机器学习7-模型保存&无监督学习
模型保存和加载
sklearn模型的保存和加载API
- from sklearn.externals import joblib
- 保存:joblib.dump(rf, 'test.pkl')
- 加载:estimator = joblib.load('test.pkl')
线性回归的模型保存加载案例
def linear3():
"""
岭回归的优化方法对波士顿房价预测
"""
#获取数据
boston=load_boston()
#划分数据集
x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,random_state=22)
#标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#预估器
# estimator=Ridge(alpha=0.0001, max_iter=100000)
# estimator.fit(x_train,y_train) #保存模型
# joblib.dump(estimator,"my_ridge.pkl") #加载模型
estimator=joblib.load("my_ridge.pkl") #得出模型
print("岭回归-权重系数为:\n",estimator.coef_)
print("岭回归-偏置为:\n",estimator.intercept_ ) #模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方差误差:\n", error)
return None if __name__ == '__main__':
# linear1()
# linear2()
linear3()
保存:保存训练完结束的模型
加载:加载已有的模型,去进行预测结果和之前的模型一样
无监督学习-K-means算法
K-means原理
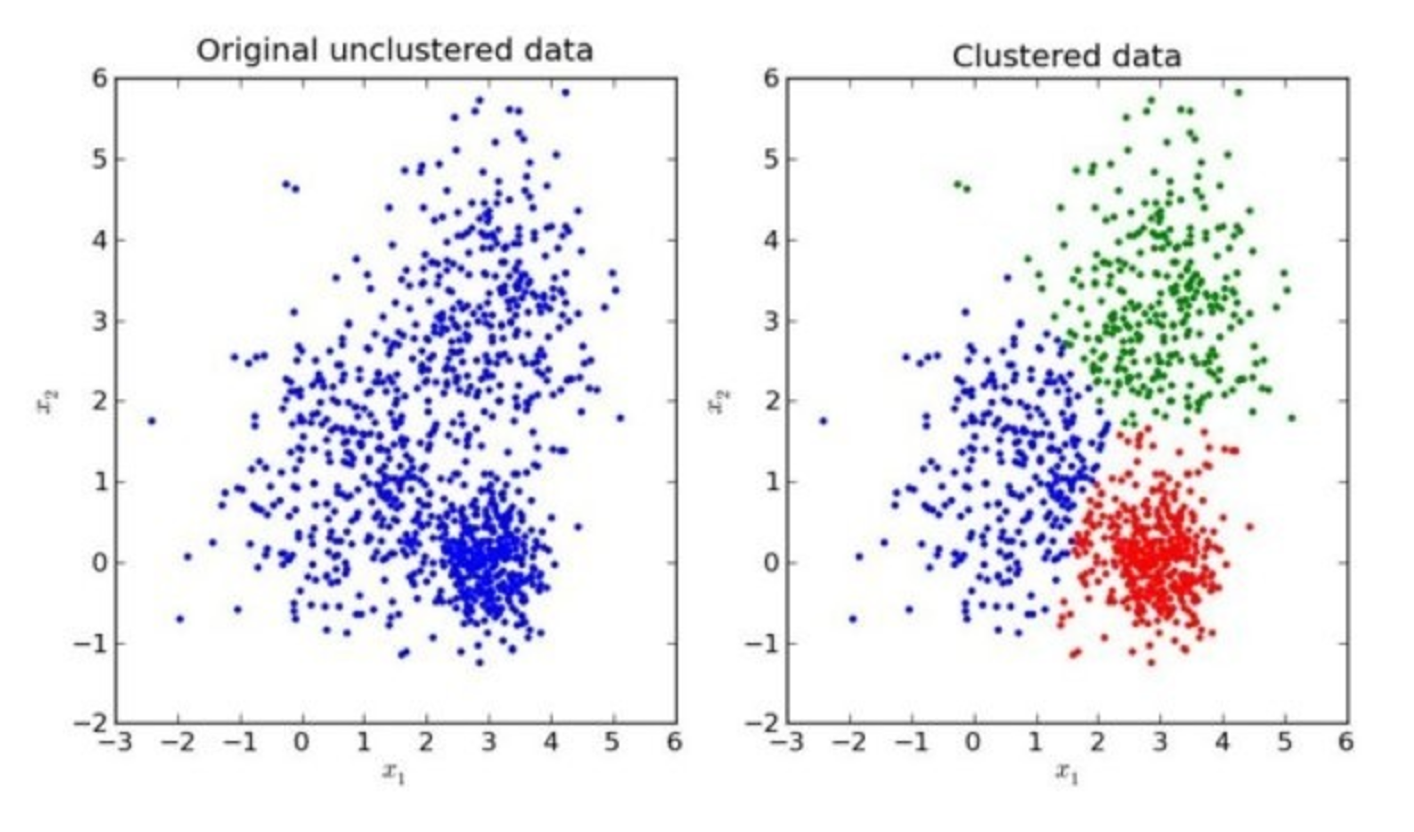
我们先来看一下一个K-means的聚类效果图
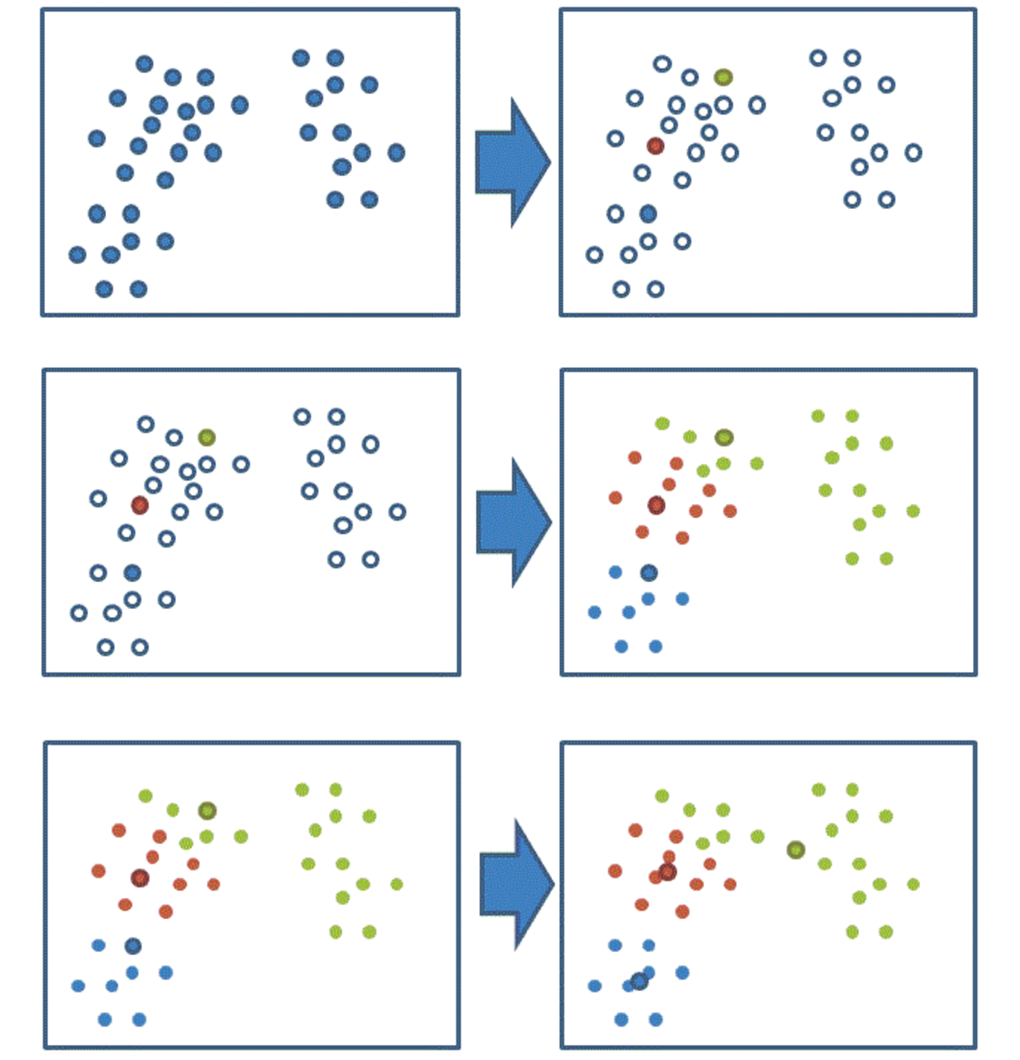
K-means聚类步骤
- 随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
我们以一张图来解释效果
K-meansAPI
- sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- k-means聚类
- n_clusters:开始的聚类中心数量
- init:初始化方法,默认为'k-means ++’
- labels_:默认标记的类型,可以和真实值比较(不是值比较)
案例:k-means对Instacart Market用户聚类
如何评估聚类的效果?
Kmeans性能评估指标
轮廓系数
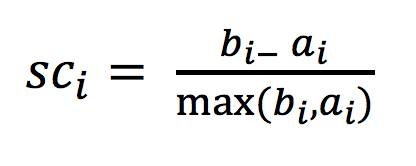
轮廓系数值分析
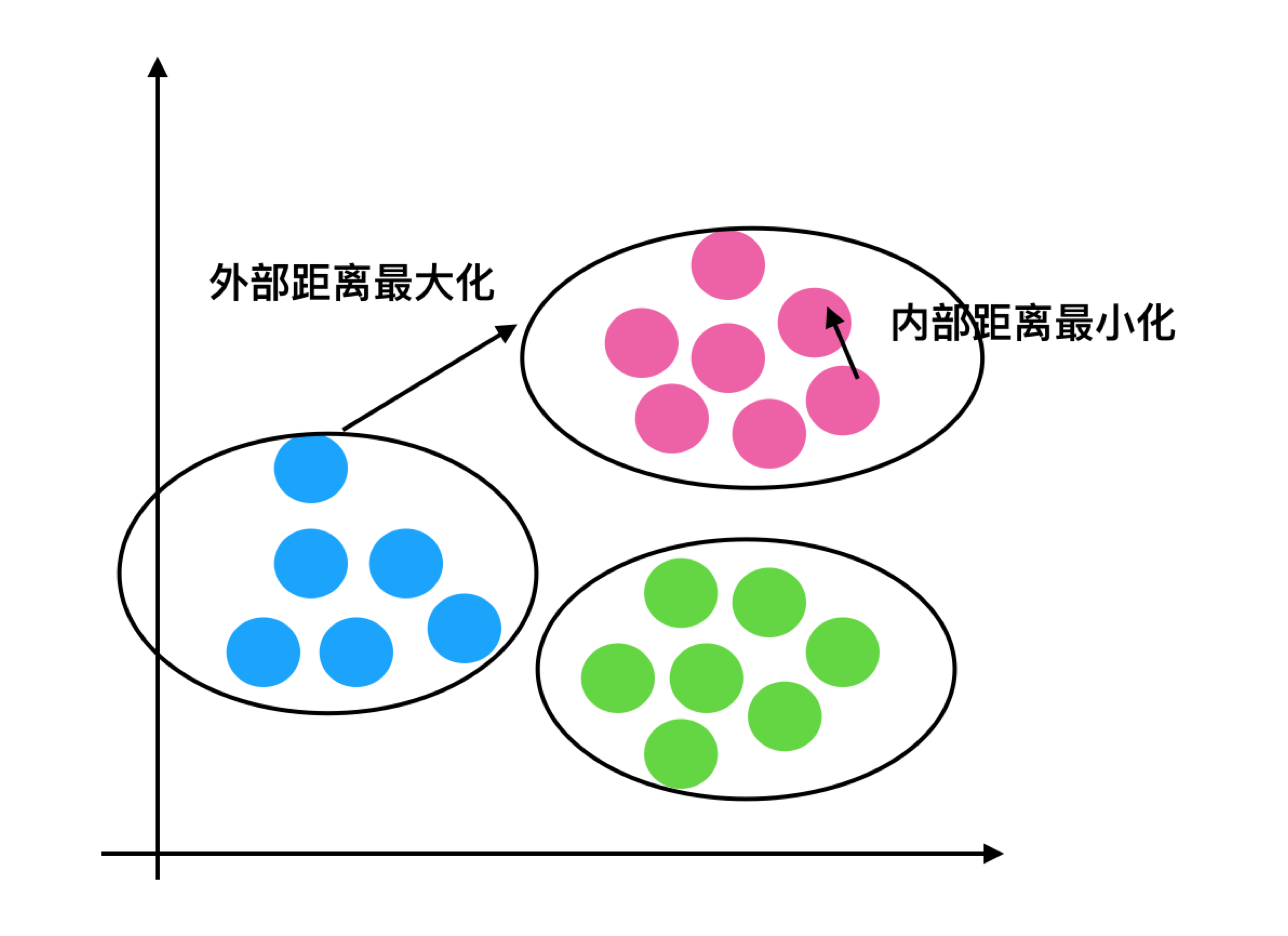
分析过程(我们以一个蓝1点为例)
1、计算出蓝1离本身族群所有点的距离的平均值a_i
2、蓝1到其它两个族群的距离计算出平均值红平均,绿平均,取最小的那个距离作为b_i
- 根据公式:极端值考虑:如果b_i >>a_i: 那么公式结果趋近于1;如果a_i>>>b_i: 那么公式结果趋近于-1
结论
如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
轮廓系数API
- sklearn.metrics.silhouette_score(X, labels)
- 计算所有样本的平均轮廓系数
- X:特征值
- labels:被聚类标记的目标值
案例-聚类评估

K-means总结
- 特点分析:采用迭代式算法,直观易懂并且非常实用
- 缺点:容易收敛到局部最优解(多次聚类)
回归与聚类整体算法总结
机器学习7-模型保存&无监督学习的更多相关文章
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- 深度|OpenAI 首批研究成果聚焦无监督学习,生成模型如何高效的理解世界(附论文)
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载,原文. 选自 Open AI 作者:ANDREJ KARPATHY, PIETER ABBEEL, GREG BRO ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- 【机器学习基础】无监督学习(1)——PCA
前面对半监督学习部分作了简单的介绍,这里开始了解有关无监督学习的部分,无监督学习内容稍微较多,本节主要介绍无监督学习中的PCA降维的基本原理和实现. PCA 0.无监督学习简介 相较于有监督学习和半监 ...
- 【机器学习】从分类问题区别机器学习类型 与 初步介绍无监督学习算法 PAC
如果要对硬币进行分类,我们对硬币根据不同的尺寸重量来告诉机器它是多少面值的硬币 这种对应的机器学习即使监督学习,那么如果我们不告诉机器这是多少面额的硬币,只有尺寸和重量,这时候让机器进行分类,希望机器 ...
- Python机器学习入门(1)之导学+无监督学习
Python Scikit-learn *一组简单有效的工具集 *依赖Python的NumPy,SciPy和matplotlib库 *开源 可复用 sklearn库的安装 DOS窗口中输入 pip i ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- Coursera机器学习笔记(一) - 监督学习vs无监督学习
转载 http://daniellaah.github.io/2016/Machine-Learning-Andrew-Ng-My-Notes-Week-1-Introduction.html 一. ...
随机推荐
- RabbiMQ重新安装会遇到的错误-SpiritMark
这里只做安装过程中遇到错误的介绍,不喜勿喷,如果对您有帮助右上角关注一下,是对我最大的肯定 重新安装的注意事项: 先卸载RabbitMQ,后卸载Erlang RabbitMQ卸载,选择uninstal ...
- JavaScript之经典面试题
1.作用域经典面试题 var num = 123; // f1函数写好了,作用域就定下来了,也就是作用域链定下来了 // f1函数作用域链: f1函数作用域 ==> 全局作用域 function ...
- kickstart+pxe部署
------------恢复内容开始------------ kickstart 通过网络安装系统 ----pxe kickstart,cobbler pex 预启动执行环境 通过网络接口启动计算机, ...
- 十大经典排序算法最强总结(含Java、Python码实现)
引言 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法.排序算法在很多领域得到相当地重视,尤其是在大量数据的处理方面 ...
- 十个最常用的JVM 配置参数
1.-Xms:初始堆大小.只要启动,就占用的堆大小. 2.-Xmx:最大堆大小.java.lang.OutOfMemoryError:Java heap这个错误可以通过配置-Xms和-Xmx参数来设置 ...
- MM-合作伙伴确定过程
第一步:物料管理---采购---合作伙伴确定---合作伙伴角色---定义合作伙伴角色. 第二步:物料管理---采购---合作伙伴确定---合作伙伴角色---定义每个科目组适合的合作伙伴角色. 第三步: ...
- 腾讯云联合多家生态伙伴,重磅开源 SuperEdge 边缘容器项目
在2020年12月19-20日腾讯 Techo Park 开发者大会上,腾讯云联合英特尔.VMware 威睿.虎牙.寒武纪.美团.首都在线,共同发布 SuperEdge 边缘容器开源项目. Super ...
- springboot文件上传问题记录
最近做项目需要开发一个通过excel表格导入数据的功能,上传接口写好调试的时候遇到几个问题,记录一下. 报错1: 15:50:57.586 [[1;33mhttp-nio-8763-exec-8 [0 ...
- Class的一些使用技巧?
1.forName和newInstance结合起来使用,可以根据存储在字符串中的类名创建对象.例如 Object obj = Class.forName(s).newInstance(); 2.虚拟机 ...
- 数据湖框架选型很纠结?一文了解Apache Hudi核心优势
英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/ Apache Hudi使用索引来定位更删操作所在的文件组.对于Copy-On-W ...