卷积神经网络以及TextCNN
对于卷积神经网络的详细介绍和一些总结可以参考以下博文:
https://www.cnblogs.com/pinard/p/6483207.html
https://blog.csdn.net/guoyunfei20/article/details/78055192
这里记录的是结合网上资料的一些总结思考
卷积计算
矩阵的卷积,即两个矩阵对应位置的元素相乘后相加。这里是张量的卷积。
卷积层和池化层的作用
卷积层试图将神经网络中的每一小块进行更加深入地分析从而得到抽象程度更高的特征。池化层可以进一步聚合特征或者抽取更加重要的特征以缩小最后全连接层中节点的个数,从而达到减少整个神经网路中参数的目的。
为什么能进行卷积这种操作?
因为包括图像处理,语言识别以及NLP等任务的数据都具有局部相关性,(图像由元素组成,词组成句子)而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
引发的思考:
卷积的作用?进行局部的感知提取局部的特征。
为什么能进行卷积这种操作?因为深度学习适用数据的局部相关性。
为什么CNN往往是多层的?并行计算快允许其多层,多层才能抽取出全局的以及抽象的特征。
多个卷积核的作用?
多角度的提取局部的特征,使得特征更加充分。
池化的作用?
通过池化能够进一步的减少特征的个数,一定程度上能够防止过拟合,一般用最大池化可能是为了只留下最重要的特征,避免不重要特征带来的影响。Attention有点权重池化的意思。
CNN一层参数的个数:
卷积核的高*宽*个数*通道数+卷积核的个数(这是计算的偏置值的个数)
CNN中的权重共享问题
对于CNN不同的卷积层会定义不同的W,b,只有同一卷积核中的w是共享的,不同的通道卷积核中的w不同,不同大小的卷积核其w自然也不同,多通道同一个卷积核之间的b是共享的,不同卷积核以及不同卷积层的b不同。所以对于CNN而言,同一通道同一卷积核的W一样,同一卷积核即使不同通道的卷积核之间的b也是一样的。
TextCNN部分
对于论文的讲解可参照
https://www.cnblogs.com/bymo/p/9675654.html
实现代码如下:
pool_outputs = []
for filter_h in self.config.filter_hs:
with tf.variable_scope('conv_pool_{}'.format(filter_h)):
#这里的是否添加偏执值和卷积核的初始化都是需要调节的点
conv=tf.layers.conv2d(x,filters=self.config.num_filters,kernel_size=(filter_h,self.config.vector_size+self.config.pseg_size)
,activation=tf.nn.relu,use_bias=False,kernel_initializer=tf.contrib.layers.xavier_initializer(),name='conve')
pooled=tf.nn.max_pool(conv,ksize=[1,self.config.sentence_length-filter_h+1,1,1],strides=[1,1,1,1],padding='VALID',name='pool')
pool_outputs.append(pooled)
#全连接层操作
print('begin full_connection')
with tf.name_scope("full_connection"):
h_pool = tf.concat(pool_outputs, 3) # 把3种大小卷积核卷积池化之后的值进行连接
num_filters_total = self.config.num_filters * len(self.config.filter_hs)
# 因为随后要经过一个全连接层得到与类别种类相同的输出,而全连接接收的参数是二维的,所以进行维度转换
h_pool_flaten = tf.reshape(h_pool, [-1, num_filters_total])
h_drop = tf.nn.dropout(h_pool_flaten, self.keep_prob)
#分类器
W = tf.Variable(tf.truncated_normal([num_filters_total, self.config.num_classes]))
self.l2_loss = tf.nn.l2_loss(W)
b = tf.Variable(tf.constant(0., shape=[self.config.num_classes]), name="b")
self.y_pred = tf.nn.xw_plus_b(h_drop, W, b, name="scores") # wx+b
#预测类别
self.pred_label = tf.argmax(tf.nn.softmax(self.y_pred), 1)
其中TextCNN的详细过程原理图如下:
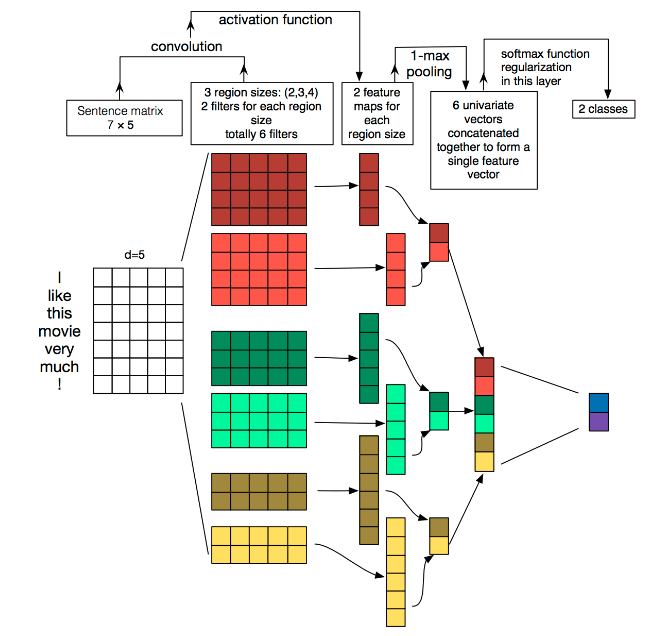
分析:
卷积窗口沿着长度为n的文本一个个滑动,类似于n-gram机制对文本切词,然后和文本中的每个词进行相似度计算,因为后面接了个Max-pooling,因此只会保留和卷积核最相近的词。这就是TextCNN抓取关键词的机制。TextCNN卷积用的是一维卷积,图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要通过设计不同的 filter_size 和 filter 获取不同宽度的视野。TextCNN设置不同高度的卷积核同时卷积核的宽度和词向量的维度相同,这就相当于不同的ngram。
在 TextCNN中使用的是Max-pooling,只保留最有用的表征,但是有些具体任务中也可保留多个,<<A Convolutional Neural Network for Modelling Sentences >>中使用了 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息。
缺点:
CNN网络受感受野的限制只能提取局部特征,一般是通过加深网络层以获得全局信息,但是即使加深网络层,相比于lstm也无法很好的获得长时依赖,要想获得更长时的依赖可以使用膨胀卷积神经网络(空洞网络)。
对于池化层,他能够很大程度减少参数,能够提高速度,防止过拟合等,但是它同样会造成不可逆转的信息丢失,会丢失对于NLP而言很重要的位置信息。一定程度上可以选用k-max pooling。
对于短文本的分类而言,抽取的这些关键词可能就有很好的区分性,因此TextCNN更适用于短文本分类。
由于它无法获得全局信息可以在输入部分和双向LSTM的输出结果进行拼接,从而获得全局信息。
NLP方面CNN比不上RNN,为什么还是选取了CNN,文本分词后一般会有粒度和语义的矛盾,粒度太大,分词效果不好,粒度太小,语义丢失,而CNN核心过程是卷积,我们可以通过CNN的卷积将分完词之后的词的语义结合在一起,从而获得更加准确的词向量。
卷积神经网络以及TextCNN的更多相关文章
- 深度学习之卷积神经网络(CNN)
卷积神经网络(CNN)因为在图像识别任务中大放异彩,而广为人知,近几年卷积神经网络在文本处理中也有了比较好的应用.我用TextCnn来做文本分类的任务,相比TextRnn,训练速度要快非常多,准确性也 ...
- Task7.卷积神经网络
卷积定义: 所谓卷积,其实是一种数学运算.但是在我们的学习生涯中,往往它都是披上了一层外衣,使得我们经常知其然不知其所以然.比如在信号系统中,他是以一维卷积的形式出现描述系统脉冲响应.又比如在图像处理 ...
- 卷积神经网络提取特征并用于SVM
模式识别课程的一次作业.其目标是对UCI的手写数字数据集进行识别,样本数量大约是1600个.图片大小为16x16.要求必须使用SVM作为二分类的分类器. 本文重点是如何使用卷积神经网络(CNN)来提取 ...
- tensorflow学习笔记五:mnist实例--卷积神经网络(CNN)
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import ...
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
- [DL学习笔记]从人工神经网络到卷积神经网络_2_卷积神经网络
先一层一层的说卷积神经网络是啥: 1:卷积层,特征提取 我们输入这样一幅图片(28*28): 如果用传统神经网络,下一层的每个神经元将连接到输入图片的每一个像素上去,但是在卷积神经网络中,我们只把输入 ...
- [DL学习笔记]从人工神经网络到卷积神经网络_1_神经网络和BP算法
前言:这只是我的一个学习笔记,里边肯定有不少错误,还希望有大神能帮帮找找,由于是从小白的视角来看问题的,所以对于初学者或多或少会有点帮助吧. 1:人工全连接神经网络和BP算法 <1>:人工 ...
- lecture5-对象识别与卷积神经网络
Hinton第五课 突然不知道object recognition 该翻译成对象识别好,还是目标识别好,还是物体识别好,但是鉴于范围性,还是翻译成对象识别吧.这一课附带了两个论文<Convolu ...
- Deep learning with Theano 官方中文教程(翻译)(四)—— 卷积神经网络(CNN)
供大家相互交流和学习,本人水平有限,若有各种大小错误,还请巨牛大牛小牛微牛们立马拍砖,这样才能共同进步!若引用译文请注明出处http://www.cnblogs.com/charleshuang/. ...
随机推荐
- 用 Raspberry Pi 架设加密 DNS 客户端
Cloudflare 宣布使用 1.1.1.1 作为 DNS,并且强调隐私保护.由于 Cloudflare DNS 支持 DNS-over-TLS 和 DNS-over-HTTPS,这使得加密 DNS ...
- 物联网架构成长之路(34)-物联网数据可视化grafana展示
一.前言 前面介绍了利用后台业务服务器监听EMQ的Topic,作为EMQ的一个客户端方式来保存数据.然后将数据保存到时序数据库InfluxDB中.本小节就简单介绍一下如何安装和使用,及如何利用Graf ...
- Java连载1-概述&常用的dos命令
本想写完那两个再开始新的,然而客观条件不允许,之前从未接触过Java,从零开始吧!!! 一.概述 C盘下:programme file 一般为64位程序安装的目录,programme file(X ...
- 1+X证书Web前端开发规范手册
一.规范目的 1.1 概述 为提高团队协作效率, 便于后台人员添加功能及前端后期优化维护, 输出高质量的文档, 特制订此文档. 本规范文档一经确认, 前端开发人员必须按本文档规范进行前台页面开发. 本 ...
- CSS3 滤镜Filter亮度动画
CSS3 滤镜Filter亮度动画 -webkit-filter:brightness 值越高 亮度越亮<pre><!DOCTYPE html><html lang=&q ...
- 5个问题带你了解export和import的使用以及export和export defalut 的区别
问题一:export和import是什么? ES6新增模块(module)语法 问题二:export和import的作用是什么? export:规定模块的对外接口,相当于导出功能 import:用于 ...
- VS工具箱不显示DEV控件解决方法
VS工具箱中不显示DEV控件解决方法 之前先装vs,再装dev控件,vs工具栏中自动会加载并显示dev相关组件,但是,在更新vs(我用2017版)后,原先安装好的dev控件库不显示在vs的工具栏中了. ...
- 2、Ext.NET 1.7 官方示例笔记-按钮
这一节应该比较简单,因为按钮相对其他控件还是比较简单的,但按钮是最常用的控件,先从简单的开始,才能循序渐进的学下去不是吗? 从上面的图片可以看出,可分基本&按钮组,先看下基本的Overview ...
- PHP实现简单RPC
1.什么是rpc RPC全称为Remote Procedure Call,翻译过来为“远程过程调用”.目前,主流的平台中都支持各种远程调用技术,以满足分布式系统架构中不同的系统之间的远程通信和相互调用 ...
- DevExpress的TreeList怎样设置数据源使其显示成单列树形结构
场景 Winform控件-DevExpress18下载安装注册以及在VS中使用: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/1 ...