python 爬取腾讯视频的全部评论
一、网址分析
查阅了网上的大部分资料,大概都是通过抓包获取。但是抓包有点麻烦,尝试了F12,也可以获取到评论。以电视剧《在一起》为例子。评论最底端有个查看更多评论猜测过去应该是 Ajax 的异步加载。
网上的大部分都是构建评论的网址,通过 requests 获取,正则表达式进行数据处理。本文也利用该方法进行数据处理,其实利用 scrapy 会更简单。
根据前辈给出的经验,顺利找到了评论所在的链接。

在新标签中打开,该网址的链接。

评论都在"content":"xxxxx"里面,所有可以通过正则表达式获取。
那么现在要开始构建网址,找到其规律。
在查找评论链接的过程中无意发现,点击影评旁边的评论总数,可以获取到更为干净的评论界面。结果是一样的。
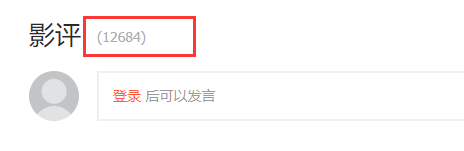
既然是要爬取所有的评论,所以知道评论数是必不可少的。

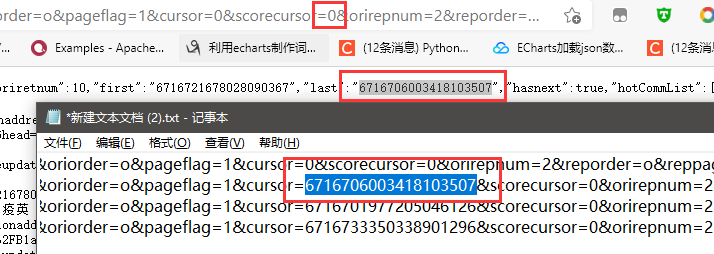
再通过F12获取到评论链接,找到网址的规律,构建网址,加载三四个评论就行了。这里加载了四个网址。把所有网址复制到文本文件中,进行对比分析。

观察发现只有 cursor 和 source 进行了改变,其他是不变的,二 source 是在第一个的基础上进行加一操作,所以只需要获取到 cursor 即可。我们打开一个评论链接的网址,我们可以知道,cursor 其实是上一页 最后一个用户的ID码。所以我们只需要在爬取上一页的时候一起爬虫了。然后就可以构建网址。
二、代码编写
这个代码还是简单的。套用之前上课做的模板就可以直接进行爬虫了。
通过正则表达式获取评论,返回一个列表;
正则表达式获得的 cursor 码是列表,所以要转化为字符串使用;
source 很简单了,直接在上一个的基础上加一即可。
def getComment(html): # 爬取单页评论
findeComment = re.compile(r'"content":"(.*?)"', re.S)
comment = re.findall(findeComment, html)
# print(comment)
return comment
def getCursor(html): # 获取下一页的cursor码
findeCursor = re.compile(r'"last":"(.*?)"', re.S)
cursor = re.findall(findeCursor, html)[0]
# print(cursor)
return cursor
def getSource(source): # 获取下一页的source码
source = int(source) + 1
return str(source)
有点难度的可能就送弄代理吧,但是代理可以模仿网上其他人的写法,所以还是不是很难。
#添加用户代理
def ua(uapools):
thisua = random.choice(uapools)
# print(thisua)
headers = ("User-Agent", thisua)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 设置为全局变量
urllib.request.install_opener(opener)
三、遇到的问题
1. 获取评论的时候也将子评论爬虫进去了。
仔细查看了源码,发现评论主要在 data 下面的 oriCommList 列表里,其他范围的评论为子评论。个人认为子评论也算有效评论,目前不打算处理。

2. 获取全部评论数,直接通过 requests 获取不到
尝试了 xpath 和 requests 发现不能获取全部评论数,所以目前只能通过 selenium 获取,但是 selenium 效率太低了,就获取一个评论总数,还不如打开源码直接修改评论总数,所以暂时没有修改
3. 评论总数数据太大
因为之前爬虫过很多网站,同一个 user-agent 很容易被 ban ,所以目前构建了用户代理,然后进行随机。其实还想加一个 ip 代理的,但是使用了 ip 代理的网址,上面写的正常的 ip ,在使用的时候,拒绝连接。也尝试过构建代理池。但是代理池一般都是使用docker 和 Redis 进行获取。暂时没有选用,之选用了用户代理,然后在获取 headers 的时候加个 time.sleep(1)。目前还是正常的。
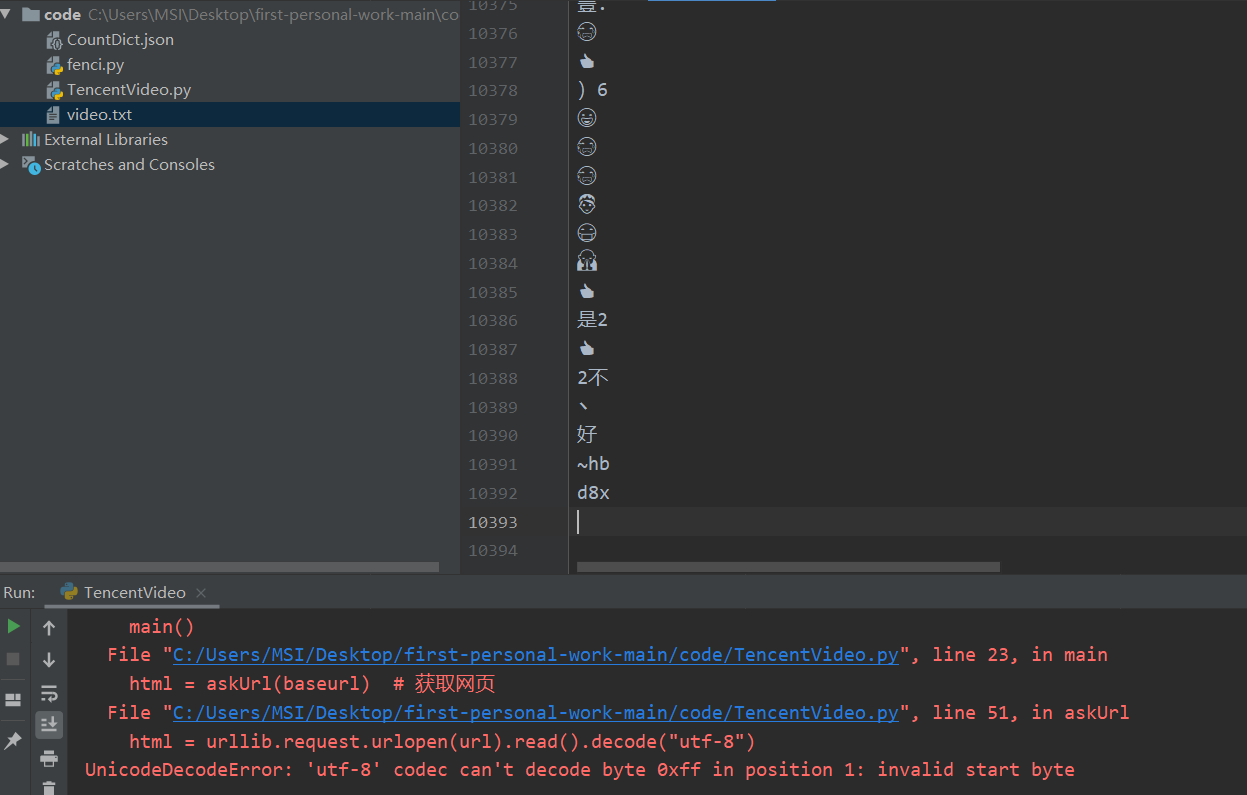
4. 报错'utf-8' codec can't decode byte 0xff in position 1: invalid start byte
遇到这个问题,实在无语,我怀疑后面的评论是新出的 emjoy,然后utf-8不能识别,程序挂掉了。但是选取其他格式,在解释的过程估计还会挂掉,就暂时爬到1万条吧。
四、完整代码
参考资料
Python爬虫实战:爬取腾讯视频的评论
python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
应对反爬虫最简单的策略——随机UA+递归request
python 爬取腾讯视频的全部评论的更多相关文章
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- Python爬取某短视频热点
写在前面的一些话: 随着短视频的大火,不仅可以给人们带来娱乐,还有热点新闻时事以及各种知识,刷短视频也逐渐成为了日常生活的一部分.本文以一个简单的小例子,简述如何通过Pyhton依托Selenium来 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- Python 爬取腾讯招聘职位详情 2019/12/4有效
我爬取的是Python相关职位,先po上代码,(PS:本人小白,这是跟着B站教学视频学习后,老师留的作业,因为腾讯招聘的网站变动比较大,老师的代码已经无法运行,所以po上),一些想法和过程在后面. f ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- Python爬取抖音视频
最近在研究Python爬虫,顺便爬了一下抖音上的视频,找到了哥们喜欢的小姐姐居多,咱们给他爬下来吧. 最终爬取结果 好了废话补多说了,上代码! #https://www.iesdouyin.com/a ...
随机推荐
- Python干货:了解元组与列表的使用和区别
元组是 Python 对象的集合,跟列表十分相似.下面进行简单的对比. 列表与元组 1.python中的列表list是变量,而元组tuple是常量. 列表:是使用方括号[],元组:则是使用圆括号() ...
- click的简单使用
click的简单使用 先通过一个简单的例子来认知一下click把 import click @click.command() @click.option('-p', '--port', default ...
- (06)-Python3之--判断、循环
1.判断(if) 语法: if 条件(True/False): 条件为真时,执行的代码(要干的事情)[elif 条件: 条件为真时,执行的代码(要干的事情)elif 条件: 条件为真时,执行的代码(要 ...
- (03)-Python3之--元组(tuple)操作
1.定义 元组的关键字:tuple 元组以()括起来,数据之间用 , 隔开.元组当中的数据,可以是任意类型.数值是可以重复的. 元组元素是 不可变的,顺序是 有序的. 例如: b = ("萝 ...
- C#高级编程第11版 - 第三章 索引
[1]3.1 创建及使用类 1.构造函数:构造函数的名字与类名相同: 使用 new 表达式创建类的对象或者结构(例如int)时,会调用其构造函数.并且通常初始化新对象的数据成员. 除非类是静态的,否则 ...
- hive搜索报错
在自己搭建的集群上执行hive搜索语句 select count(*) from ods_event_log where dt='2019-12-14' group by dt; 报错如下: Stat ...
- GRPC Health Checking Protocol Unavailable 14
https://github.com/grpc/grpc/blob/master/doc/health-checking.md GRPC Health Checking Protocol Health ...
- Java实现windows,linux服务器word,excel转为PDF;aspose-words,Documents4j
Java实现windows,linux服务器word,excel转为PDF:aspose-words,Documents4j 一.通过aspose-words将word,Excel文档转为PDF 1. ...
- Centos7安装成功后,网卡配置及更改镜像地址为国内镜像
Centos7安装成功后,网卡配置及更改镜像地址为国内镜像 一.网卡配置 二.修改网络配置 踩坑一:IPADDR 踩坑二:网关,DNS与本地不一致 重启网络服务 三.镜像修改为aliyun 四.相关知 ...
- chrome标签记录——关于各类性能优化
概述 详情 概述 平时经常浏览各大博客,总感觉要学习和需要学习的内容太多太多,而自己的个人能力还不足够写出一些好的文章出来,就只能通过学习他人的东西不断提升自己的实力,然后就会记录收藏各种优秀的博客资 ...