python 爬取腾讯视频的全部评论
一、网址分析
查阅了网上的大部分资料,大概都是通过抓包获取。但是抓包有点麻烦,尝试了F12,也可以获取到评论。以电视剧《在一起》为例子。评论最底端有个查看更多评论猜测过去应该是 Ajax 的异步加载。
网上的大部分都是构建评论的网址,通过 requests 获取,正则表达式进行数据处理。本文也利用该方法进行数据处理,其实利用 scrapy 会更简单。
根据前辈给出的经验,顺利找到了评论所在的链接。

在新标签中打开,该网址的链接。

评论都在"content":"xxxxx"里面,所有可以通过正则表达式获取。
那么现在要开始构建网址,找到其规律。
在查找评论链接的过程中无意发现,点击影评旁边的评论总数,可以获取到更为干净的评论界面。结果是一样的。
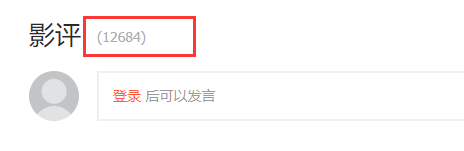
既然是要爬取所有的评论,所以知道评论数是必不可少的。

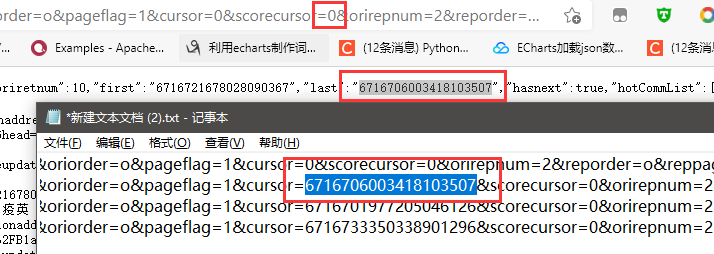
再通过F12获取到评论链接,找到网址的规律,构建网址,加载三四个评论就行了。这里加载了四个网址。把所有网址复制到文本文件中,进行对比分析。

观察发现只有 cursor 和 source 进行了改变,其他是不变的,二 source 是在第一个的基础上进行加一操作,所以只需要获取到 cursor 即可。我们打开一个评论链接的网址,我们可以知道,cursor 其实是上一页 最后一个用户的ID码。所以我们只需要在爬取上一页的时候一起爬虫了。然后就可以构建网址。
二、代码编写
这个代码还是简单的。套用之前上课做的模板就可以直接进行爬虫了。
通过正则表达式获取评论,返回一个列表;
正则表达式获得的 cursor 码是列表,所以要转化为字符串使用;
source 很简单了,直接在上一个的基础上加一即可。
def getComment(html): # 爬取单页评论
findeComment = re.compile(r'"content":"(.*?)"', re.S)
comment = re.findall(findeComment, html)
# print(comment)
return comment
def getCursor(html): # 获取下一页的cursor码
findeCursor = re.compile(r'"last":"(.*?)"', re.S)
cursor = re.findall(findeCursor, html)[0]
# print(cursor)
return cursor
def getSource(source): # 获取下一页的source码
source = int(source) + 1
return str(source)
有点难度的可能就送弄代理吧,但是代理可以模仿网上其他人的写法,所以还是不是很难。
#添加用户代理
def ua(uapools):
thisua = random.choice(uapools)
# print(thisua)
headers = ("User-Agent", thisua)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 设置为全局变量
urllib.request.install_opener(opener)
三、遇到的问题
1. 获取评论的时候也将子评论爬虫进去了。
仔细查看了源码,发现评论主要在 data 下面的 oriCommList 列表里,其他范围的评论为子评论。个人认为子评论也算有效评论,目前不打算处理。

2. 获取全部评论数,直接通过 requests 获取不到
尝试了 xpath 和 requests 发现不能获取全部评论数,所以目前只能通过 selenium 获取,但是 selenium 效率太低了,就获取一个评论总数,还不如打开源码直接修改评论总数,所以暂时没有修改
3. 评论总数数据太大
因为之前爬虫过很多网站,同一个 user-agent 很容易被 ban ,所以目前构建了用户代理,然后进行随机。其实还想加一个 ip 代理的,但是使用了 ip 代理的网址,上面写的正常的 ip ,在使用的时候,拒绝连接。也尝试过构建代理池。但是代理池一般都是使用docker 和 Redis 进行获取。暂时没有选用,之选用了用户代理,然后在获取 headers 的时候加个 time.sleep(1)。目前还是正常的。
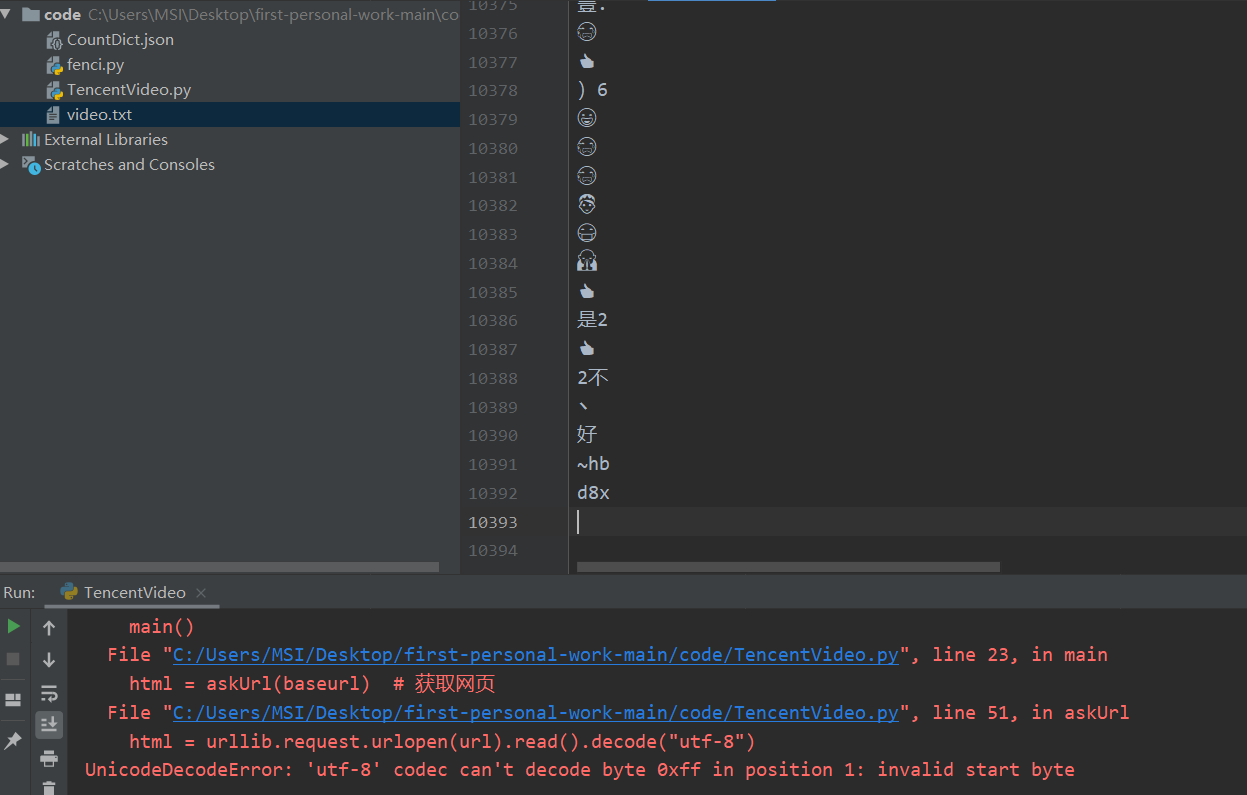
4. 报错'utf-8' codec can't decode byte 0xff in position 1: invalid start byte
遇到这个问题,实在无语,我怀疑后面的评论是新出的 emjoy,然后utf-8不能识别,程序挂掉了。但是选取其他格式,在解释的过程估计还会挂掉,就暂时爬到1万条吧。
四、完整代码
参考资料
Python爬虫实战:爬取腾讯视频的评论
python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
应对反爬虫最简单的策略——随机UA+递归request
python 爬取腾讯视频的全部评论的更多相关文章
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- Python爬取某短视频热点
写在前面的一些话: 随着短视频的大火,不仅可以给人们带来娱乐,还有热点新闻时事以及各种知识,刷短视频也逐渐成为了日常生活的一部分.本文以一个简单的小例子,简述如何通过Pyhton依托Selenium来 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- Python 爬取腾讯招聘职位详情 2019/12/4有效
我爬取的是Python相关职位,先po上代码,(PS:本人小白,这是跟着B站教学视频学习后,老师留的作业,因为腾讯招聘的网站变动比较大,老师的代码已经无法运行,所以po上),一些想法和过程在后面. f ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- Python爬取抖音视频
最近在研究Python爬虫,顺便爬了一下抖音上的视频,找到了哥们喜欢的小姐姐居多,咱们给他爬下来吧. 最终爬取结果 好了废话补多说了,上代码! #https://www.iesdouyin.com/a ...
随机推荐
- 解决windows与虚拟机ubuntu互相ping不通的问题
工作中经常用Ubuntu开发,而Ubuntu是安装在虚拟机中的,在弄网络开发的时候经常会用windows下的网络调试工具与Ubuntu中写好的网络程序进行通信,首先要保证windows与Ubuntu能 ...
- Rancher On K3s 高可用架构部署
Rancher 推荐部署架构 k3s 模式 RKE 和 k8s 模式 备注: 我对 RKE 的理解就是 Ansible + kubeadm 的打包,首先 rke 需要到每一个节点都可以免密 ssh , ...
- Hmailserver搭建邮箱服务器
由于阿里云,谷歌云,腾讯云等服务器都不开放25端口和pop3端口,想要使用邮箱服务得购买他们的企业邮箱,但是对于个人而言比较贵. 所以我们需要利用家庭宽带申请公网IP. 首先打电话给运营商客服,申请动 ...
- ChannelNets: 省力又讨好的channel-wise卷积,在channel维度进行卷积滑动 | NeurIPS 2018
Channel-wise卷积在channel维度上进行滑动,巧妙地解决卷积操作中输入输出的复杂全连接特性,但又不会像分组卷积那样死板,是个很不错的想法 来源:晓飞的算法工程笔记 公众号 论文: C ...
- RSA2对于所有商户都是单独一对一的,并且只支持开发平台密钥管理和沙箱
蚂蚁金服开发者社区 https://openclub.alipay.com/club/history/read/1495 RSA 和 RSA2 签名算法区别 - 支付宝开放平台 https://ope ...
- 20201103gryz模拟赛解题报告
写在前面 昨天忘写了来补上 T1位运算乱搞一会没搞出来, 打完T4floyd暴力分之后发现T2树状数组可以骗点分 打完T3暴力手模了一遍样例之后发现T3就是个线段树板子 最后就非常愉快的拿到175pt ...
- redis学习教程五《管道、分区》
redis学习教程五<管道.分区> 一:管道 Redis是一个TCP服务器,支持请求/响应协议. 在Redis中,请求通过以下步骤完成: 客户端向服务器发送查询,并从套接字读取,通常以阻 ...
- 深信服edr控制中心漏洞——验证码逻辑错误
验证码逻辑错误 文件:tool/log/l.php的第93行
- Hive 报错
hadoop hive任务失败,原因是GC overhead limit exceeded (OOM) GC Overhead Limit Exceeded error是java.lang.OutOf ...
- log4cplus安装测试
先介绍一下它的基本要素. Layouts :布局器,控制输出消息的格式. Appenders :挂接器,与布局器紧密配合,将特定格式的消息输出到所挂接的设备终端 (如屏幕,文件等等). Logge ...