python+unittest+ddt数据驱动进行接口自动化测试
所谓数据驱动测试,简单的理解为数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。通过使用数据驱动测试的方法,可以在需要验证多组数据测试场景中,使用外部数据源实现对输入输出与期望值的参数化,避免在测试中使用硬编码的数据。因此只需要创建一个测试脚本就可以处理上表的测试数据和条件的组合,使用数据驱动的模式,根据业务逻辑分解测试数据,并且定义变量,使用外部的excel里的数据使其参数化,从而避免使用源测试脚本中的固定数据,这种方式可以将测试脚本与测试数据分开,使得测试脚本在不同的数据集合下高度复用。
数据驱动的模式不仅可以帮助增加类似复杂条件场景下的测试覆盖,还可以极大的减少对测试代码的编写和维护工作。
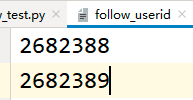
如下业务是:用户登录某个软件系统后,对其他用户进行关注。具体流程是:调用登录接口获取session,然后调取关注接口把session和userid作为参数进行传递,我们把需要关注的用户的userid存放在一个文件中,作为驱动数据。如下两个userid:
# 定义一个函数,获取数据,并且把每组数据作为一个列表放在一个大列表中。
def test_data(path):
with open(path, encoding="utf-8", mode="r") as f:
data = f.readlines()
mydata = []
for line in data:
new_line = []
new_line.append(line.strip())
mydata.append(new_line)
f.close()
return mydata
返回的结果:[['2682388'], ['2682389']]
首先导入需要用到的API
import requests
import unittest
import json
from ddt import ddt, data, unpack # ddt需要通过pip安装
# 获取登录session
def login():
login_url = "http://xxx/xxx/xxx/xxx/login_process/"
data = {"user_name": "xxx",
"avatar_file": "xxx",
"mobile": "12233445567"
}
# 获取返回信息
content = requests.post(login_url, data=data)
# 将bytes类型转换为字典
re = json.loads(content.text)
return re["rsm"]["yme__user_login"], re["rsm"]["yme__Session"]
@ddt # 定义ddt数据驱动
class AFollow(unittest.TestCase):
# 初始化测试用例
def setUp(self) -> None:
# 被测接口地址
self.follow_url = "http://xxx/xxx/xxx/xxx/user_follow/"
def tearDown(self) -> None:
pass
@data(*test_data(r"\\data\follow_userid")) # 获取测试数据,对数据解包前面需要一个*
@unpack 对数据进行解包,解包后数据就变成了这种形式:['2682388'], ['2682389'],每组数据就是一条测试用例
def test_case01(self, user_id):
# 定义需要传入的参数,程序运行时这条用例会执行两次,
# 分别['2682388']和['2682389']作为测试数据执行测试
"""
关注新用户
"""
content = requests.post(self.follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "关注成功") # 断言
@data(*test_data(r"\\data\follow_userid"))
@unpack
def test_case02(self, user_id):
"""
关注已经关注的用户(重复关注用户)
"""
content = requests.post(self.follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "关注失败")
@ddt
class CancelFollow(unittest.TestCase):
def setUp(self) -> None:
self.cancel_follow_url = ""http://xxx/xxx/xxx/xxx/user_follow_del/"
def tearDown(self) -> None:
pass
@data(*test_data(r"\\data\follow_userid"))
@unpack
def test_case01(self, user_id):
"""
取消关注用户
"""
content = requests.post(self.cancel_follow_url, self.get_session(user_id))
print(json.loads(content.text), type(json.loads(content.text)))
re = json.loads(content.text)
self.assertEqual(re["rsm"]["msg"], "取消关注成功", "取消关注失败!")
if __name__ == '__main__':
unittest.main()
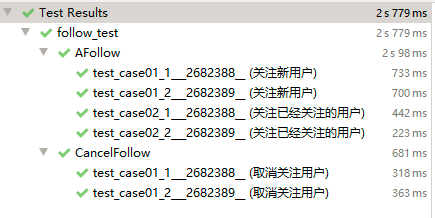
运行测试成功
再调试的过程中遇到了如下错误:
wrapper
add_test(
TypeError: add_test() argument after ** must be a mapping, not str
def test_data(path):
with open(path, encoding="utf-8", mode="r") as f:
data = f.readlines()
mydata = []
for line in data:
mydata.append(line.strip())
f.close()
return mydata
返回结果:['2682388', '2682389']
原因是,在获取数据时,没有将每组数据单独存放在一个列中,解包后测试数据变成了字符串。
所以需要把每组数据放在一个列表中,再把所有组数据放在一个大列表中,也可以放在元组中
python+unittest+ddt数据驱动进行接口自动化测试的更多相关文章
- 利用Python如何实现数据驱动的接口自动化测试
前言 大家在接口测试的过程中,很多时候会用到对CSV的读取操作,本文主要说明Python3对CSV的写入和读取.下面话不多说了,来一起看看详细的介绍吧. 1.需求 某API,GET方法,token,m ...
- python+unittest+requests+HTMLRunner编写接口自动化测试集
问题描述:搭建接口测试框架,执行用例请求多个不同请求方式的接口 实现步骤: ① 创建配置文件config.ini,写入部分公用参数,如接口的基本url.测试报告文件路径.测试数据文件路径等配置项 [D ...
- 接口自动化 [授客]基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0 by:授客 QQ:1033553122 博客:http://blog.sina.com.cn/ishou ...
- 接口自动化 基于python+Testlink+Jenkins实现的接口自动化测试框架[V2.0改进版]
基于python+Testlink+Jenkins实现的接口自动化测试框架[V2.0改进版] by:授客 QQ:1033553122 由于篇幅问题,,暂且采用网盘分享的形式: 下载地址: [授客] ...
- 基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0 目录 1. 开发环境2. 主要功能逻辑介绍3. 框架功能简介 4. 数据库的创建 5. 框架模块详细介绍6. Tes ...
- Python+Unittest+Requests+PyMysql+HTMLReport 接口自动化框架
整体框架使用的是:Python+Unittest+Requests+PyMysql+HTMLReport 多线程并发模式 主要依赖模块 Unittest.Requests.PyMysql.HTMLR ...
- Python Unittest与数据驱动
python中有一个装饰器类DDT,通过它我们可以复用代码,达到数据驱动测试的目的,该类的官方介绍可以参考 http://ddt.readthedocs.io/en/latest/index.html ...
- Python unittest excel数据驱动
安装xlrd 下载地址:https://pypi.python.org/pypi/xlrd 安装ddt 下载地址:https://pypi.python.org/pypi/ddt/1.1.0 clas ...
- Selenium(Python) ddt数据驱动
首先, 添加ddt模块: import unittestfrom time import sleep from ddt import ddt, data, unpack# 导入ddt模块from se ...
随机推荐
- Codeforces Round #666 (Div. 2) Power Sequence、Multiples of Length 思维
题目链接:Power Sequence 题意: 给你n个数vi,你可以对这个序列进行两种操作 1.可以改变其中任意个vi的位置,无成本 2.可以对vi进行加1或减1,每次操作成本为1 如果操作之后的v ...
- hdu2157 How many ways??
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submission ...
- 牛客练习赛70 D.数树 (模拟,STL)
题意:每次有\(3\)中操作,对两个点连条边,删去某条边,或者问当前大小不为\(1\)的树的数量.连重边或者删去一条不存在的边,这样的白痴操作可以无视qwq. 题解:水题,用map存一下pair然后分 ...
- AtCoder Beginner Contest 177 D - Friends (并查集)
题意:有\(n\)个人,给你\(m\)对朋友关系,朋友的朋友也是朋友,现在你想要将他们拆散放到不同的集合中,且每个集合中的人没有任何一对朋友关系,问最少需要多少集合. 题解:首先用并查集将朋友关系维护 ...
- Ubuntu Live CD联网修复
此模式下可以联网修复ubuntu系统下绝大多数问题.进入LIVE CD模式,打开终端执行以下命令: #此处/dev/sda1为ubuntu根分区,工作中根据实际分区情况更改 sudo mount /d ...
- codeforces 1039B Subway Pursuit【二分+随机】
题目:戳这里 题意:一个点在[1,n]以内,我们可以进行4500次查询,每次查询之后,该点会向左或向右移动0~k步,请在4500次查询以内找到该点. 解题思路:一边二分,一边随机. 交互题似乎有好多是 ...
- HDU - 4725 The Shortest Path in Nya Graph 【拆点 + dijkstra】
This is a very easy problem, your task is just calculate el camino mas corto en un grafico, and just ...
- vue中子组件更新父组件
当在子组件里更改了某些信息且关闭子组件后,需要父组件更新修改后的内容,该如何操作 1.$emit触发 父组件 @add="add(val)" 子组件 this.$emit('add ...
- 二、mycat基础知识、基本配置
官网 http://www.mycat.io/ Mycat 概要介绍 https://github.com/MyCATApache/Mycat-Server 入门指南 https://github.c ...
- 手工数据结构系列-C语言模拟栈 hdu1022
这个题我一开始是这么想的.. 爆搜所有可能的出栈序列 然后对输入进行匹配 这样我感觉太慢 然后我们可以想到直接通过入栈序列对出栈序列进行匹配 但是我犯了一个错误..那就是出栈序列一定到入栈序列里找.. ...