深度学习的激活函数 :sigmoid、tanh、ReLU 、Leaky Relu、RReLU、softsign 、softplus、GELU
深度学习的激活函数 :sigmoid、tanh、ReLU 、Leaky Relu、RReLU、softsign 、softplus、GELU
【 tensorflow中文文档:tensorflow 的激活函数有哪些】

激活函数可以分为两大类 :
- 饱和激活函数: sigmoid、 tanh
- 非饱和激活函数: ReLU 、Leaky Relu 、ELU【指数线性单元】、PReLU【参数化的ReLU 】、RReLU【随机ReLU】
相对于饱和激活函数,使用“非饱和激活函数”的优势在于两点:
1.首先,“非饱和激活函数”能解决深度神经网络【层数非常多!!】的“梯度消失”问题,浅层网络【三五层那种】才用sigmoid 作为激活函数。
2.其次,它能加快收敛速度。
目录
(2)tanh (双曲正切函数 ;Hyperbolic tangent function)
(3) relu (Rectified linear unit; 修正线性单元 )
(4)Leaky Relu (带泄漏单元的relu ) (5) RReLU(随机ReLU)
(6)softsign (7)softplus (8)Softmax
(1)sigmoid 函数 (以前最常用)

参数 α > 0 可控制其斜率。 sigmoid 将一个实值输入压缩至[0,1]的范围,也可用于二分类的输出层。
(2)tanh (双曲正切函数 ;Hyperbolic tangent function)

将 一个实值输入压缩至 [-1, 1]的范围,这类函数具有平滑和渐近性,并保持单调性.

(3) relu (Rectified linear unit; 修正线性单元 )
深度学习目前最常用的激活函数
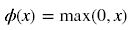
- # Relu在tensorflow中的实现: 直接调用函数
- tf.nn.relu( features, name= None )
与Sigmoid/tanh函数相比,ReLu激活函数的优点是:
- 使用梯度下降(GD)法时,收敛速度更快
- 相比Relu只需要一个门限值,即可以得到激活值,计算速度更快
缺点是: Relu的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。
为了解决Relu函数这个缺点,在Relu函数的负半区间引入一个泄露(Leaky)值,所以称为Leaky Relu函数。
(4)Leaky Relu (带泄漏单元的relu )
数学表达式: y = max(0, x) + leak*min(0,x)
与 ReLu 相比 ,leak 给所有负值赋予一个非零斜率, leak是一个很小的常数 ,这样保留了一些负轴的值,使得负轴的信息不会全部丢失)

- #leakyRelu在tennsorflow中的简单实现
- tf.maximum(leak * x, x),
比较高效的写法为:
- import tensorflow as tf
- def LeakyReLU(x,leak=0.2,name="LeakyReLU"):
- with tf.variable_scope(name):
- f1 = 0.5*(1 + leak)
- f2 = 0.5*(1 - leak)
- return f1*x+f2*tf.abs(x)
(5) RReLU(随机ReLU)
在训练时使用RReLU作为激活函数,则需要从均匀分布U(I,u)中随机抽取的一个数值 ,作为负值的斜率。
(6)softsign
数学表达式:
,导数:

(7)softplus
Softplus函数是Logistic-Sigmoid函数原函数。 ,加了1是为了保证非负性。Softplus可以看作是强制非负校正函数max(0,x)平滑版本。红色的即为ReLU。
(8)Softmax
用于多分类神经网络输出
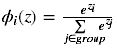
(11)GELU :高斯误差线性单元
在这篇论文中,作者展示了几个使用GELU的神经网络优于使用ReLU作为激活的神经网络的实例。GELU也被用于BERT。
GELU、ReLU和LeakyReLU的函数
- def gelu(x):
- return 0.5 * x * (1 + math.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * math.pow(x, 3))))
- def relu(x):
- return max(x, 0)
- def lrelu(x):
- return max(0.01*x, x)

以下两个是以前使用的:
(9)阈值函数 、阶梯函数

相应的输出 为
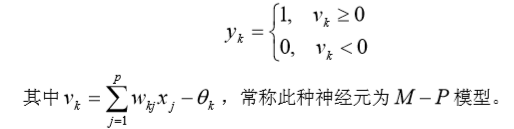
(10)分段线性函数
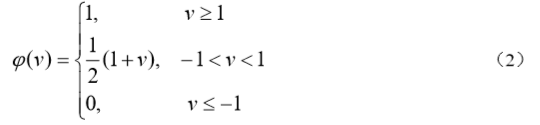
它类似于一个放大系数为 1 的非线性放大器,当工作于线性区时它是一个线性组合器, 放大系数趋于无穷大时变成一个阈值单元。
3.Swish函数
Swish函数是一种自控门的激活函数,其定义:
Swish(x)=xσ(βx) Swish(x) = x\sigma(\beta x)
Swish(x)=xσ(βx)
其中,σ(⋅) \sigma(·)σ(⋅)函数是logistic函数,其值域在(−1,1) (-1,1)(−1,1),β \betaβ是一个参数。也就是说当σ(⋅) \sigma(·)σ(⋅)趋近于1的时候,其输出和x xx本身近似;当σ(⋅) \sigma(·)σ(⋅)趋近于0的时候,其输出趋近于0。
3、基于Gate mechanism的GLU、GTU 单元
介绍一下基于gate mechanism实现的,两个比较新颖的激活函数GTU和GLU。
GTU(Gated Tanh Unit)的表达式为:
f(X) = tanh(X*W+b) * O(X*V+c)
GLU(Gated Liner Unit)的表达式为:
f(X) = (X * W + b) * O(X * V + c)
分析GTU和GLU的组成结构可以发现:
Tanh激活单元:tanh(X*W+b),加上一个Sigmoid激活单元:O(X*V+c)构成的gate unit,就构成了GTU单元。
Relu激活单元:(X * W + b),加上一个Sigmoid激活单元:O(X * V + c)构成的gate unit,就构成了GLU单元。
原文链接:https://blog.csdn.net/lqfarmer/article/details/72676715
深度学习的激活函数 :sigmoid、tanh、ReLU 、Leaky Relu、RReLU、softsign 、softplus、GELU的更多相关文章
- 深度学习:激活函数的比较和优缺点,sigmoid,tanh,relu
https://blog.csdn.net/u011684265/article/details/78039280
- 机器学习、深度学习实战细节(batch norm、relu、dropout 等的相对顺序)
cost function,一般得到的是一个 scalar-value,标量值: 执行 SGD 时,是最终的 cost function 获得的 scalar-value,关于模型的参数得到的: 1. ...
- 激活函数Sigmoid、Tanh、ReLu、softplus、softmax
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/9276412.html 激活函数: 就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端. 常见 ...
- 神经网络激活函数sigmoid relu tanh 为什么sigmoid 容易梯度消失
https://blog.csdn.net/danyhgc/article/details/73850546 什么是激活函数 为什么要用 都有什么 sigmoid ,ReLU, softmax 的比较 ...
- [DeeplearningAI笔记]神经网络与深度学习3.2_3.11(激活函数)浅层神经网络
觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.2 神经网络表示 对于一个由输入层,隐藏层,输出层三层所组成的神经网络来说,输入层,即输入数据被称为第0层,中间层被称为第1层,输出层被称为 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- [转]理解神经网络:从神经元到RNN、CNN、深度学习
神经网络是目前最流行的机器学习算法之一.随着时间的推移,证明了神经网络在精度和速度方面,比其他的算法性能更好.并且形成了很多种类,像CNN(卷积神经网络),RNN,自编码,深度学习等等.神经网络对于数 ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- 深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6
目录 为什么要用激活函数 sigmod tanh ReLU LeakyReLU ReLU6 参考资料 为什么要用激活函数 在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型 ...
随机推荐
- 树莓派python 控制GPIO
sudo pip install rpi.gpio #!/usr/bin/env python # encoding: utf-8 import RPi.GPIO as GPIO import tim ...
- (基因功能 & 基因表达调控)研究方案
做了好久的RNA-seq分析,基因表达也在口头溜了几年了,但似乎老是浮在表面. 对一件事的了解程度决定了你的思维深度,只想做技工就不用想太多,想做大师就一定要刨根问底. 老是说基因表达,那么什么是基因 ...
- nginx 80 下的一个路径 到 8888
# For more information on configuration, see:# * Official English Documentation: http://nginx.org/en ...
- flutter Checkbox 复选框组件
import 'package:flutter/material.dart'; class CheckboxDemo extends StatefulWidget { @override _Check ...
- shell编程系列5--数学运算
shell编程系列5--数学运算 方法1 expr $num1 operator $num2 方法2 $(($num1 operator $num2)) expr操作符对照表1 操作符 含义 num1 ...
- 实战一:LoadRunner性能测试利器
转自:https://blog.csdn.net/weixin_42350428/article/details/82106603 企业的网络应用环境都必须支持大量用户,网络体系架构中含各类应用环境且 ...
- 修改jar包内容并打包上传到私服
第一步:拉下git分支中代码,进行修改,修改后commit——>push 第二步:在IDEA中Terminal中执行命令进行打包到本地mvn clean package 第三步:上传到私服,方法 ...
- 004-guava 集合-新增集合类型-MultiSet, MultiMap, BiMap , Table, ClassToInstanceMap, RangeSe, RangeMap等
一.概述 Guava引入了很多JDK没有的.但明显有用的新集合类型.这些新类型是为了和JDK集合框架共存,而没有往JDK集合抽象中硬塞其他概念.作为一般规则,Guava集合非常精准地遵循了JDK接口契 ...
- 【DataBase】H2 DateBase与项目集成
本例介绍H2与web项目的集成 项目启动H2数据库 1.新建Maven Web项目,参考:[Maven]Eclipse 使用Maven创建Java Web项目 2.引入h2的jar包依赖 <de ...
- matlab基本函数find
一起来学演化计算-matlab基本函数find 觉得有用的话,欢迎一起讨论相互学习~Follow Me 找到非零元素的索引和值 语法 k = find(X) k = find(X)返回一个向量,其中包 ...