HDFS 01 - HDFS是什么?它的适用场景有哪些?它的架构是什么?
1、HDFS 是什么
1.1 简单介绍
在现代的企业环境中,单机容量太小,无法存储海量的数据,这时候就需要多机器存储。
—— 统一管理分布在集群上的文件,这样的系统就称为分布式文件系统。
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统),是 Apache Hadoop 项目的一个子项目。
我们知道,Hadoop 天生就是为了存储海量数据(比如 TB 和 PB级别)而设计的,它的存储系统就是 HDFS。
HDFS 使用多台计算机存储文件,并提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
1.2 发展历史
Doug Cutting 在做 Lucene 的时候,需要编写一个爬虫服务,过程中遇到了一些问题,诸如:如何存储大规模的数据,如何保证集群的可伸缩性,如何动态容错等。
2003年的时候,Google 发布了三篇论文,被称作为三驾马车,其中有一篇叫做 GFS,描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统,具有强大的可伸缩性和容错性。
Doug Cutting 后来根据 GFS 的论文, 创造了一个新的文件系统, 叫做 HDFS
2、HDFS 应用场景
2.1 适合的应用场景
- 存储非常大的文件:这里非常大指的是成百上千 MB、GB,甚至 TB 级别的文件,需要高吞吐量,对延时没有要求。
- 采用流式的数据访问方式:即 一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作。
- 运行于廉价的硬件上:不需要性能特别高的机器,可运行于普通廉价机器,节约成本。
- 需要高容错性,HDFS 有多副本机制,丢失/损坏一定个数的副本后,不影响文件的完整性。
- 用作数据存储系统,方便横向扩展。
2.2 不适合的应用场景
低延时的数据访问:对延时要求在毫秒级别的应用,不适合采用 HDFS。HDFS 是为高吞吐数据传输设计的,延时较高。
大量小文件:HDFS 系统中,文件的元数据保存在 NameNode 的内存中, 文件数量会受限于 NameNode 的内存大小。
通常,一个文件/目录/文件块的元数据内存空间约=150Byte。如果有100万个文件,每个文件占用1个 block,则需要大约300MB的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
多方读写,需要任意的文件修改:HDFS采用追加(append-only)的方式写入数据。不支持文件任意 offset 的修改,也不支持多个写入器(writer)。
3、HDFS 的架构
HDFS是一个 主/从(Mater/Slave)体系结构,HDFS由四部分组成,分别是:
HDFS Client、NameNode、DataNode 和 SecondaryNameNode。
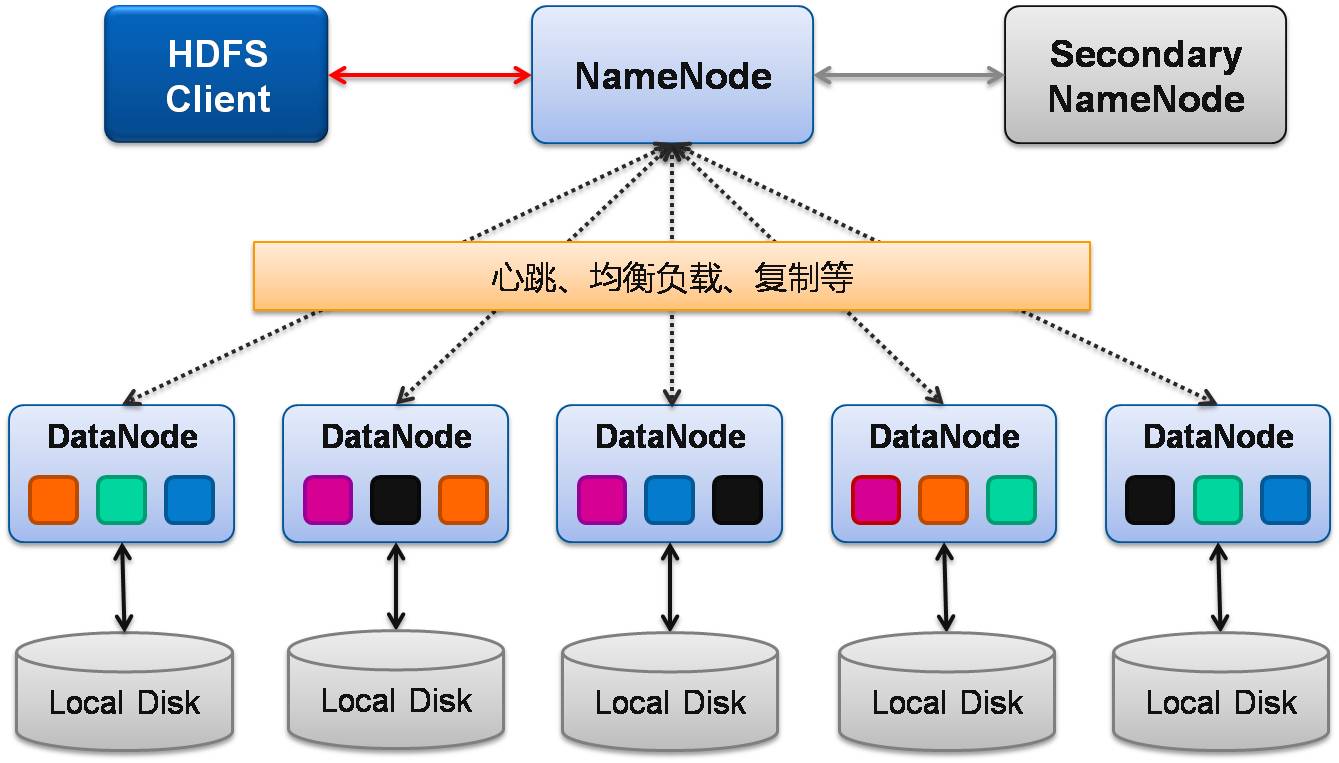
1、Client:就是客户端。
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成多个块(block),然后存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取、写入数据。
- Client 提供一些命令来管理和访问 HDFS,比如启动、关闭 HDFS。
2、NameNode:就是 master,是管理者。
- 管理 HDFS 的名称空间。
- 管理数据块(block)映射信息。
- 配置副本策略。
- 处理客户端的读写请求。
3、DataNode:就是 Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
4、Secondary NameNode:不是 NameNode 的热备份 —— NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage 和 fsedits,并推送给 NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
4、NameNode 和 DataNode
4.1 NameNode 的作用
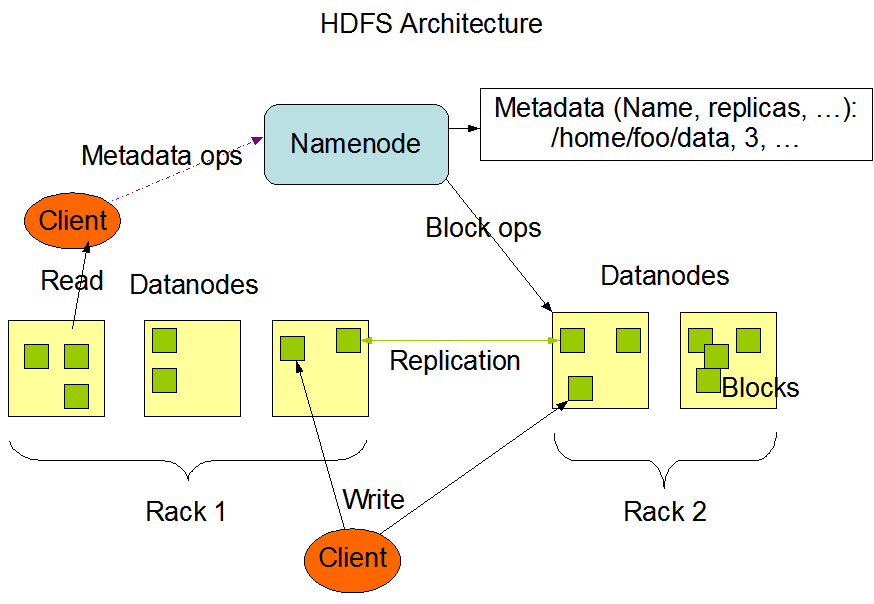
NameNode 在内存中保存着整个文件系统的名称空间和文件数据块的地址映射。
HDFS 集群可存储的文件个数受限于 NameNode 的内存大小 。
1、NameNode 存储元数据信息
元数据包括:文件名,文件目录结构,文件属性(生成时间、副本数、权限等),每个文件的块列表,以及列表中的块与块所在的DataNode 之间的地址映射关系;
在内存中加载每个文件和每个数据块的引用关系(文件、block、DataNode之间的映射信息);
数据会定期保存到本地磁盘(fsImage 文件和 edits 文件)。
2、NameNode 文件元数据的操作
DataNode 负责处理文件内容的读写请求,数据流不会经过 NameNode,而是从 NameNode 获取数据真正要流向的 DataNode。
3、NameNode 副本
文件数据块到底存放到哪些 DataNode 上,是由 NameNode 决定的,它会根据全局的情况(机架感知机制),做出副本存放位置的决定。
4、NameNode 心跳机制
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
若接受到心跳信息,NameNode认为DataNode工作正常,如果在10分钟后还接受到不到DN的心跳,那么NameNode认为DataNode已经宕机 ,这时候NN准备要把DN上的数据块进行重新的复制。 块的状态报告包含了一个DN上所有数据块的列表,blocks report 每个1小时发送一次.
4.2 DataNode 的作用
提供真实文件数据的存储服务。
DataNode 以数据块的形式存储 HDFS 文件
DataNode 响应 HDFS 客户端的读写请求
DataNode 周期性向 NameNode 汇报心跳信息
DataNode 周期性向 NameNode 汇报数据块信息
DataNode 周期性向 NameNode 汇报缓存数据块信息
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注
HDFS 01 - HDFS是什么?它的适用场景有哪些?它的架构是什么?的更多相关文章
- 01 HDFS 简介
01.HDFS简介 大纲: hadoop2 介绍 HDFS概述 HDFS读写流程 hadoop2介绍 框架的核心设计是HDFS(存储),mapReduce(分布式计算),YARN(资源管理),为海量的 ...
- HDFS系列 -- HDFS预研
1 HDFS概述 由于传统集中式的物理服务器在存储容量和数据传输速度等方面都有限制,故而越来越不符合这些数据的实际存储需要. 在大数据时代,大数据处理需要解决的首要问题是:如何高效地存储所产生的规模庞 ...
- HDFS设计思路,HDFS使用,查看集群状态,HDFS,HDFS上传文件,HDFS下载文件,yarn web管理界面信息查看,运行一个mapreduce程序,mapreduce的demo
26 集群使用初步 HDFS的设计思路 l 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: l 在大数据系统中作用: 为各类分布式 ...
- HDFS Federation(转HDFS Federation(HDFS 联盟)介绍 CSDN)
转载地址:http://blog.csdn.net/strongerbit/article/details/7013221 HDFS Federation(HDFS 联盟)介绍 1. 当前HDFS架构 ...
- HDFS 07 - HDFS 性能调优之 合并小文件
目录 1 - 为什么要合并小文件 2 - 合并本地的小文件,上传到 HDFS 3 - 合并 HDFS 的小文件,下载到本地 4 - 通过 Java API 实现文件合并和上传 版权声明 1 - 为什么 ...
- HDFS 10 - HDFS 的联邦机制(Federation 机制)
目录 1 - 为什么需要联邦 2 - Federation 架构设计 3 HDFS Federation 的不足 版权声明 1 - 为什么需要联邦 单 NameNode 的架构存在的问题:当集群中数据 ...
- 使用hue查看hdfs系统报无法访问:/user/hadoop。 Note: you are a Hue admin but not a HDFS superuser, "hdfs" or part of HDFS supergroup, "supergroup".
出现这个问题,是因为默认的超级用户是hdfs ,我的是hadoop用户登录的, 也就是说首次登录hadoop这个用户是我的超级用户 此时只需要将hue.ini配置改为 然后重启即可.
- HDFS二.HDFS实现分布式文件存储---体系结构
单击模式(Standalone): 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置.在这种默认模式下所有3个XML文件均为 ...
- java 操作hdfs(连接HDFS)
FileSystem fs = null; Configuration conf = null; @Before public void init() throws Exception{ conf = ...
随机推荐
- LOJ10065 北极通讯站
Waterloo University 2002 北极的某区域共有 n 座村庄,每座村庄的坐标用一对整数 (x,,y) 表示.为了加强联系,决定在村庄之间建立通讯网络.通讯工具可以是无线电收发机,也可 ...
- Java8中流的性能
流(Stream)是Java8为了实现最佳性能而引入的一个全新的概念.在过去的几年中,随着硬件的持续发展,编程方式已经发生了巨大的改变,程序的性能也随着并行处理.实时.云和其他一些编程方法的出现而得到 ...
- Docker (error getsockopt: connection refused ,使用http无法使用 docker login 登录的问题)
因部署Harbor 镜像仓库,部署完了之后根据提示上传 images,需要使用docker login ip:port 进行登录, 登录的时候发现因为docker 默认是https,因为测试环 ...
- HTTPS优化与证书
1.HTTPS性能优化 1.1 HTTPS性能损耗原因 前文讨论了HTTPS原理与优势:身份验证.信息加密与完整性校验等,且未对TCP和HTTP协议做任何修改.但通过增加新协议以实现更安全的通信必然需 ...
- Jenkins开启丢弃旧的构建?你可要小心啊!
玩Devops的小伙伴应该对Jenkins都有了解. Github上16.8k的Star的项目,1500+的构建.发布等自动化插件可供选择,事实上的业界CICD标准领导者. JFrog.Coding等 ...
- 浅谈Webpack模块打包工具一
为什么要使用模块打包工具 1.模块化开发ES Modules存在兼容性问题 打包之后成产阶段编译为ES5 解决兼容性问题 2.模块文件过多 网络请求频繁 开发阶段把散的模块打包成一个模块 解决网络请 ...
- HDU-6599 I Love Palindrome String(回文自动机+字符串hash)
题目链接 题意:给定一个字符串\(|S|\le 3\times 10^5\) 对于每个 \(i\in [1,|S|]\) 求有多少子串\(s_ls_{l+1}\cdots s_r\)满足下面条件 \( ...
- HDU-3499Flight (分层图dijkstra)
一开始想的并查集(我一定是脑子坏掉了),晚上听学姐讲题才知道就是dijkstra两层: 题意:有一次机会能使一条边的权值变为原来的一半,询问从s到e的最短路. 将dis数组开成二维,第一维表示从源点到 ...
- hdu 6814 Tetrahedron 规律+排列组合逆元
题意: 给你一个n,你需要从1到n(闭区间)中选出来三个数a,b,c(可以a=b=c),用它们构成一个直角四面体的三条棱(可看图),问你从D点到下面的三角形做一条垂线h,问你1/h2的期望 题解: 那 ...
- Best Reward && Girls' research
After an uphill battle, General Li won a great victory. Now the head of state decide to reward him w ...