SIGAI机器学习第二十集 AdaBoost算法1
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用
AdaBoost算法将用三节课来讲,ANN、SVM、AdaBoost这三种算法都是用三节课来讲,因为这三种算法都非常重要,都有一些成功的应用。AdaBoost和SVM一样整个理论的根基是非常完善的,而且他们都是从1995年左右开始出现,在出现的十几年里边他们都得到了成功的应用。
随即森林它是一种称为Bagging集成学习算法的具体的一种实现,而AdaBoost它是Boosting算法的一种具体的实现。
大纲:
再论集成学习算法
Boosting算法简介
AdaBoost算法简介
训练算法
训练算法的解释
与随机森林的比较
训练误差分析
再论集成学习算法:
集成学习它是整个机器学习里边的一种思想,而不是某一种具体的算法,它有很多种不同的实现,比如说随机森林、AdaBoost,都是集成学习算法具体的实现。
集成学习的精髓:是一种思想,而不是一种具体的算法,有多种不同的实现方案。预测时,依靠多个弱学习器进行预测,投票,加权。训练时,要用原始的训练集构造每个弱学习器的训练集,采样,加权。
典型实现:Bagging与Boosting。
把一些不靠谱精度不是很高的模型,组合起来,能形成一个精度大有提升的一个模型,这是集成学习一个最根本的思想。
Boosting算法简介:
Boosting算法采用了随机采样。
训练算法:每次训练一个弱分类器时,有一部分样本是被上一个弱分类器错分的,这样使得后面的弱分类器重点关注难分的样本。
预测算法:和随机森林是一样的,最后的预测结果是各个弱分类器的预测结果投票。
AdaBoost算法简介:
全称是Adaptive Boosting,自适应提升算法,是一种二分类算法,只能用于分类问题,是Boosting算法的一种实现。
用弱分类器的线性组合来构造强分类器,预测的时候根据强分类器来预测。
弱分类器不用太精确,只要保证准确率大于0.5即可,即比随机猜测要强。
弱分类器的准确率是可以保证的,对于二分类问题,如果准确率低于0.5,只要将预测结果反转即可。
样本标签值为+1和-1。
强分类器: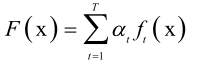 其中,at是一个加权系数,at、ft(x)都是通过训练算法来确定的,T通过实验、人为的经验或其他判断条件来确定的。
其中,at是一个加权系数,at、ft(x)都是通过训练算法来确定的,T通过实验、人为的经验或其他判断条件来确定的。
最后用一个符号函数来做分类 :sgn(F(x)),符号函数,大于0为+1,小于0为-1。
训练算法:
要解决的核心问题:弱分类器,弱分类器权重。
给定l个训练样本(xi,yi),其中Xi是特征向量,yi为类别标签,其值为+1或-1。初始化样本权重值,所有样本的初始权重(弱分类器是有权重a的,训练样本也是有权重的,这是AdaBoost算法的一个显著特征)相等:wi0=1/l, i=1,...,l,其中0表示迭代次数下标,i表示第i个样本。
循环,对t=1,...,T依次训练每个弱分类器:

即第t个弱分类器更加注重对被第t-1个弱分类器错分的样本(对应的样本权重大),而且如果第t个弱分类器分类效果好即分类误差小则该分类器对应的权重就大。
T次循环完之后就得到整个输出的模型(T个弱分类器的组合):

整个算法分两个阶段:
1、初始化阶段
2、核心阶段,又分为三小步
训练算法的解释:
根据弱分类器的条件et<0.5,可以保证:(1-et)/et>1,从而保证弱分类器的权重是正数。

对于正确分类的样本的相对权重会降低,对于错误分类的样本的权重会升高。
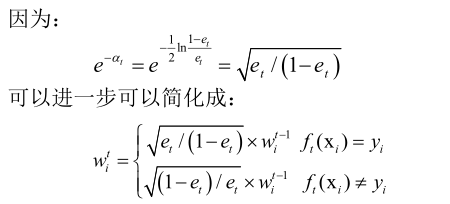
在不考虑归一化因子Zt的情况下,被正确分类的样本乘的是一个小于1的数,而被错误分类的样本乘的是一个大于1的数。
被上一个弱分类器错误分类的样本权重会增大,正确分类的样本权重减小,训练下一个弱分类器时算法会关注在上一轮中被错分的样本。
形象的比喻:在每次考试之后会调整学习的重点,本次考试做对的题目下次不再重点学习;而对于做错的题目下次要重点学习这些知识点。
给样本加权重是有必要的,如果样本没有权重,每个弱分类器的训练样本是相同的(因为训练的时候没有采用随机抽样),训练出来的弱分类器也是一样的,这样训练多个弱分类器没有意义,这也是整个AdaBoost算法一个比较高明的地方。
AdaBoost算法的精髓:
关注之前被错分的样本,准确率高的弱分类器有更大的权重
问题:弱分类器是什么样的?
一般用决策树做弱分类器,但是作为弱分类器有两个原则:计算简单(因此准确率不用太高);非线性(因为强分类器是所有弱分类器的线性线性求和,如果每个弱分类器都是线性函数,那么不管怎么加权最终还是一个线性函数,因此它的建模能力有限,所以我们的弱分类器一定要是非线性的。)
与随机森林的比较:
二者都是集成学习算法,而且AdaBoost一般是用决策树做弱分类器,一般来说他们都是树的集成,这是他们比较像的地方。
根本区别:AdaBoost算法给样本加权(没有做随机采样,每个弱分类器权重是不一样的),随机森林从样本集随机采样(所有弱分类器的权重是一样的)。
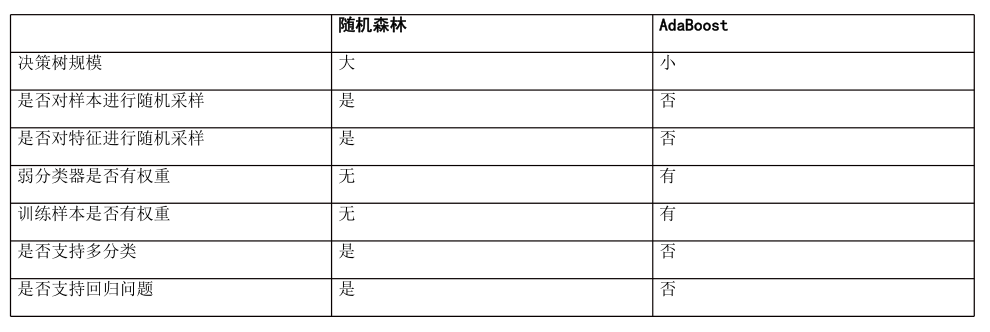
随机森林要求树的深度要比较大,把每个弱学习器当作一个决策树对待;AdaBoost算法要求深度比较小,如深度为1的决策树,最后加权之后,效果照样非常好。
标准的AdaBoost算法是二分类算法。
训练误差分析:
随着迭代的进行(随着弱分类器的增多),强分类器的训练误差(在整个样本集上)会以指数级下降。即训练出来的弱分类器越多我们的强分类器越准,而且错误率是呈指数级下降的。
整个证明过程比较复杂,分两个阶段来证明:
①证明随着迭代进行,强分类器的误差下降。
强分类器在训练样本集上的错误率上界小于每一轮调整样本权重时权重归一化因子的乘积:
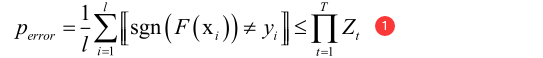
其中perror是强分类器F(xi)在整个样本集上的错误率,[[]]表示里边的条件成立则输出1否则输出0。F(xi)输出是一个实数值不是整数值。

由于Zt<1,所以只要①式成立,则可以说明随着迭代进行,强分类器的误差下降。①式怎么证明成立呢?
分为两步:
首先证明下面的不等式成立:
证明过程:
然后再证明:

②证明随着迭代进行,强分类器的误差呈指数下降。
怎么证明呢?只需证明perror小于一个指数函数即可。
证明过程:


SIGAI机器学习第二十集 AdaBoost算法1的更多相关文章
- SIGAI机器学习第二十一集 AdaBoost算法2
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. 大纲: ...
- SIGAI机器学习第二十二集 AdaBoost算法3
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. AdaB ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- SIGAI机器学习第二十三集 高斯混合模型与EM算法
讲授高斯混合模型的基本概念,训练算法面临的问题,EM算法的核心思想,算法的实现,实际应用. 大纲: 高斯混合模型简介实际例子训练算法面临的困难EM算法应用-视频背景建模总结 高斯混合模型简写GMM,期 ...
- SIGAI机器学习第十集 线性判别分析
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 前边讲的数据降维算法PCA.流行学习都是无监督学习,计算过程中没有利用样本的标签值.对于分类问题,我们要达到的目标是提取或 ...
- SIGAI机器学习第十九集 随机森林
讲授集成学习的概念,Bootstrap抽样,Bagging算法,随机森林的原理,训练算法,包外误差,计算变量的重要性,实际应用 大纲: 集成学习简介 Boostrap抽样 Bagging算法 随机森林 ...
- SIGAI机器学习第四集 基本概念
大纲: 算法分类有监督学习与无监督学习分类问题与回归问题生成模型与判别模型强化学习评价指标准确率与回归误差ROC曲线交叉验证模型选择过拟合与欠拟合偏差与方差正则化 半监督学习归类到有监督学习中去. 有 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- 机器学习--boosting家族之Adaboost算法
最近在系统研究集成学习,到Adaboost算法这块,一直不能理解,直到看到一篇博文,才有种豁然开朗的感觉,真的讲得特别好,原文地址是(http://blog.csdn.net/guyuealian/a ...
随机推荐
- Word 自带公式使用方法技巧(11)
1. 快捷命令 在Word中输入「Alt+=」,可以打开Word中自带公式编辑器.这个编辑器似乎没有什么特别,但其实 Word 2010 以后是支持 LaTeX 语法的.常用规则如下: 分号: a/b ...
- Linux06 文件的打包和压缩(gzip/gunzip、tar、bzip2)
一.gzip/gunzip 这是用于压缩和解压单个文件的工具,且使用方法比较简单 gzip 文件名 gunzip 文件名 二.tar(用的比较多) 不仅可以用于打包文件,还可以将整个目录中的全部文 ...
- vue封装一个简单的div框选时间的组件
记录一下我前段时间封装的一个vue组件吧.技术需要积累,有时间我把我之前写的还不错的组件都开源出来.并尝试vue和react 两种方式的组件封装.今天简单写下鼠标框选div选中效果的封装吧. div框 ...
- html input复选框的checked属性
input --checked: 只要复选框有checked属性,不管属性值为空或者为true or false或任意值,复选框都会被选中.切忌:checked属性值不要带引号 <input t ...
- python中的可哈希与不可哈希
什么是可哈希(hashable)? 简要的说可哈希的数据类型,即不可变的数据结构(字符串str.元组tuple.对象集objects). 哈希有啥作用? 它是一个将大体量数据转化为很小数据的过程,甚至 ...
- [LOJ2541] [PKUWC2018] 猎人杀
题目链接 LOJ:https://loj.ac/problem/2541 Solution 很巧妙的思路. 注意到运行的过程中概率的分母在不停的变化,这样会让我们很不好算,我们考虑这样转化:假设所有人 ...
- golang ---获取IP Address
package main import ( "fmt" "log" "os/exec" "regexp" ) func ...
- Springboot 结合百度IORC实现自定义模板图片识别
前言: 首先呢,最近再公司的项目当中遇到这样的一个问题,就是需要识别图片,提取图片当中的关键语句,而且识别的语句当然是人家手写体识别,翻来覆去一想,最终还是决定使用百度的OCR帮助我解决这一项需求 话 ...
- IDENTITY、SCOPE_IDENTITY、IDENT_CURRENT的分析
https://www.cnblogs.com/daihuiquan/archive/2013/03/18/2956845.html IDENT_CURRENT.IDENTITY.SCOPE_IDEN ...
- 【转载】关于SimpleDateFormat安全的时间格式化线程安全问题
想必大家对SimpleDateFormat并不陌生.SimpleDateFormat 是 Java 中一个非常常用的类,该类用来对日期字符串进行解析和格式化输出,但如果使用不小心会导致非常微妙和难以调 ...