Nebula Exchange 工具 Hive 数据导入的踩坑之旅

摘要:本文由社区用户 xrfinbj 贡献,主要介绍 Exchange 工具从 Hive 数仓导入数据到 Nebula Graph 的流程及相关的注意事项。
1 背景
公司内部有使用图数据库的场景,内部通过技术选型确定了 Nebula Graph 图数据库,还需要验证 Nebula Graph 数据库在实际业务场景下的查询性能。所以急迫的需要导入数据到 Nebula Graph 并验证。在这个过程中发现通过 Exchange 工具从 hive 数仓导入数据到 Nebula Graph 文档不是很全,所以把这个流程中踩到的坑记录下来,回馈社区,避免后人走弯路。
本文主要基于我之前发在论坛的 2 篇帖子:
2 环境信息
- Nebula Graph 版本:nebula:nightly
- 部署方式(分布式 / 单机 / Docker / DBaaS):Mac 电脑 Docker 部署
- 硬件信息
- 磁盘(SSD / HDD):Mac 电脑 SSD
- CPU、内存信息:16 G
- 数仓环境(Mac 电脑搭建的本地数仓):
- Hive 3.1.2
- Hadoop 3.2.1
- Exchange 工具:https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/exchange
编译后生成 jar 包
- Spark
spark-2.4.7-bin-hadoop2.7 (conf 目录下配置 Hadoop 3.2.1 对应的 core-site.xml,hdfs-site.xml,hive-site.xml 设置 spark-env.sh)
Scala code runner version 2.13.3 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
3 配置
1 Nebula Graph DDL
CREATE SPACE test_hive(partition_num=10, replica_factor=1); --创建图空间,本示例中假设只需要一个副本
USE test_hive; --选择图空间 test
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagA
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double); -- 创建标签 tagB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double); -- 创建边类型 edgeAB
2 Hive DDL
CREATE TABLE `tagA`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagA select 1,1,'str1',true,11.11;
insert into tagA select 2,2,"str2",false,22.22;
CREATE TABLE `tagB`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagB select 3,3,"str 3",true,33.33;
insert into tagB select 4,4,"str 4",false,44.44;
CREATE TABLE `edgeAB`(
`id_source` bigint,
`id_dst` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into edgeAB select 1,3,5,"edge 1",true,55.55;
insert into edgeAB select 2,4,6,"edge 2",false,66.66;
3 我的最新 nebula_application.conf 文件
注意看exec、fields、nebula.fields、vertex、source、target字段映射
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 4
}
}
# Nebula Graph relation config
nebula: {
address:{
graph: ["192.168.1.110:3699"]
meta: ["192.168.1.110:45500"]
}
user: user
pswd: password
space: test_hive
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/error
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading from Hive
{
name: tagA
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.taga"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
{
name: tagB
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.tagb"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
]
# Processing edges
edges: [
# Loading from Hive
{
name: edgeAB
type: {
source: hive
sink: client
}
exec: "select id_source,id_dst,idint,idstring,tboolean,tdouble from nebula.edgeab"
fields: [id_source,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
source: id_source
target: id_dst
batch: 256
partition: 10
}
]
}
4 执行导入
4.1 确保 nebula 服务启动
4.2 确保 Hive 表和数据就绪
4.3 执行 spark-sql cli 查看 Hive 表以及数据是否正常以确保 Spark 环境没问题
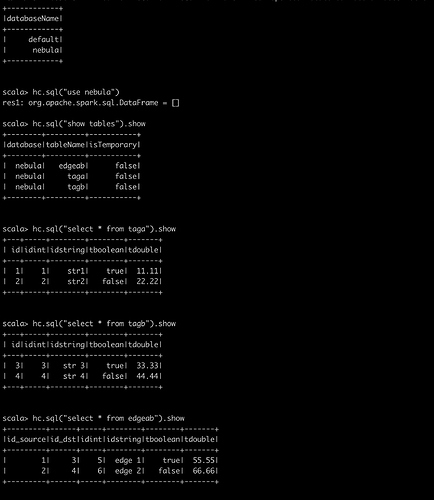
4.4 一切配置工作就绪后,执行 Spark 命令:
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local[4]” /xxx/exchange-1.0.1.jar -c /xxx/nebula_application.conf -h
4.5 导入成功后 可以借助 db_dump 工具查看导入数据量 验证正确性
./db_dump --mode=stat --space=xxx --db_path=/home/xxx/data/storage0/nebula --limit 20000000
5 踩坑以及说明
- 第一个坑就是 spark-submit 命令没有加 -h 参数
- Nebula Graph 中 tagName 是大小写敏感的,tags 的配置中 name 配置的应该是 Nebula Graph 的 tag 名
- Hive的 int 和 Nebula Graph 的 int 不一致,Hive 里面的 bigint 对应 Nebula Graph 的 int
其他说明:
- 由于 Nebula Graph 底层存储是 kv,重复插入其实是覆盖,update 操作用 insert 替代性能会高些
- 文档里面不全的地方可能暂时只有一边看源码解决,一边去论坛问(开发同学也不容易又要紧张的开发又要回答用户的疑问)
- 导入数据、Compact 以及操作建议:https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact/
- 我已经验证如下两个场景:
- 用 Spark 2.4 从 Hive 2(Hadoop 2)中导入数据到 Nebula Graph
- 用 Spark 2.4 从 Hive3(Hadoop 3)中导入数据到 Nebula Graph
说明:Exchange 目前还不支持 Spark 3,编译后运行报错,所以没法验证 Spark 3 环境
还有一些疑问
- nebula_application.conf 文件的参数 batch 和 rate.limit 应该如何设置?参数如何抉择?
- Exchange 工具 Hive 数据导入原理(Spark 这块我也是最近现学现用)
6 Exchange 源码 Debug
Spark Debug 部分参考博客:https://dzone.com/articles/how-to-attach-a-debugger-to-apache-spark
通过 Exchange 源码的学习和 Debug 能加深对 Exchange 原理的理解,同时也能发现一些文档描述不清晰的地方,比如 导入 SST 文件 和 Download and Ingest 只有结合源码看才能发现文档描述不清晰逻辑不严谨的问题。
通过源码 Debug 也能发现一些简单的参数配置问题。
进入正题:
步骤一:
export SPARK_SUBMIT_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=4000
步骤二:
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local” /xxx/exchange-1.1.0.jar -c /xxx/nebula_application.conf -h
Listening for transport dt_socket at address: 4000
步骤三:IDEA 配置
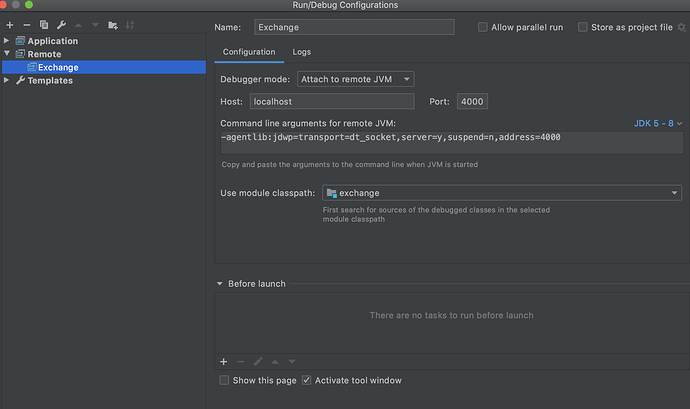
步骤四:在 IDEA 里面点击 Debug
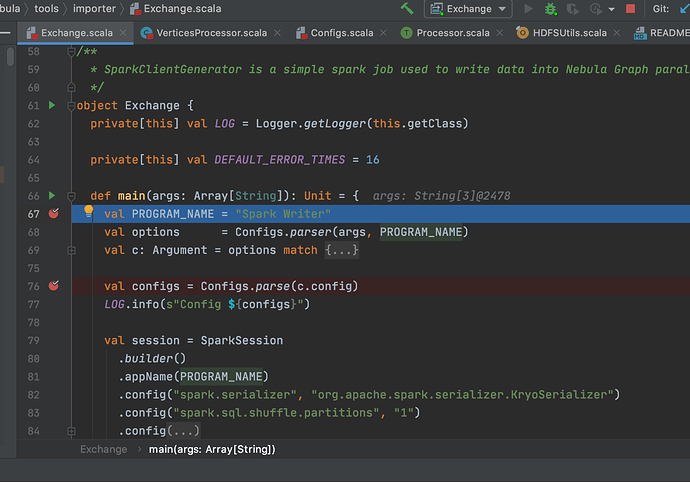
7 建议与感谢
感谢 vesoft 提供了宇宙性能最强的 Nebula Graph 图数据库,能解决业务中很多实际问题,中途这点痛不算什么(看之前的分享,360 数科他们那个痛才是真痛)。中途遇到的问题都有幸得到社区及时的反馈解答,再次感谢
很期待 Exchange 支持 Nebula Graph 2.0
参考资料
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ ♂️♀️ [手动跪谢]
交流图数据库技术?交个朋友,Nebula Graph 官方小助手微信:NebulaGraphbot 拉你进交流群~~
{kind=link}
推荐阅读
Nebula Exchange 工具 Hive 数据导入的踩坑之旅的更多相关文章
- sqoop用法之mysql与hive数据导入导出
目录 一. Sqoop介绍 二. Mysql 数据导入到 Hive 三. Hive数据导入到Mysql 四. mysql数据增量导入hive 1. 基于递增列Append导入 1). 创建hive表 ...
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
- Hive数据导入导出的几种方式
一,Hive数据导入的几种方式 首先列出讲述下面几种导入方式的数据和hive表. 导入: 本地文件导入到Hive表: Hive表导入到Hive表; HDFS文件导入到Hive表; 创建表的过程中从其他 ...
- 复杂业务下向Mysql导入30万条数据代码优化的踩坑记录
从毕业到现在第一次接触到超过30万条数据导入MySQL的场景(有点low),就是在顺丰公司接入我司EMM产品时需要将AD中的员工数据导入MySQL中,因此楼主负责的模块connector就派上了用场. ...
- KUDU数据导入尝试一:TextFile数据导入Hive,Hive数据导入KUDU
背景 SQLSERVER数据库中单表数据几十亿,分区方案也已经无法查询出结果.故:采用导出功能,导出数据到Text文本(文本>40G)中. 因上原因,所以本次的实验样本为:[数据量:61w条,文 ...
- 我的微信小程序入门踩坑之旅
前言 更好的阅读体验请:我的微信小程序入门踩坑之旅 小程序出来也有一段日子了,刚出来时也留意了一下.不过赶上生病,加上公司里也有别的事,主要是自己犯懒,就一直没做.这星期一,赶紧趁着这股热乎劲,也不是 ...
- 微信小程序之mpvue+iview踩坑之旅
因为之前参照微信的原生的文档写过一些小程序的demo,写的过程比较繁琐,后来出了美团的mpvue,可以直接使用vue开发,其他的不作对比,这篇文章记录一下踩坑之旅. 参照mpvue http://mp ...
- CentOS7使用tar.gz包安装MySql的踩坑之旅
由于客户的CentOS服务器没有安装yum工具,只能通过下载tar.gz包安装mysql,于是跟着万能的百度开启了漫漫踩坑之旅: 1.下载mysql-5.6.33-linux-glibc2.5-x86 ...
- vue+ vue-router + webpack 踩坑之旅
说是踩坑之旅 其实是最近在思考一些问题 然后想实现方案的时候,就慢慢的查到这些方案 老司机可以忽略下面的内容了 1)起因 考虑到数据分离的问题 因为server是express搭的 自然少 ...
随机推荐
- 半夜删你代码队 Day5冲刺
一.每日站立式会议 1.站立式会议 成员 昨日完成工作 今日计划工作 遇到的困难 陈惠霖 跟进作业 完成注册界面 相关界面设计内容知识不充足 侯晓龙 开始双人合作 开始与数据库结合 无 周楚池 初步完 ...
- 剑指offer二刷——数组专题——斐波那契数列
题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0,第1项是1). n<=39 我的想法 斐波那契数列定义:F(0)=0,F(1)=1, ...
- vue props默认值国际化报错
未做国际化处理 tabLabel: { type: Array, default: () => (["a", "b", "c"]) } ...
- 【APIO2019】路灯(ODT & (树套树 | CDQ分治))
Description 一条 \(n\) 条边,\(n+1\) 个点的链,边有黑有白.若结点 \(a\) 可以到达 \(b\),需要满足 \(a\to b\) 的路径上的边不能有黑的.现给出 \(0\ ...
- MySQL技术内幕InnoDB存储引擎(三)——文件相关
构成MySQL数据库和InnoDB存储引擎表的文件类型有: 参数文件:MySQL实例运行时需要的参数就是存储在这里. 日志文件:用来记录MySQL实例对某种条件做出响应时写入的文件. socket文件 ...
- sort by背后使用了什么排序算法
用到了快速排序,但不仅仅只用了快速排序,还结合了插入排序和堆排序 搬运自https://blog.csdn.net/qq_35440678/article/details/80147601
- Azure应用服务+Github实现持续部署
上次我们介绍了如何使用Azure应用服务(不用虚机不用Docker使用Azure应用服务部署ASP.NET Core程序).我们通过Visual studio新建一个项目后手动编译发布代码.然后通过F ...
- linux下/etc/profile /etc/bashrc /root/.bashrc /root/.bash_profile这四个配置文件的加载顺序
目录 一.关于linux配置文件 二.验证四个配置文件的加载顺序 三.结论 一.关于linux配置文件 1.linux下主要有四个配置文件:/etc/profile ./etc/bashrc ./ro ...
- 【ubuntu-18.04】ubuntu18.04进行Nvidia显卡配置
转自https://blog.csdn.net/qq_37935670/article/details/80377196 2.显卡驱动配置 网上有些攻略非常非常复杂,又要禁用nouveau驱动,又要进 ...
- day111:MoFang:邀请好友流程&生成邀请好友二维码&第三方应用识别二维码&本地编译测试&记录邀请人信息
目录 1.邀请业务逻辑流程图 2.邀请好友-前端 3.邀请好友-后端接口(生成二维码) 4.前端获取后端生成的二维码 5.前端长按页面,保存图片到相册 6.客户端通过第三方识别微信二维码,服务端提供对 ...