docker安装部署neo4j
docker部署neo4j
环境:ubuntu16.04LTS
docker安装
docker国内镜像源配置
第一步,进入阿里云,登陆后点击左侧的镜像加速,生成自己的镜像加速地址。
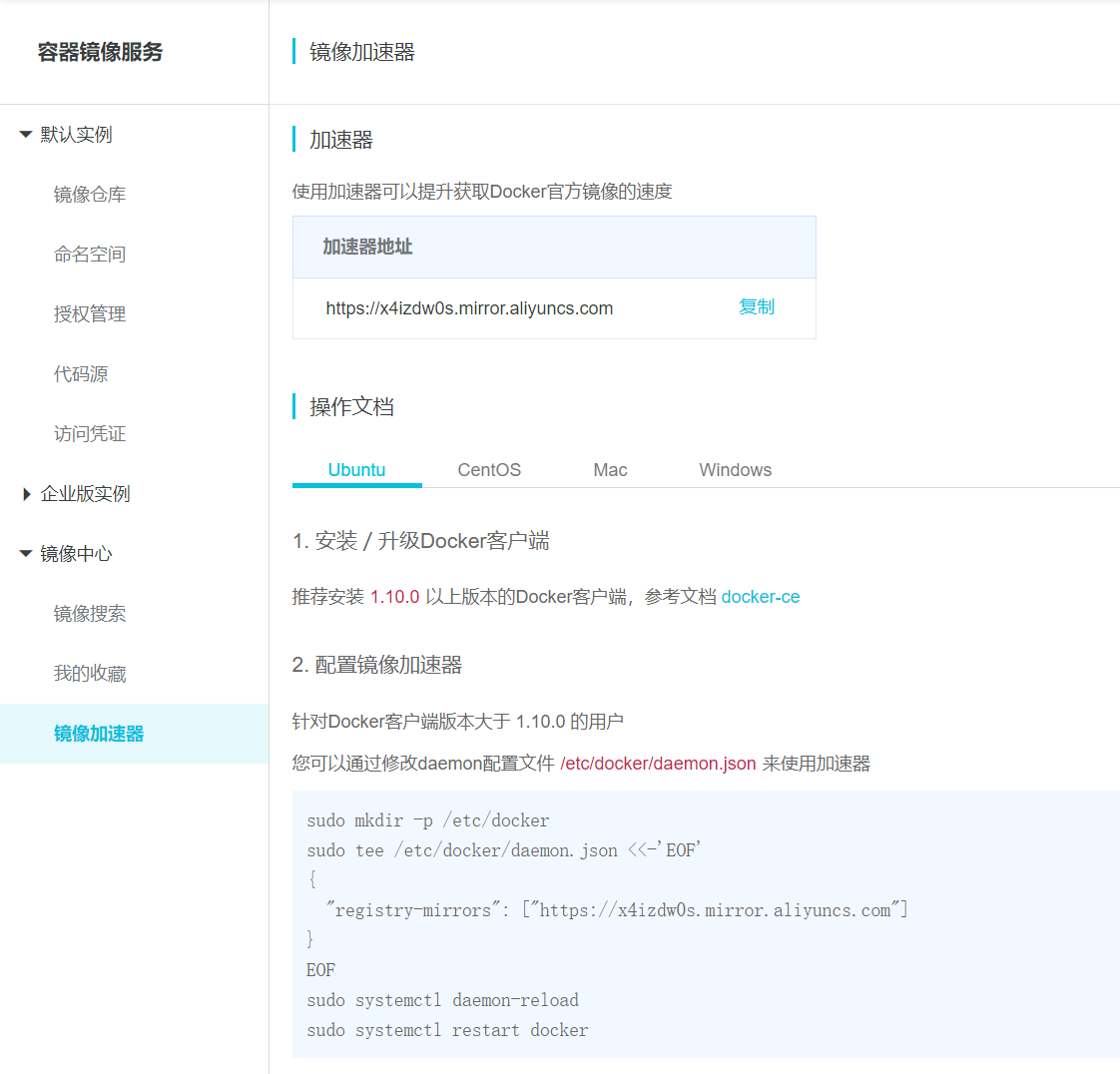
第二步,选择ubuntu,执行阿里云推荐的终端命令,即可更新docker的镜像源为阿里云镜像。
docker部署neo4j
拉取neo4j镜像
第一步,从镜像源中找合适的镜像
docker search neo4j
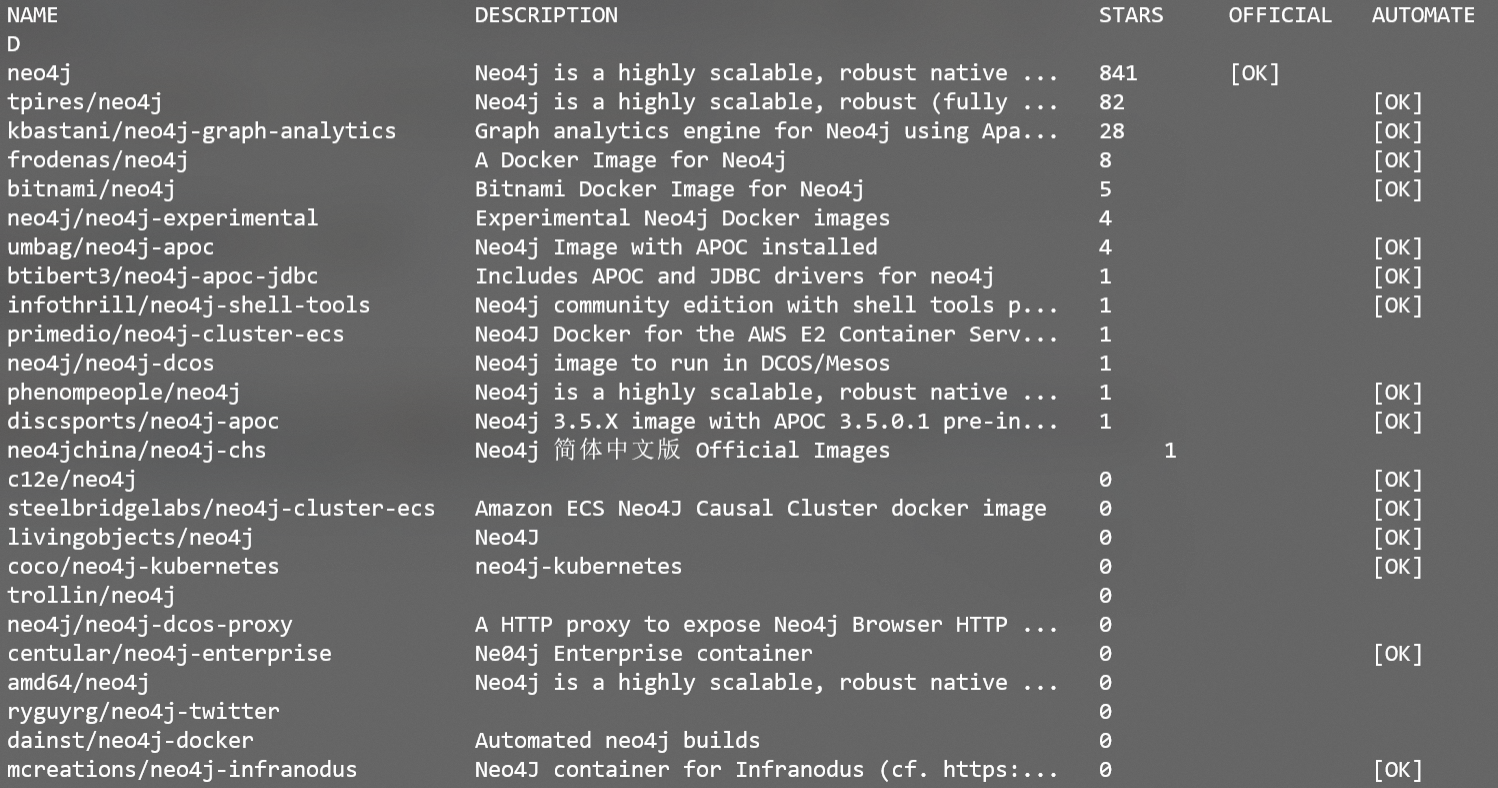
第二步,拉取镜像源
docker pull neo4j(:版本号) //缺省 “:版本号” 时默认安装latest版本的
第三步,查看本地镜像,检验是否拉取成功
docker images

构建neo4j容器
第一步,在你根目录的任意一个子目录(我这里是/home)下建立四个基本的文件夹
- data——数据存放的文件夹
- logs——运行的日志文件夹
- conf——数据库配置文件夹(在配置文件neo4j.conf中配置包括开放远程连接、设置默认激活的数据库)
- import——为了大批量导入csv来构建数据库,需要导入的节点文件nodes.csv和关系文件rel.csv需要放到这个文件夹下)
docker run -d --name container_name \ //-d表示容器后台运行 --name指定容器名字
-p 7474:7474 -p 7687:7687 \ //映射容器的端口号到宿主机的端口号
-v /home/neo4j/data:/data \ //把容器内的数据目录挂载到宿主机的对应目录下
-v /home/neo4j/logs:/logs \ //挂载日志目录
-v /home/neo4j/conf:/var/lib/neo4j/conf //挂载配置目录
-v /home/neo4j/import:/var/lib/neo4j/import \ //挂载数据导入目录
--env NEO4J_AUTH=neo4j/password \ //设定数据库的名字的访问密码
neo4j //指定使用的镜像
一个可以直接复制粘贴到终端执行的代码模板
docker run -d --name container_name -p 7474:7474 -p 7687:7687 -v /home/neo4j/data:/data -v /home/neo4j/logs:/logs -v /home/neo4j/conf:/var/lib/neo4j/conf -v /home/neo4j/import:/var/lib/neo4j/import --env NEO4J_AUTH=neo4j/password neo4j
其中container_name可以自己指定,挂载在根目录下的子目录可以根据你自己的实际情况进行替换,我这里是/home。另外NEO4J_AUTH也是你自己来进行设置。
执行完上述命令后就在后台把neo4j容器启动起来了,这个时候你就能在宿主机的浏览器中输入
localhost:7474
输入用户名和密码就能登录到数据库了。
neo4j配置
上述方式启动的neo4j是按照默认的配置进行启动的,而默认的数据库配置是不允许远程登陆的,这样对于在服务器上使用docker搭载neo4j的同学来说,就很不方便了。所以我们对默认配置进行一些改变,改变如下:
// 进入容器配置目录挂载在宿主机的对应目录,我这里是/home/neo4j/conf
cd /home/neo4j/conf
// vim编辑器打开neo4j.conf
vim neo4j.conf
// 进行以下更改
//在文件配置末尾添加这一行
dbms.connectors.default_listen_address=0.0.0.0 //指定连接器的默认监听ip为0.0.0.0,即允许任何ip连接到数据库
//修改
dbms.connector.bolt.listen_address=0.0.0.0:7687 //取消注释并把对bolt请求的监听“地址:端口”改为“0.0.0.0:7687”
dbms.connector.http.listen_address=0.0.0.0:7474 //取消注释并把对http请求的监听“地址:端口”改为“0.0.0.0:7474”
保存后退出,重启neo4j容器,可以使用容器的省略id或者生成容器时指定的容器名进行重启。
docker restart 容器id(或者容器名)
防火墙设置
// 查看当前防火墙状态,若为“inactive”,则防火墙已关闭,不必进行接续操作。
sudo ufw status
// 若防火墙状态为“active”,则使用下列命令开放端口
sudo ufw allow 7474
sudo ufw allow 7687
// 重启防火墙
sudo ufw reload
neo4j数据导入
neo4j数据的批量导入方法
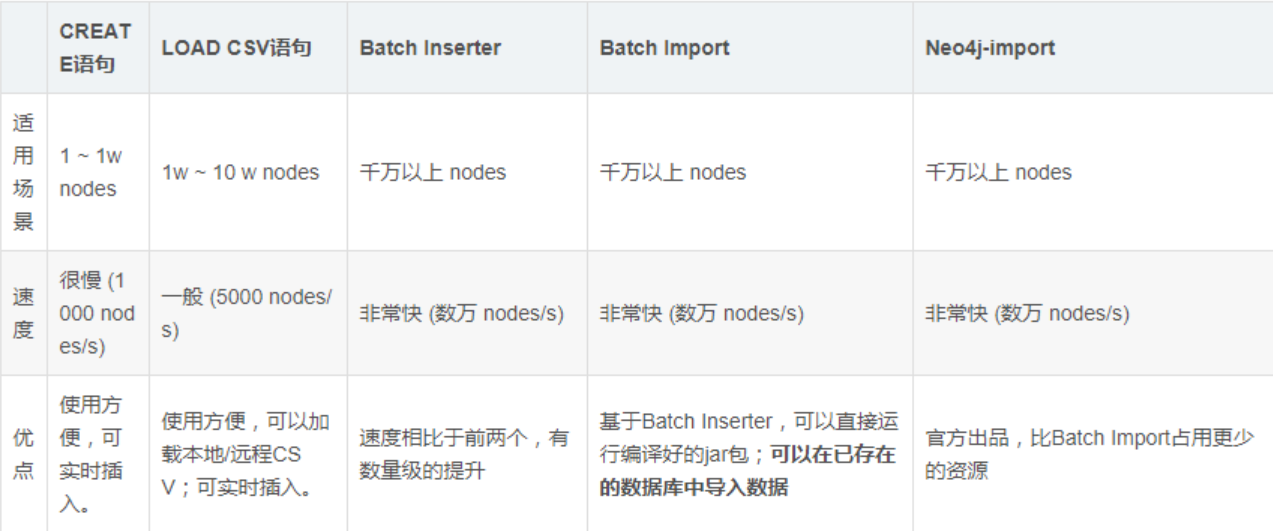
为了加快速度,使用官方的Neo4j-import进行导入
// 数据准备
清空data/databases/graph.db文件夹(如果有),将清洗好的结点文件nodes.csv和关系文件rel.csv拷贝到宿主机/home/neo4j/import中
// docker以exec方式进入容器的交互式终端
docker exec -it container_name(or container_id) /bin/bash
// 停掉neo4j
bin/neo4j stop
//使用如下命令导入
bin/neo4j-admin import \
--database=graph.db \ //指定导入的数据库,没有系统则会在data/databases下自动创建一个
--nodes ./import/nodes.csv //指定导入的节点文件位置
--relationships ./import/rel.csv //指定导入的关系文件位置
--skip-duplicate-nodes=true //设置重复节点自动过滤
--skip-bad-relationships=true //设置bad关系自动过滤
//可执行一行式终端命令
bin/neo4j-admin import --database=graph.db --nodes ./import/nodes.csv --relationships ./import/rel.csv --skip-duplicate-nodes=true --skip-bad-relationships=true
// 容器内启动neo4j
bin/neo4j start
// 退出交互式终端但是保证neo4j后台继续运行
ctrl + P + Q
//保险起见,重启neo4j容器
docker restart container_name(or container_id)
重启后使用另一台主机向服务器发送http请求进行远程登陆,在浏览器中输入
服务器ip:7474
切换连接模式为 bolt:/ ,输入用户名和密码进行登陆,登陆成功发现在数据库一栏没找到新导入的数据库graph.db
这是因为配置不够全,继续进到容器挂载到宿主机的/home/neo4j/conf中对neo4j.conf进行配置
//在文件末尾添加默认的数据库
dbms.active_database=graph.db
// 保存后重启容器
docker restart container_name(or container_id)
重新进行远程连接,此时数据库的默认选择应该就切换到了新导入的graph.db。
数据清洗
数据如何清洗成两个符合neo4j-import导入格式的csv文件?
docker安装部署neo4j的更多相关文章
- 使用docker安装部署Spark集群来训练CNN(含Python实例)
使用docker安装部署Spark集群来训练CNN(含Python实例) http://blog.csdn.net/cyh_24/article/details/49683221 实验室有4台神服务器 ...
- Docker安装部署es集群
Docker安装部署es集群:环境准备:已安装docker的centos服务器一台1. 拉取es版本docker pull elasticsearch:5.6.82. 新建文件夹 数据挂载目录 和 配 ...
- docker安装部署、fastDFS文件服务器搭建与springboot项目接口
一.docker安装部署 1.更新yum包:sudo yum update 2.安装需要的软件包,yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动 ...
- Docker安装部署Rancher
# 一.Rancher简介 [Rancher](https://www.cnrancher.com/rancher/)是一个开源的企业级容器管理平台.通过Rancher,企业再也不必自己使用一系列的开 ...
- Docker安装部署redis
借鉴博客:https://my.oschina.net/u/3489495/blog/1825335 待续... >>>>>>>>>docker安 ...
- CentOS 7 Docker安装部署Go Web
Docker 是一种容器技术,它部署简单,能很好的进行服务隔离,生成镜像,Push到镜像仓库,其他机器一键拉取部署. Docker分为社区版CE和企业版EE,社区版是免费提供给个人和小型团队使用,企业 ...
- Docker 安装部署
Docker学习笔记 一.Ubuntu Docker 安装 (1).获取最新版本Docker安装包 lyn@lyn:/data/docker$ sudo wget -qO- https://get.d ...
- 002.Docker安装部署
一 docker安装-CentOS系统 1.1 docker自动安装脚本 root@docker:~# wget -qO- https://get.docker.com/ | sh 或—— root@ ...
- win10 docker 安装部署
Docker 安装教程: https://blog.csdn.net/hunan961/article/details/79484098 安装docker前需要首先开启虚拟服务:重启电脑-->F ...
随机推荐
- Java成神之路:第一帖---- Vue的组件属性components用法
Vue的组件属性:components 使用场景 一般在项目的使用过程中,某个需要多次使用的模块,会将整个模块抽取出来,写一个组件,供给其他页面进行调用或者是在一个页面中,多次使用到一个重复的代码样式 ...
- Python 开发GUI之UI界面的三种引入形式
[纯手工代码] # -*- coding: utf-8 -*- # Author:Jack LEE # FileName:main # CreatedDate: 2020/9/17 # 手写代码的基础 ...
- PyCharm2020.2.1激活方法
本人亲测有效!直接看图! 安装准备 一.百度网盘链接:https://pan.baidu.com/s/151vnrZG2V4eMPW8RYqse3w 提取码:z5k0 至于Pycharm的安装在这 ...
- Kvm 虚拟化介绍(1)
一.虚拟化分类 1.虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机.在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间 ...
- jekins使用的坑
1.日志打满 一个周末回来,服务器的磁盘就写满了 现象如下,最后是修改catalina脚本 添加了如下配置 ###jekins log problem#########export JAVA_OPTS ...
- hystrix文档翻译之Dashboard
Dashboard Hystrix Dashboard可以让你实时监控hystrix的metrics信息. 当netflix开始使用dashboard后,运维效率得到了极大的提升,并且极大降低了大多数 ...
- 【论文】The Road to SDN: An Intellectual History of Programmable Networks
目录 ABSTRACT: 1 Introduction: 2 The Road to SDN: 2.1 Active Networking Technology push and use pull I ...
- xxe-xml外部实体注入
XML文件格式及作用 copy至:https://www.runoob.com/xml/xml-tutorial.html 学习xxe为什么要了解XML和DTD,直接跳至Xxe查看: 定义&作 ...
- spring整合(Junit、web)
1.整合Junit (1)整合前的测试类代码 public class Test { public static void main(String[] args) { ApplicationConte ...
- 线上Redis高并发性能调优实践
项目背景 最近,做一个按优先级和时间先后排队的需求.用 Redis 的 sorted set 做排队队列. 主要使用的 Redis 命令有, zadd, zcount, zscore, zrange ...