TF-IDF算法介绍及实现
目录
1、TF-IDF算法介绍
(1)TF是词频(Term Frequency)
(2) IDF是逆向文件频率(Inverse Document Frequency)
(3)TF-IDF实际上是:TF * IDF
2、TF-IDF应用
3、Python3实现TF-IDF算法
4、NLTK实现TF-IDF算法
5、Sklearn实现TF-IDF算法
1、TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式: 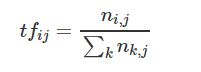
即:
其中 ni,j 是该词在文件 dj 中出现的次数,分母则是文件 dj 中所有词汇出现的次数总和;
(2) IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
公式: 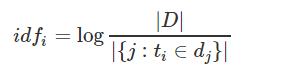
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|
即:
(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式: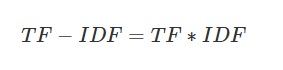
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
2、TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
3、Python3实现TF-IDF算法
# -*- coding: utf-8 -*-
from collections import defaultdict
import math
import operator
"""
函数说明:创建数据样本
Returns:
dataset - 实验样本切分的词条
classVec - 类别标签向量
"""
def loadDataSet():
dataset = [ ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ]
classVec = [0, 1, 0, 1, 0, 1] # 类别标签向量,1代表好,0代表不好
return dataset, classVec
"""
函数说明:特征选择TF-IDF算法
Parameters:
list_words:词列表
Returns:
dict_feature_select:特征选择词字典
"""
def feature_select(list_words):
#总词频统计
doc_frequency=defaultdict(int)
for word_list in list_words:
for i in word_list:
doc_frequency[i]+=1
#计算每个词的TF值
word_tf={} #存储没个词的tf值
for i in doc_frequency:
word_tf[i]=doc_frequency[i]/sum(doc_frequency.values())
#计算每个词的IDF值
doc_num=len(list_words)
word_idf={} #存储每个词的idf值
word_doc=defaultdict(int) #存储包含该词的文档数
for i in doc_frequency:
for j in list_words:
if i in j:
word_doc[i]+=1
for i in doc_frequency:
word_idf[i]=math.log(doc_num/(word_doc[i]+1))
#计算每个词的TF*IDF的值
word_tf_idf={}
for i in doc_frequency:
word_tf_idf[i]=word_tf[i]*word_idf[i]
# 对字典按值由大到小排序
dict_feature_select=sorted(word_tf_idf.items(),key=operator.itemgetter(1),reverse=True)
return dict_feature_select
if __name__=='__main__':
data_list,label_list=loadDataSet() #加载数据
features=feature_select(data_list) #所有词的TF-IDF值
print(features)
print(len(features))
运行结果:
4、NLTK实现TF-IDF算法
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
#首先,构建语料库corpus
sents=['this is sentence one','this is sentence two','this is sentence three']
sents=[word_tokenize(sent) for sent in sents] #对每个句子进行分词
print(sents) #输出分词后的结果
corpus=TextCollection(sents) #构建语料库
print(corpus) #输出语料库
#计算语料库中"one"的tf值
tf=corpus.tf('one',corpus) # 1/12
print(tf)
#计算语料库中"one"的idf值
idf=corpus.idf('one') #log(3/1)
print(idf)
#计算语料库中"one"的tf-idf值
tf_idf=corpus.tf_idf('one',corpus)
print(tf_idf)
运行结果:
5、Sklearn实现TF-IDF算法
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# 将语料转化为词袋向量,根据词袋向量统计TF-IDF
vectorizer = CountVectorizer(max_features=5000)
tf_idf_transformer = TfidfTransformer()
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
x_train_weight = tf_idf.toarray() # 训练集TF-IDF权重矩阵
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
TF-IDF算法介绍及实现的更多相关文章
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- [RN] React Native 使用 Redux 比较详细和深刻的教程
React Native 使用 Redux 比较详细和深刻的教程 React Native 使用 Redux https://www.jianshu.com/p/06fc18cef56a http:/ ...
- 前端Vue项目——课程详情页面实现
一.详情页面路由跳转 应用 Vue Router 编程式导航通过 this.$router.push() 来实现路由跳转. 1.绑定查看详情事件 修改 src/components/Course/Co ...
- [LeetCode] 43. Multiply Strings 字符串相乘
Given two non-negative integers num1 and num2represented as strings, return the product of num1 and ...
- 这些个适合oier的网站丫太有趣了吧(不定期更新中)(update.2019年11月1日)
//部分来源于:Sophon 的博客 .Smoggy 的博客.lahlah 的空间. //大佬大佬%%%↗↗↗ oier必备!!!(你值得拥有d=====( ̄▽ ̄*)b) 骗分导论 - Vijos V ...
- oracle--错误笔记(二)--ORA-16014
ORA-16014错误解决办法 01.问题以及解决过程 SQL> select status from v$instance; STATUS ------------ MOUNTED SQL&g ...
- JVM系列之七:HotSpot 虚拟机
1. 对象的创建 1. 遇到 new 指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载.解析和初始化过.如果没有,执行相应的类加载. 2 ...
- IntelliJ IDEA最新版2019年注册码,可激活至2099年 激活 破解
IntelliJ IDEA最新版2019年注册码,可激活至2099年 激活 破解 特别说明:图中的IDEA是2017版本,不过方法对2019版本的IDEA同样适用! 最近笔者测试了好多破解Idea的方 ...
- Scala字符串插值 - StringContext
翻译自:STRING INTERPOLATION 简介 自2.10.0版本开始,Scala提供了一种新的机制来根据数据生成字符串:字符串插值.字符串插值允许使用者将变量引用直接插入处理过的字面字符中. ...
- c++中char类型的取值范围
-128~127,数字在计算机中以补码形式存储,因为正数的补码就是其本身且正数符号位置0,故最大值为01111111(一个0七个1)也就是127 而负数是对应正数值取反加一,拿最大的负数-1来说,就是 ...
- 用欧拉计划学习Rust编程(第13~16题)
最近想学习Libra数字货币的MOVE语言,发现它是用Rust编写的,所以先补一下Rust的基础知识.学习了一段时间,发现Rust的学习曲线非常陡峭,不过仍有快速入门的办法. 学习任何一项技能最怕没有 ...