一层逻辑的网页scrapy爬虫
1 import scrapy
2 import re
3 from fake_useragent import UserAgent
4
5
6 class DoubanSpider(scrapy.Spider):
7 name = "douban"
8 start_urls = ['https://movie.douban.com/top250', ]
9 custom_settings = {"USER_AGENT": UserAgent().random}
10
11 def parse(self, response):
12 for movie in response.xpath("//ol[@class='grid_view']/li"):
13
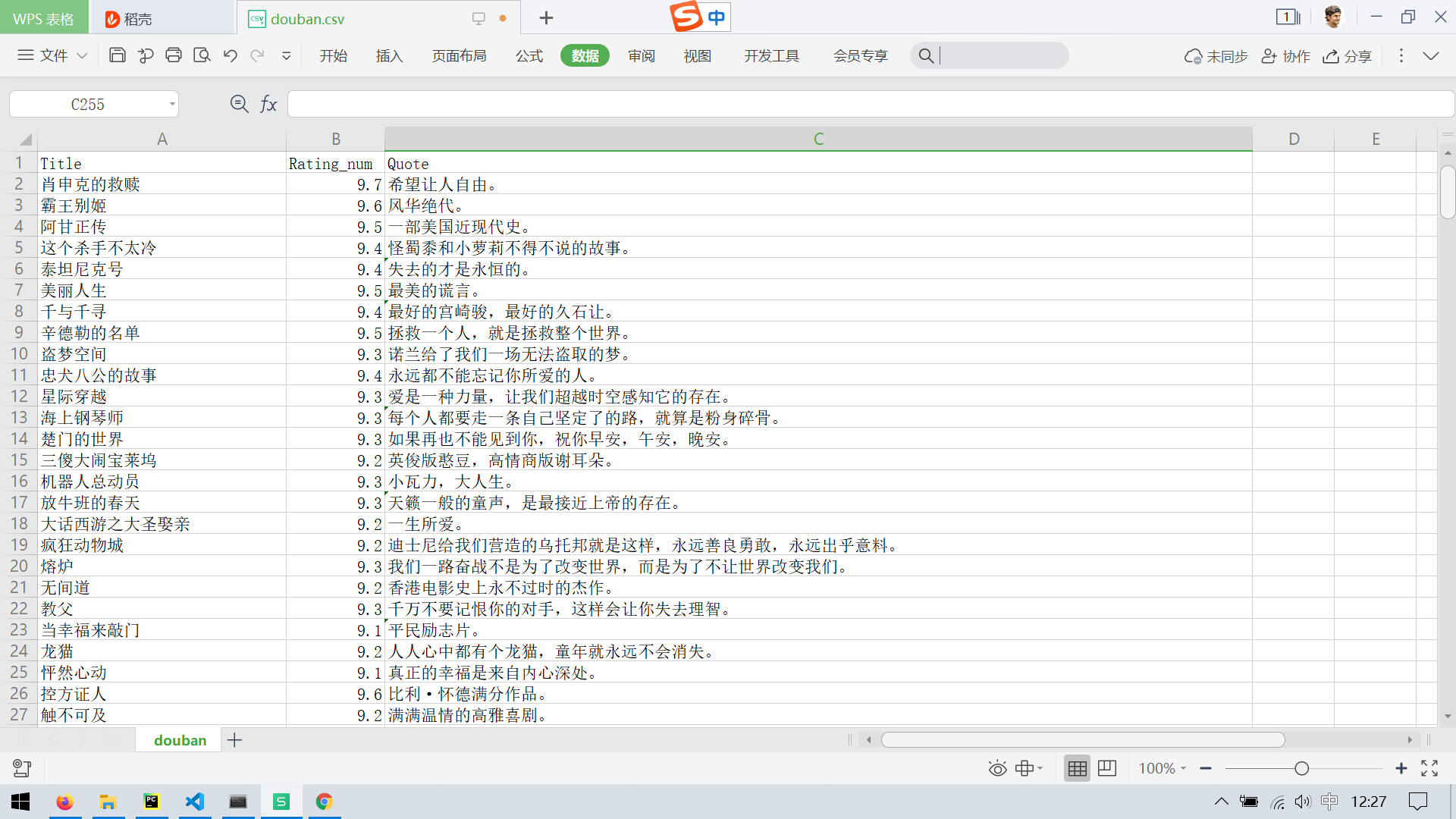
14 yield {
15 'Title': movie.xpath(".//span[@class='title']/text()").get(),
16 'Rating_num': movie.xpath(".//span[@class='rating_num']/text()").get(),
17 'Quote': movie.xpath(".//p[@class='quote']/span/text()").get()
18 }
19
20 next_page = response.xpath("//span[@class='next']/a/@href").get()
21 if next_page is not None:
22 yield response.follow(next_page, callback=self.parse)
scrapy runspider douban一层能解决.py -o douban.csv
一层逻辑的网页scrapy爬虫的更多相关文章
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- scrapy爬虫具体案例步骤详细分析
scrapy爬虫具体案例详细分析 scrapy,它是一个整合了的爬虫框架, 有着非常健全的管理系统. 而且它也是分布式爬虫, 它的管理体系非常复杂. 但是特别高效.用途广泛,主要用于数据挖掘.检测以及 ...
- scrapy爬虫具体案例详细分析
scrapy爬虫具体案例详细分析 scrapy,它是一个整合了的爬虫框架, 有着非常健全的管理系统. 而且它也是分布式爬虫, 它的管理体系非常复杂. 但是特别高效.用途广泛,主要用于数据挖掘.检测以及 ...
- Scrapy 爬虫项目框架
1. Scrapy 简介 2. Scrapy 项目开发介绍 3. Scrapy 项目代码示例 3.1 setting.py:爬虫基本配置 3.2 items.py:定义您想抓取的数据 3.3 spid ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
- Scrapy爬虫大战京东商城
Scrapy爬虫大战京东商城 引言 上一篇已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇 代码详解 首先应该构造请求,这里使用scrapy.Request,这个方法默认调 ...
随机推荐
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- 使用 requests.post 方法抓取有道翻译结果
import requests as rq import json def get_translate(word=None): url = 'http://fanyi.youdao.com/trans ...
- HDOJ 1028 母函数分析
#include<iostream>#include<cstring>using namespace std;int main(){ int c1[10000],c2[1 ...
- AtCoder Beginner Contest 170
比赛链接:https://atcoder.jp/contests/abc170 A - Five Variables 题意 $5$ 个数中有 $1$ 个 $0$,判断是第几个. 代码 #include ...
- 分组背包 例题:hdu 1712 ACboy needs your help
分组背包需求 有N件物品,告诉你这N件物品的重量以及价值,将这些物品划分为K组,每组中的物品互相冲突,最多选一件,求解将哪些物品装入背包可使这些物品的费用综合不超过背包的容量,且价值总和最大. 解题模 ...
- hdu2818 Building Block
Problem Description John are playing with blocks. There are N blocks (1 <= N <= 30000) numbere ...
- java——类、对象、private、this关键字
一.定义 二.类的使用 实例:定义的类要在一个class文件内,实例化类的对象要在另一个文件内 类文件: 实例文件: 对象内存图: 先主函数入栈,之后新开一个对象存入堆内存中,之后调用的call方法 ...
- 母函数 <普通母函数(HDU - 1028 ) && 指数型母函数(hdu1521)>
给出我初学时看的文章:母函数(对于初学者的最容易理解的) 普通母函数--------->HDU - 1028 例题:若有1克.2克.3克.4克的砝码各一 枚,能称出哪几种重量?各有几种可能方案? ...
- Strongly connected HDU - 4635 原图中在保证它不是强连通图最多添加几条边
1 //题意: 2 //给你一个有向图,如果这个图是一个强连通图那就直接输出-1 3 //否则,你就要找出来你最多能添加多少条边,在保证添加边之后的图依然不是一个强连通图的前提下 4 //然后输出你最 ...
- hdu5402 Travelling Salesman Problem
Problem Description Teacher Mai is in a maze with n rows and m columns. There is a non-negative numb ...