stack((epoch, epoch)),
win='Accuracy',
update='append',
opts=dict(markers=False, legend=['Acc', 'Val Acc']))
# 将val loss和val acc画到visdom中
viz.line(Y=np.column_stack((loss.cpu().item(), val_loss.cpu().item())),
X=np.column_stack((epoch, epoch)),
win='Loss',
update='append',
opts=dict(markers=False, legend=['Loss', 'Val Loss']))
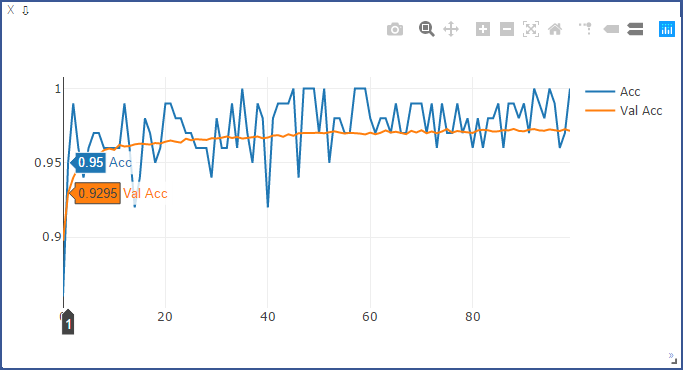
使用BN时的ACC和LOSS:

未使用BN时的ACC和LOSS:

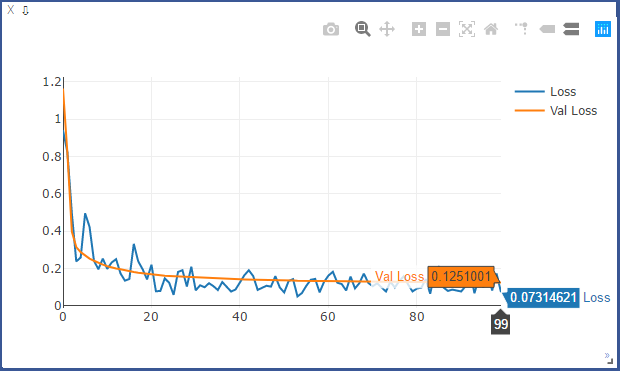
从上述结果可以看出,使用BN后,收敛速度变快。
[深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)的更多相关文章
- [深度学习] Pytorch学习(一)—— torch tensor
[深度学习] Pytorch学习(一)-- torch tensor 学习笔记 . 记录 分享 . 学习的代码环境:python3.6 torch1.3 vscode+jupyter扩展 #%% im ...
- [深度学习] pytorch学习笔记(2)(梯度、梯度下降、凸函数、鞍点、激活函数、Loss函数、交叉熵、Mnist分类实现、GPU)
一.梯度 导数是对某个自变量求导,得到一个标量. 偏微分是在多元函数中对某一个自变量求偏导(将其他自变量看成常数). 梯度指对所有自变量分别求偏导,然后组合成一个向量,所以梯度是向量,有方向和大小. ...
- [深度学习] pytorch学习笔记(4)(Module类、实现Flatten类、Module类作用、数据增强)
一.继承nn.Module类并自定义层 我们要利用pytorch提供的很多便利的方法,则需要将很多自定义操作封装成nn.Module类. 首先,简单实现一个Mylinear类: from torch ...
- [深度学习] pytorch学习笔记(1)(数据类型、基础使用、自动求导、矩阵操作、维度变换、广播、拼接拆分、基本运算、范数、argmax、矩阵比较、where、gather)
一.Pytorch安装 安装cuda和cudnn,例如cuda10,cudnn7.5 官网下载torch:https://pytorch.org/ 选择下载相应版本的torch 和torchvisio ...
- [深度学习] Pytorch学习(二)—— torch.nn 实践:训练分类器(含多GPU训练CPU加载预测的使用方法)
Learn From: Pytroch 官方Tutorials Pytorch 官方文档 环境:python3.6 CUDA10 pytorch1.3 vscode+jupyter扩展 #%% #%% ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- pytorch visdom可视化工具学习—1—详细使用-1—基本使用函数
使用教程,参考: https://github.com/facebookresearch/visdom https://www.pytorchtutorial.com/using-visdom-for ...
- Deep Learning(深度学习)学习笔记整理系列之(三)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- CS231n 斯坦福深度视觉识别课 学习笔记(完结)
课程地址 第1章 CS231n课程介绍 ---1.1 计算机视觉概述 这门课的主要内容是计算机视觉.它是一门需要涉及很多其他科目知识的学科. 视觉数据占据了互联网的绝大多数,但是它们很难利用. --- ...
随机推荐
- [Python3] 034 函数式编程 匿名函数
目录 函数式编程 Functional Programming 1. 简介 2. 函数 3. 匿名函数 3.1 lambda 表达式也称"匿名函数" 3.2 lambda 表达式的 ...
- Centos8 重启网卡方法
问题情况: 1.虚机centos8 修改为静态ip后,由于网卡网段变更,无法上网 2.最小化安装,没有ifconfig 3.firewalld,selinux关闭 4.ping 不通物理机 根本原因: ...
- 从入门到自闭之Python时间模块
time模块:import time time.time():时间戳,是一个浮点数,按秒来计算 time.sleep():睡眠,程序暂停多少秒执行 python中时间日期格式化符号: 必背 %y 两位 ...
- python-day40(正式学习)
目录 线程队列 1 2 3 线程定时器 进程池和线程池 线程队列 1 import queue q=queue.Queue() q.put('123') q.put('456') q.put('789 ...
- redis 学习(5)-- 列表类型
redis 学习(5)-- 列表类型 列表特点 有序.可以重复.左右两边插入弹出 索引相关知识 索引从左往右,从0开始逐个增大 0 1 2 3 4 5 索引从右往左,从-1开始逐个减小 -6 -5 - ...
- sql server select和set赋值的区别
--SQL Server中对已经定义的变量赋值的方式用两种,分别是 SET 和 SELECT --当表达式返回一个值并对一个变量进行赋值时,推荐使用 SET 方法 (1)SELECT可以在一条语句里对 ...
- nginx配置详解和原理
1.nginx的配置文件 nginx 配置文件的整体结构 user nobody nobody; # 指定Nginx Worker进程运行用户以及用户组,默认由nobody账号运行,nobody 是系 ...
- 优秀java博客
https://www.jianshu.com/p/efb58b7115bf?utm_source=tuicool https://www.nowcoder.com/discuss/110317 ht ...
- 12 Scrapy框架的日志等级和请求传参
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- vue路由公用
大体思路,一个页面,多个按钮,点击按钮后都跳转到一个路由:通过父亲传的值是什么,来决定跳那个路由:ajax数据也是通过判断来决定拉那个数据 路由: export default { routes: [ ...