Apache Flink 如何正确处理实时计算场景中的乱序数据
一、流式计算的未来
在谷歌发表了 GFS、BigTable、Google MapReduce 三篇论文后,大数据技术真正有了第一次飞跃,Hadoop 生态系统逐渐发展起来。
Hadoop 在处理大批量数据时表现非常好,主要有以下特点:
1、计算开始之前,数据必须提前准备好,然后才可以开始计算;
2、当大量数据计算完成之后,会输出最后计算结果,完成计算;
3、时效性比较低,不适用于实时计算;
而随着实时推荐、风控等业务的发展,数据处理时延要求越来越高,实时性要求也越来越高,Flink 开始在社区崭露头角。
Apache Flink 作为一款真正的流处理框架,具有较低的延迟性,能够保证消息传输不丢失不重复,具有非常高的吞吐,支持原生的流处理。
本文主要介绍 Flink 的时间概念、窗口计算以及 Flink 是如何处理窗口中的乱序数据。
二、Flink 中的时间概念
在 Flink 中主要有三种时间概念:
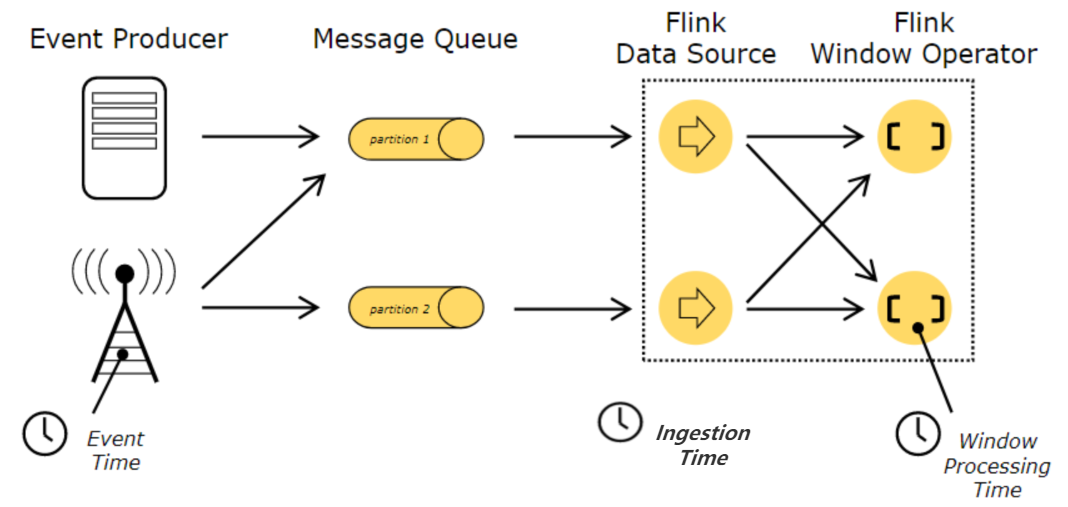
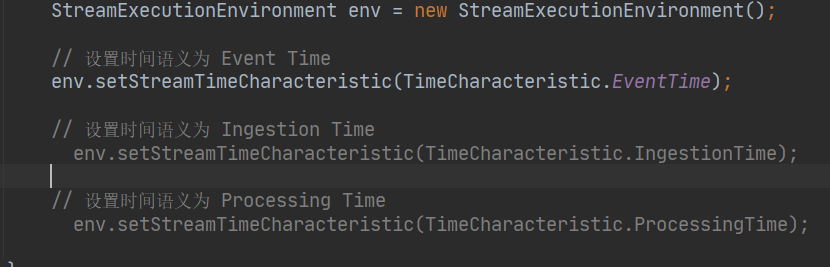
(1)事件产生的时间,叫做 Event Time;
(2)数据接入到 Flink 的时间,叫做 Ingestion Time;
(3)数据在 Flink 系统里被操作时机器的系统时间,叫做 Processing Time
处理时间是一种比较简单的时间概念,不需要流和系统之间进行协调,可以提供最佳的性能和最低的延迟。但是在分布式环境中,多台机器的处理时间无法做到严格一致,无法提供确定性的保障。
而事件时间是事件产生的时间,在进入到 Flink 系统的时候,已经在 record 中进行记录,可以通过用提取事件时间戳的方式,保证在处理过程中,反映事件发生的先后关系。
三、Flink 为什么需要窗口计算
我们知道流式数据集是没有边界的,数据会源源不断的发送到我们的系统中。
流式计算最终的目的是去统计数据产生汇总结果的,而在无界数据集上,如果做一个全局的窗口统计,是不现实的。
只有去划定一定大小的窗口范围去做计算,才能最终汇总到下游的系统中,用来分析和展示。
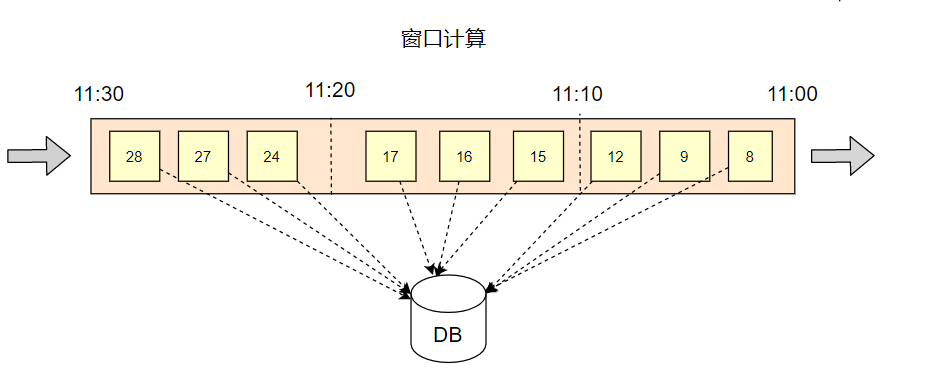
在 Flink 进行窗口计算的时候,需要去知道两个核心的信息:
- 每个 Element 的 EventTime 时间戳?(在数据记录中指定即可)
- 接入的数据,何时可以触发统计计算 ? (窗口 11:00 ~ 11:10 的数据全部被接收完)
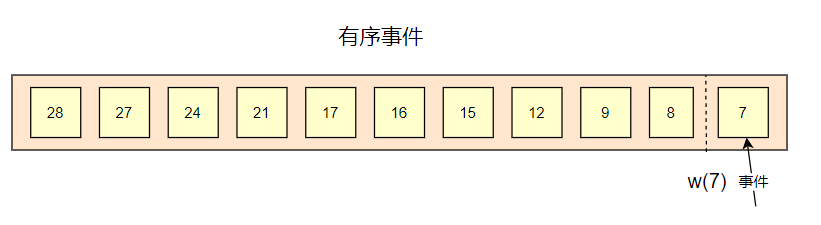
有序事件
假设在完美的条件下,数据都是严格有序,那么此时,流式计算引擎是可以正确计算出每个窗口的数据的
无序事件
但是现实中,数据可能会因为各种各样的原因(系统延迟,网络延迟等)不是严格有序到达系统,甚至有的数据还会迟到很久,此时 Flink 需要有一种机制,允许数据可以在一定范围内乱序。
这种机制就是水印。
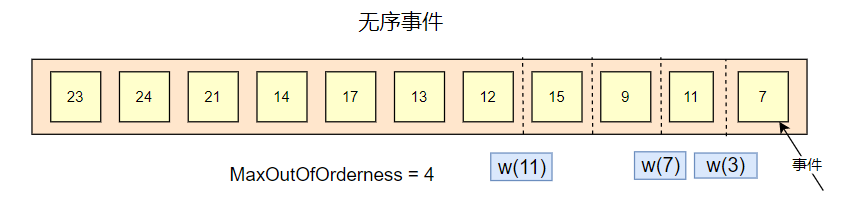
如上面,有一个参数: MaxOutOfOrderness = 4,为最大乱序时间,意思是可以允许数据在多少范围内乱序,可以是 4 分钟,4 个小时 等。
水印的生成策略是,当前窗口最大事件时间戳减去 MaxOutOfOrderness 的值。
如上图,事件 7 会产生一个 w(3) 的水印,事件 11 会产生要给 w(7) 的水印,但是事件 9 ,是小于事件 11 的,此时不会触发水印的更新。事件 15 会产生一个 w(11) 的水印。 也就是说,水印反映了事件的整体流转的趋势,只会上升,不会下降。
水印表示了所有小于水印值的事件都已经到达了窗口。
每当有新的最大时间戳出现时,就会产生新的 watermark
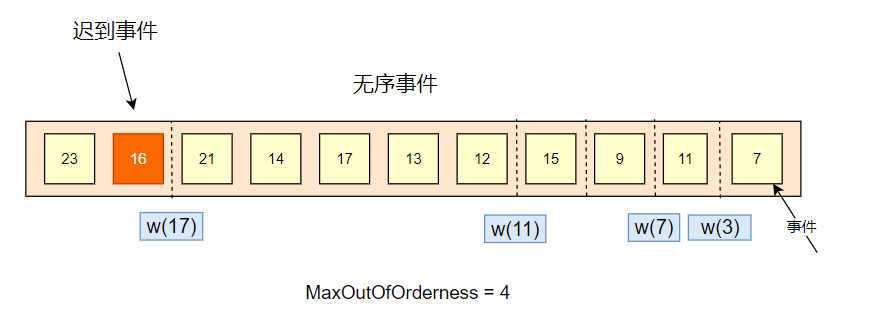
迟到事件
对于事件时间小于水印时间的事件,称为迟到事件。迟到事件是不会被纳入窗口统计的。
如下图,21 的事件进入系统之后,会产生 w(17) 的水印。而后来的 16 事件,由于小于当前水印时间 w(17),是不会被统计的了。
何时触发计算
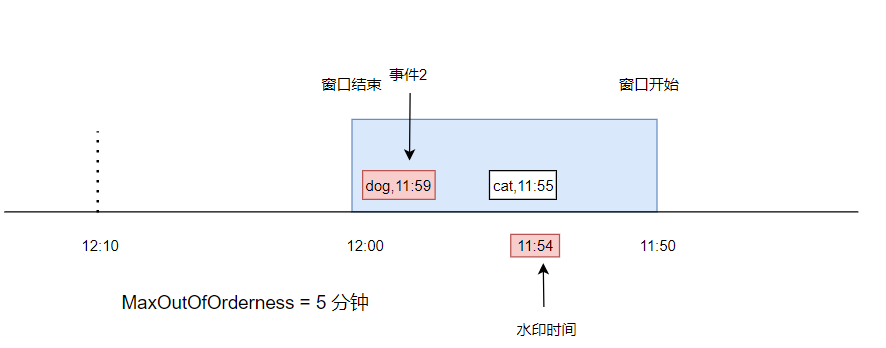
我们用一个图来展示何时会触发窗口的计算
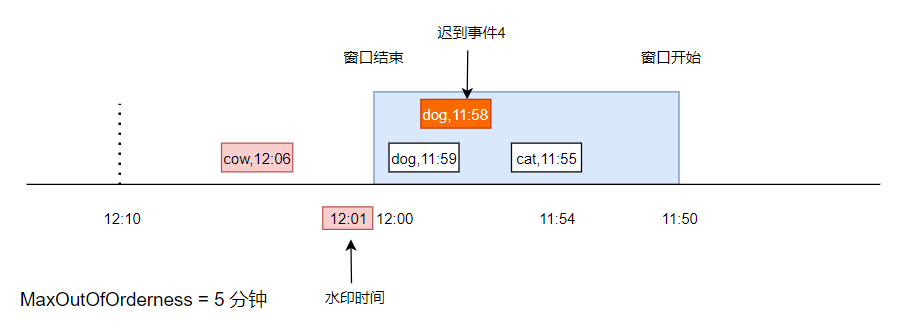
如下图,表示一个 11:50 到 12:00 的窗口,此时有一条数据, cat,11:55,事件时间是 11:55,在窗口中,最大延迟时间是 5 分钟,所以当前水印时间是 11:50

此时又来了一条数据,dog,11:59,事件时间是 11:59,进入到了窗口中。
由于这个事件时间比上次的事件时间大,所以水印被更新成 11:54。此时由于水印时间仍然小于窗口结束时间,所以仍然没有触发计算。
又来了一条数据, cow,12:06,此时水印时间被更新到了 12:01 ,已经大于了窗口结束时间,此时触发了窗口计算(假设计算逻辑就是统计窗口内不同元素的个数)。
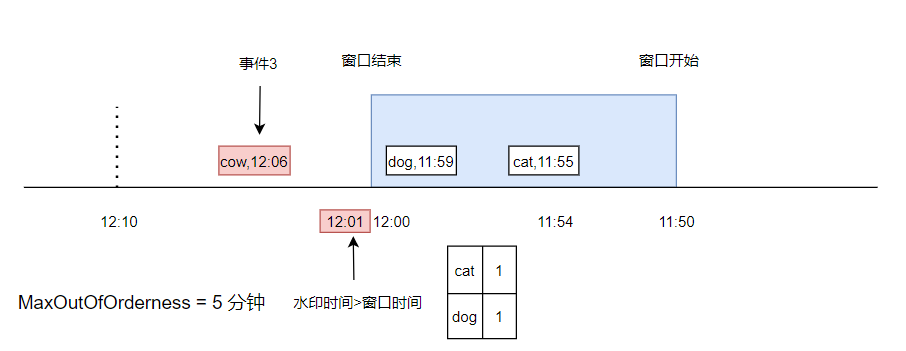
假设又来了一条事件,是 dog,11:58,由于它已经小于了水印时间,并且在上次触发窗口计算之后,窗口已经被销毁,所以,这条事件是不会被触发计算的了。
此时,可以这个事件放到 sideoutput 队列中,额外逻辑处理。
四、Flink 1.11 版本 中,如何定义水印
所以在 1.11 版本中,重构了水印生成接口。新版本中,主要通过 WatermarkStrategy 类,来使用不同的策略生成水印。
新的接口提供了很多静态的方法和带有缺省实现的方法,如果想自己定义生成策略,可以实现这个方法:
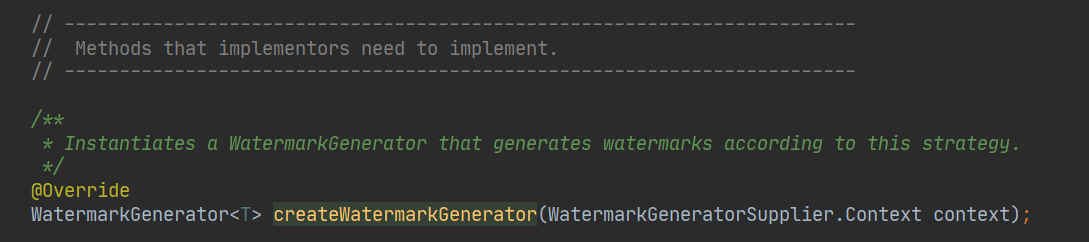
生成一个 WatermarkGenerator
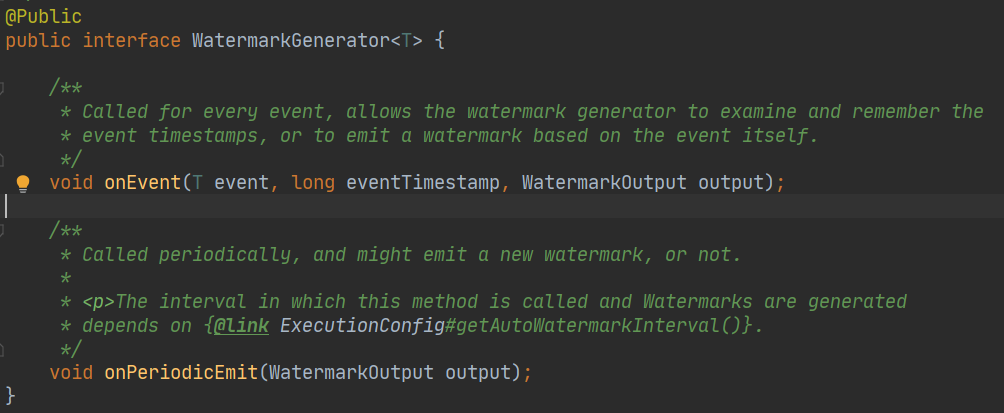
这个类也很简单明了
- onEvent:如果我们想依赖每个元素生成一个水印发射到下游,可以实现这个方法;
- OnPeriodicEmit:如果数据量比较大的时候,我们每条数据都生成一个水印的话,会影响性能,所以这里还有一个周期性生成水印的方法。
为了方便开发,Flink 还提供了一些内置的水印生成方法供我们使用
- 固定延迟生成水印
我们想生成一个延迟 3 s 的固定水印,可以这样做
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)));
- 单调递增生成水印
相当于上述的延迟策略去掉了延迟时间,以 event 中的时间戳充当了水印,可以这样使用:
DataStream dataStream = ...... ;
dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps());
五、一个简单的小例子,来统计窗口中字母出现的次数
public class StreamTest1 {
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public static class MyLog {
private String msg;
private Integer cnt;
private long timestamp;
}
public static class MySourceFunction implements SourceFunction<MyLog> {
private boolean running = true;
@Override
public void run(SourceContext<MyLog> ctx) throws Exception {
while (true) {
Thread.sleep(1000);
ctx.collect(new MyLog(RandomUtil.randomString(1),1,System.currentTimeMillis()));
}
}
@Override
public void cancel() {
this.running = false;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 数据源使用自定义数据源,每1s发送一条随机消息
env.addSource(new MySourceFunction())
// 指定水印生成策略是,最大事件时间减去 5s,指定事件时间字段为 timestamp
.assignTimestampsAndWatermarks(
WatermarkStrategy.
<MyLog>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event,timestamp)->event.timestamp))
// 按 消息分组
.keyBy((event)->event.msg)
// 定义一个10s的时间窗口
.timeWindow(Time.seconds(10))
// 统计消息出现的次数
.sum("cnt")
// 打印输出
.print();
env.execute("log_window_cnt");
}
}
本文由博客一文多发平台 OpenWrite 发布!
Apache Flink 如何正确处理实时计算场景中的乱序数据的更多相关文章
- Flink+kafka实现Wordcount实时计算
1. Flink Flink介绍: Flink 是一个针对流数据和批数据的分布式处理引擎.它主要是由 Java 代码实现.目前主要还是依靠开源社区的贡献而发展.对 Flink 而言,其所要处理的主要场 ...
- 在边缘计算场景中使用Dapr
Dapr 是分布式应用程序可移植.事件驱动的运行时, 这里有几个关键字,我们拆开来看一下: 分布式: 代表共享或是分散,在云原生应用上体现为微服务,在边缘计算场景中代表分散的模块,可以做积木式拼接. ...
- 分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tab ...
- (转)分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tab ...
- Flink使用二次聚合实现TopN计算-乱序数据
一.背景说明: 在上篇文章实现了TopN计算,但是碰到迟到数据则会无法在当前窗口计算,需要对其中的键控状态优化 Flink使用二次聚合实现TopN计算 本次需求是对数据进行统计,要求每隔5秒,输出最近 ...
- SQLSERVER:计算数据库中各个表的数据量和每行记录所占用空间
转:http://www.cnblogs.com/lyhabc/p/3828496.html CREATE TABLE #tablespaceinfo ( nameinfo ) , rowsinfo ...
- Unity3D中如何计算场景中的三角面和顶点数
在做游戏开发时,场景中的三角面和顶点数影响着运行效率,尤其是在手机平台上,实时的知道场景中的各项指标,对性能优化来说至关重要,下面我们来实现一个小功能,来实时计算场景中的三角面和顶点数: 如果要知道场 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 大数据“重磅炸弹”——实时计算框架 Flink
Flink 学习 项目地址:https://github.com/zhisheng17/flink-learning/ 博客:http://www.54tianzhisheng.cn/tags/Fli ...
随机推荐
- phpword读取内容和样式 生成新的内容
table样式还未读出 正在测试中, 目前有 rows cell textrun等样式 顺序不固定 可以设定 <?php require 'vendor/autoload.php'; use P ...
- c#方法 最大值我最小值
static void Main(string[] args) { int[] a = { 6, 8, 9, 5, 2, 165, 58966 }; Console.WriteLine("最 ...
- c#分割习题
2.从一个记录了学生成绩的文本文档,每个学生成绩是一行,每行是用 | 分割的数据,用 | 分割的域分别是姓名.年龄.成绩.年级,写程序取出各个年级成绩最高学生的成绩.年级放到集合中.提示:(1)使用 ...
- 回顾MySql的一些基本的增删改查
---恢复内容开始--- 回顾数据库的一些简单的增删查改的操作语法与注意点,来自菜鸟教程https://www.runoob.com/mysql/mysql-tutorial.html 关于数据库的操 ...
- 强迫自己学习Jquery三
元素定位问题 offset 和 position必须要好好看一下,
- sock skbuf 结构:
/** * struct sock - network layer representation of sockets * @__sk_common: shared layout with inet_ ...
- fcntl函数用法——操纵文件描述符状态
fcntl函数:操纵文件描述符,改变已经打开的文件的属性int fcntl(int fd, int cmd, ... //arg );cmd选项:一.复制文件描述符:F_DUPFD二.更改设置文件描 ...
- day05-类型转换和变量
1.类型转换概念 java是强类型语言,所以有些运算的时候,需要用到类型转换 类型转换原则:低-->高,byte,short,char-->int-->long-->float ...
- ubuntu安装软件自动交互
在ubuntu下安装软件过程中可能会出现需要你输入密码或者其他的一些交互类的操作,这样在脚本安装的时候就可能出现阻断,这个在ubuntu里面已经考虑到了这个情况,以前我在安装这个的时候,通过的是脚本传 ...
- 还是畅通工程(最小生成树 并查集 Prim Kruskal)
Description 某省调查乡村交通状况,得到的统计表中列出了任意两村庄间的距离.省政府"畅通工程"的目标是使全省任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只 ...