dom4j基本操作
DOM4J与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:
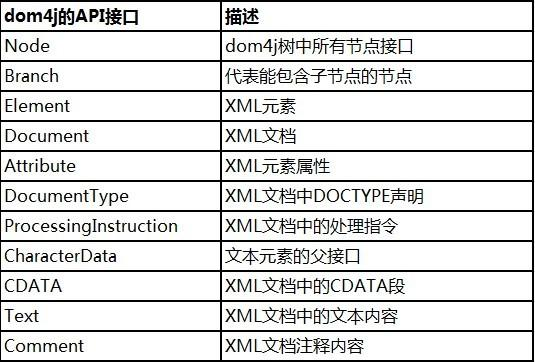
常用API
org.dom4j.io.SAXReader
- read 提供多种读取xml文件的方式,返回一个Domcument对象
org.dom4j.Document
- iterator 使用此法获取node
- getRootElement 获取根节点
org.dom4j.Node
- getName 获取node名字,例如获取根节点名称为bookstore
- getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
- getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
org.dom4j.Element
- attributes 返回该元素的属性列表
- attributeValue 根据传入的属性名获取属性值
- elementIterator 返回包含子元素的迭代器
- elements 返回包含子元素的列表
org.dom4j.Attribute
- getName 获取属性名
- getValue 获取属性值
org.dom4j.Text
- getText 获取Text节点值
org.dom4j.CDATA
- getText 获取CDATA Section值
org.dom4j.Comment
- getText 获取注释
下面做了一个类以如下的XML为例:
<html>
<head>
<title>解析xml例子</title>
<script>
<username>yangrong</username>
<password>123456</password>
</script>
</head>
<body>
<result>0</result>
<form>
<banlce>1000</banlce>
<subID>36242519880716</subID>
</form>
</body>
</html>
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.List;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter; import com.alibaba.fastjson.JSON; public class OperateXml { @SuppressWarnings("unused")
public static void main(String[] args) {
// 下面是需要解析的xml字符串例子
String xmlString = "<html><head><title>解析xml例子</title><script><username>yangrong</username><password>123456</password></script></head><body><result>0</result><form><banlce>1000</banlce><subID>36242519880716</subID></form></body></html>";
//主动创建document对象.
Document document=DocumentHelper.createDocument();//建立document对象,用来操作xml文件 Document testdoc=DocumentHelperreadStringXml(xmlString);
//将文档或节点的XML转化为字符串.
String docXmlText=testdoc.asXML();
String teststring=Documentanalysis1(testdoc);
System.out.print(teststring);
} public static Document DocumentHelperreadStringXml(String xmlContent) {
// DocumentHelper 解析xml字符串
Document document = null;
try {
document = DocumentHelper.parseText(xmlContent);
} catch (DocumentException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return document;
} public static Document SAXReaderreadStringXml(String xmlContent)
throws DocumentException, UnsupportedEncodingException {
/* SAXReader解析xml字符串 */
Document document = null;
try {
// 读取输入流
SAXReader saxReader = new SAXReader();
document = saxReader.read(new ByteArrayInputStream(xmlContent.getBytes("utf-8")));// 字符串要根据相应的编码转成输入流才能被SAXReader读取。
} catch (Exception ex) {
ex.printStackTrace();
}
return document; } // 读写XML文档主要依赖于org.dom4j.io包,有DOMReader和SAXReader两种方式。因为利用了相同的接口,它们的调用方式是一样的。
public static Document SAXReaderreadfile(String filename) {
/* SAXReader解析xml文件 */
Document document = null;
try {
SAXReader saxReader = new SAXReader();
document = saxReader.read(new File(filename)); // 读取XML文件,获得document对象
} catch (Exception ex) {
ex.printStackTrace();
}
return document;
} public static Document SAXReaderreadurl(URL url) {
Document document = null;
try {
SAXReader saxReader = new SAXReader();
document = saxReader.read(url); // 读取XML文件,获得document对象
} catch (Exception ex) {
ex.printStackTrace();
}
return document;
} // 根节点是xml分析的开始,任何xml分析工作都需要从根开始
@SuppressWarnings("unchecked")
public static String Documentanalysis1(Document doc) {
Map<String, String> uploadMap = new HashMap<String, String>();
Element html = doc.getRootElement();// 获取根结点
Element head = html.element("head");// 获取子结点
Element title = head.element("title");// 获取子子结点
Element script = head.element("script");// 获取子子结点
String text=script.elementText("username");//这个是取得script节点下的username字节点的文字.
// 得到根元素的所有子节点
List<Element> elist = script.elements();
// 遍历所有子节点
for (int i = 0; i < elist.size(); i++) {
Element e = elist.get(i);
uploadMap.put(e.getName(), e.getText());
}
return JSON.toJSONString(uploadMap);
} @SuppressWarnings("rawtypes")
public static String Documentanalysis2(Document doc) {
// 将解析结果存储在HashMap中
Map<String, String> uploadMap = new HashMap<String, String>();
// 得到xml根元素
Element root = doc.getRootElement();
Iterator forms = root.element("body").element("form").elementIterator(); // 获取ticketNotify节点下所有的ticket节点的配置属性,并将其放到Map中
/* // 创建迭代器,用来查找要删除的节点,迭代器相当于指针,指向root下所有的title节点
Iterator iterator =root.elementIterator("title");*/
while (forms.hasNext()) {
Element e = (Element) forms.next();
uploadMap.put(e.getName(), e.getText());
}
return JSON.toJSONString(uploadMap);
} @SuppressWarnings("unchecked")
public static String Documentanalysis3(Document doc) {
// 将解析结果存储在HashMap中
Map<String, String> uploadMap = new HashMap<String, String>();
// 用Document的selectNodes来读取节点,返回list
List<Element> elementList = doc.selectNodes("/html/body/form/*");
/* 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述
* 匹配任何元素节点。
@* 匹配任何属性节点。
node() 匹配任何类型的节点。*/
for (Element e : elementList) {
uploadMap.put(e.getName(), e.getText());
}
return JSON.toJSONString(uploadMap);
}
// 添加xml节点,addroot为即将插入节点的父节点
public static void addElement(Element addroot, String elementname, String elementvalue) {
Element childelement = addroot.addElement(elementname);
childelement.setText(elementvalue);
}
// 删除xml节点,addroot为即将删除节点的父节点
public static void addElement(Element addroot, String elementname) {
addroot.remove(addroot.element(elementname));
}
//写入XML文件,可设置编码方式设置encodetype为"",默认为UTF-8
public static boolean doc2XmlFile(Document document, String filename,String encodetype) {
boolean flag = true;
try {
//通过XMLWriter将Document对象表示的XML树写入指定的文件
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream(filename), "".equals(encodetype)?"UTF-8":encodetype));
writer.write(document);
writer.close();
} catch (Exception ex) {
flag = false;
ex.printStackTrace();
}
System.out.println(flag);
return flag;
}
//创建xml文件
public static void WriterXmltoFile(Document document, String filename,String encodetype) {
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding(encodetype); // 指定XML编码
try{
XMLWriter writer=new XMLWriter(new FileWriter(new File(filename)),format);
writer.write(document);
writer.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
Element类
|
getQName() |
元素的QName对象 |
|
getNamespace() |
元素所属的Namespace对象 |
|
getNamespacePrefix() |
元素所属的Namespace对象的prefix |
|
getNamespaceURI() |
元素所属的Namespace对象的URI |
|
getName() |
元素的local name |
|
getQualifiedName() |
元素的qualified name |
|
getText() |
元素所含有的text内容,如果内容为空则返回一个空字符串而不是null |
|
getTextTrim() |
元素所含有的text内容,其中连续的空格被转化为单个空格,该方法不会返回null |
|
attributeIterator() |
元素属性的iterator,其中每个元素都是Attribute对象 |
|
attributeValue() |
元素的某个指定属性所含的值 |
|
elementIterator() |
元素的子元素的iterator,其中每个元素都是Element对象 |
|
element() |
元素的某个指定(qualified name或者local name)的子元素 |
|
elementText() |
元素的某个指定(qualified name或者local name)的子元素中的text信息 |
|
getParent |
元素的父元素 |
|
getPath() |
元素的XPath表达式,其中父元素的qualified name和子元素的qualified name之间使用"/"分隔 |
|
isTextOnly() |
是否该元素只含有text或是空元素 |
|
isRootElement() |
是否该元素是XML树的根节点 |
dom4j基本操作的更多相关文章
- 使用dom4j技术对xml文件的基本操作
1.pojo类:Notice package com.green.notice.storage; import java.util.ArrayList; import java.util.List; ...
- dom4j的基本操作
/** * 建立一个XML文档,文档名由输入属性决定 * @param filename 需建立的文件名 * @return 返回操作结果, 0表失败, 1表成功 */ import java.io. ...
- 学生管理系统增删查基本操作(dom4j/sax技术)
基本代码: student.xml <?xml version="1.0" encoding="UTF-8"?><student> &l ...
- # java对xml文件的基本操作
下面是简单的总结三种常用的java对xml文件的操作 1. dom方式对xml进行操作,这种操作原理是将整个xml文档读入内存总,在内存中进行操作,当xml文档非常庞大的时候就会出现内存溢出的异常,这 ...
- dom4j学习总结(一)
dom4j学习总结(一) (一)创建Document的基本操作 /** * xml基本操作 */ public void BaseOperation(){ //创建一个document Doc ...
- xml&dom_sax&dom4j的常见操作
<? xml version =”1.0” encoding=”GB2312”?> <!-- 学生信息—><?xml-stylesheet type=”text/css” ...
- Key/Value之王Memcached初探:二、Memcached在.Net中的基本操作
一.Memcached ClientLib For .Net 首先,不得不说,许多语言都实现了连接Memcached的客户端,其中以Perl.PHP为主. 仅仅memcached网站上列出的语言就有: ...
- XML技术之DOM4J解析器
由于DOM技术的解析,存在很多缺陷,比如内存溢出,解析速度慢等问题,所以就出现了DOM4J解析技术,DOM4J技术的出现大大改进了DOM解析技术的缺陷. 使用DOM4J技术解析XML文件的步骤? pu ...
- Android Notification 详解(一)——基本操作
Android Notification 详解(一)--基本操作 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Notification 文中如有纰 ...
随机推荐
- HotSpot VM运行时
HotSpot VM运行时系统为HotSpot JIT编译器和垃圾收集器提供服务和通用API,同时还为VM提供启动.线程管理.JNI(Java本地接口)等基本功能.HotSpot VM运行时环境担当许 ...
- Ethical Hacking - Web Penetration Testing(4)
CODE EXECUTION VULNS Allows an attacker to execute OS commands. Windows or Linux commands. Can be us ...
- 利用tox打造自动自动化测试框架
什么是tox tox官方文档的第一句话 standardize testing in Python,意思就是说标准化python中的测试,那是不是很适合测试人员来使用呢,我们来看看他究竟是什么? 根据 ...
- xenomai内核解析---内核对象注册表—xnregistry(重要组件)
1. 概述 上篇文章xenomai内核解析--同步互斥机制(一)--优先级倒置讲到,对于所有内核对象: xnregistry:保存内核对象,提供内核对象存储和快速检索. xnsynch:资源抽象,提供 ...
- 新阿里云服务器从0开始配置为python开发环境
由于每次打开linux虚拟机比较麻烦,于是尝试一下云服务器,在阿里云领取了一个月的试用服务器,这里记录一下新服务器从0配置成python开发环境的步骤,以便以后配置新服务器时有个参考. 免费领取一个月 ...
- 使用 flask 构建我的 wooyun 漏洞知识库
前言 最近在学 flask,一段时间没看,又忘得差不多了,于是弄这个来巩固一下基础知识 漏洞总共包括了 88820 个, Drops 文章总共有 1235 篇,全来自公开数据,在 Github 上收集 ...
- 基于.Net Core的Redis:基本数据类型及其应用场景与命令行操作
参考自:https://blog.csdn.net/only_yu_yy/article/details/78873735 https://blog.csdn.net/fenghuoliuxing99 ...
- 番外:socketserver用法
进击のpython ***** 番外:socketserver使用 是不是被一般写法,多进程写法,多线程写法甚至是协程写法搞的不可开交 云里雾里,仿佛将要放弃~再配上服务器要服务多个客户端 完蛋了,全 ...
- VS Code小白使用教程
本文来自作者:你不知道的巨蟹 原文链接 https://www.cnblogs.com/tu-0718/p/10935910.html,如有侵权,则可删除. 前言 现在使用Vscode编码的人越来越多 ...
- spring 循环依赖的一次 理解
前言: 在看spring 循环依赖的问题中,知道原理,网上一堆的资料有讲原理. 但今天在看代码过程中,又产生了疑问. 疑问点如下: // 疑问点: 先进行 dependon 判断String[] de ...