Hive sampling 语法之TABLESAMPLE用法理解
官网关于LanguageManual Sampling的教程,部分截图如下,这里主要分享对TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解
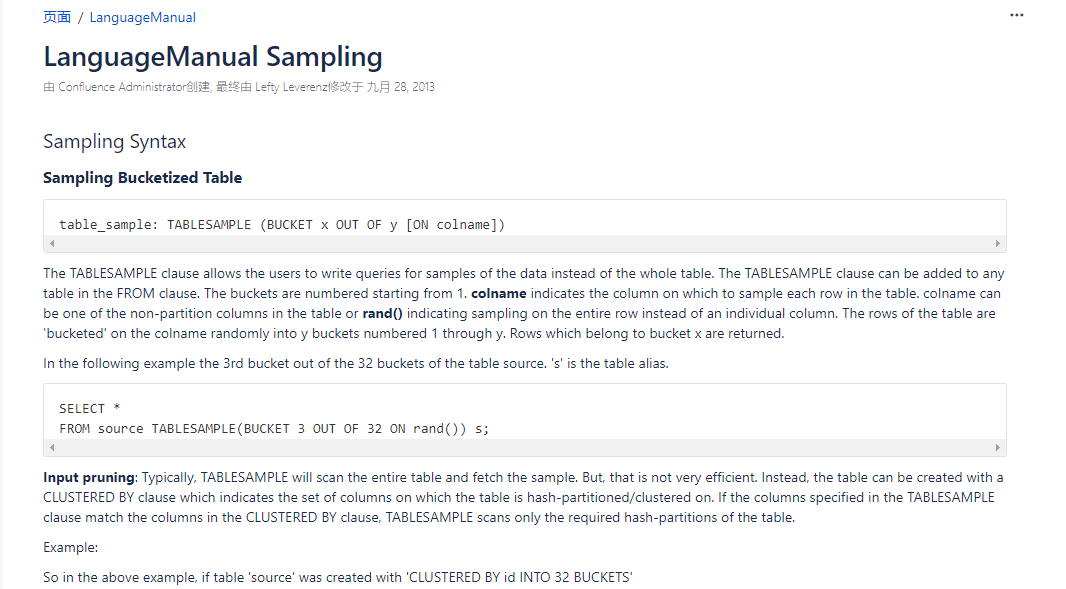
官网中假设创建表时设置了 CLUSTERED BY(id) INTO 32 BUCKETS 即分成了32个文件(虽然这里用的是bucket,为了避免混淆和方便理解下面的解释,个人倾向于用cluster或者叫簇来代替),那么下面这个子句
TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)
在查询中的意思是将cluster分成16个桶,然后取出第三个桶中的数据。32个文件分进16个桶,那就是每个桶有(32/16=)2 个cluster,怎么分呢?第1个cluster分进第1个桶,第2个cluster分进第2个桶......第16个cluster分进第16个桶,第17个cluster分进第1个桶,以此类推。所以当取出第三个桶中的数据时,就会取出第3个簇(cluster)和第19簇(cluster)的数据。官网原话:
would pick out the 3rd and 19th clusters as each bucket would be composed of (32/16)=2 clusters.
那下面这个怎么理解呢?
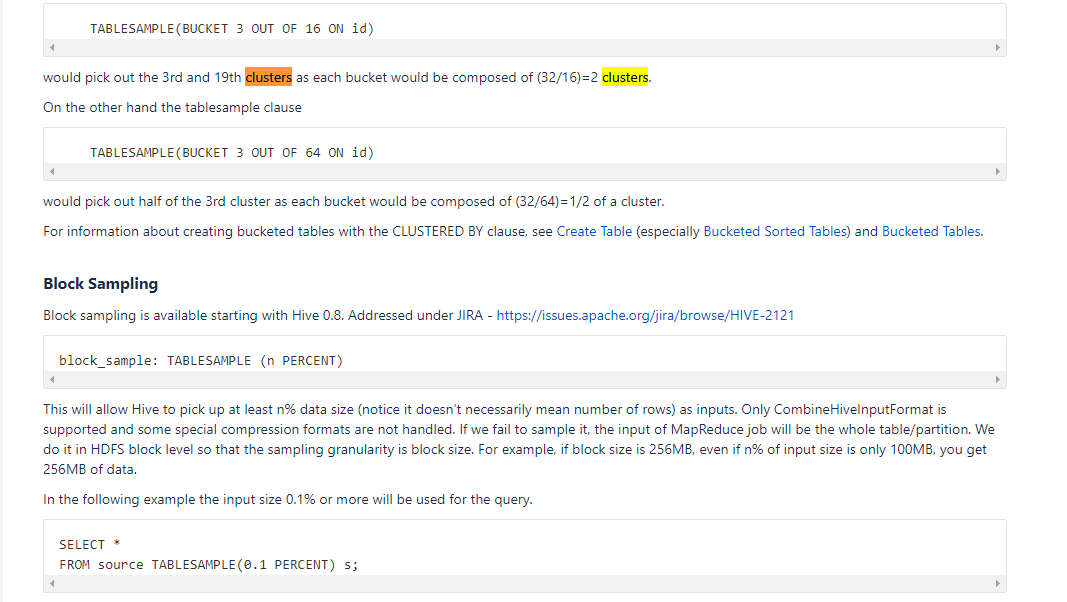
TABLESAMPLE(BUCKET 3 OUT OF 64 ON id)
32个cluster分进64个桶,然后再抽出第三个桶中的数据。32/64=1/2,每个桶由1/2个cluster组成,同样地,第1个cluster的前一半数据分进第1个桶,后一半数据分进第33个桶,第2个cluster的前一半数据分进第2个桶,后一半数据分进第34个桶,.....第32个cluster的前一半数据分进第32个桶,后一半数据分进第64个桶。所以这个子句会取出第3个桶中的数据,也就是第3个cluster中的前一半数据。官网原话:
would pick out half of the 3rd cluster as each bucket would be composed of (32/64)=1/2 of a cluster.
补充官网关于分桶表的DDL操作
LanguageManual DDL BucketedTables
Hive sampling 语法之TABLESAMPLE用法理解的更多相关文章
- Hive基本语法操练
建表规则如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment ...
- Hive 基本语法操练(三):分区操作和桶操作
(一)分区操作 Hive 的分区通过在创建表时启动 PARTITION BY 实现,用来分区的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的.当要查询某一分区的内容时可以采用 WHER ...
- C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com
原文:C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | I ...
- oracle中start with和connect by的用法理解
转自:https://blog.csdn.net/qq_29274091/article/details/72627350 Oracle中start with和connect by 用法理解转自:ht ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- CSS3用法理解
这里只概括了我对CSS3各属性的用法理解.具体每个属性的值,以及例子,看这里 (竟然每篇文章不能低于200字,不能低于200字不能低于200字不能低于200字不能低于200字....请无视)
- HIVE基本语法以及HIVE分区
HIVE小结 HIVE基本语法 HIVE和Mysql十分类似 建表规则 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name da ...
- Hive SQL 语法学习与实践
Hive 介绍 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供 ...
- Hive 基本语法操练(五):Hive 的 JOIN 用法
Hive 的 JOIN 用法 hive只支持等连接,外连接,左半连接.hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce中实现这 ...
随机推荐
- 高性能TcpServer(Python) - SocketServer
源码下载 -> 提取码 QQ:505645074 程序结构图 测试截图 1. 正常接收测试 2. 并发测试
- day 68
目录 表单指令 条件指令 循环指令 分隔符 过滤器 计算属性 监听属性 表单指令 v-model="变量",变量值与表单标签的value相关 v-model可以实现数据的双向绑定, ...
- linux Yum相关
python编写,是centos 和 redhat的包管理工具,类似于 pip 常用的yum命令 Yum list 查看所有的包 Yum list python 列出所有python包 yum sea ...
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
- 【IDE_IntelliJ IDEA】在Intellij IDEA中使用Debug
转载博客:在Intellij IDEA中使用Debug
- Mysql数据库之慢查询
一.简介 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能. 二.参数说明 slow_query_log 慢查询开启状态 slow_ ...
- GCN总结
一.GCN简介 GNN模型主要研究图节点的表示(Graph Embedding),图边结构预测任务和图的分类问题,后两个任务也是基于Graph Embedding展开的.目前论文重点研究网络的可扩展性 ...
- bootm跳转到kernel的流程
转自 https://blog.csdn.net/ooonebook/article/details/53495021 一.bootm说明 bootm这个命令用于启动一个操作系统映像.它会从映像文件的 ...
- func_get_args call_user_func_array
<?php //call_user_func_array.php function test($arg1,$arg2) { $t_args = func_get_args(); $t_resul ...
- history.back(-1)和history.go(-1)的区别 (有错误)
返回一个页面方法有很多,就好比给返回按钮绑定一个URL,但是如果一个页面可以从很多页面到达,那么这个页面返回的页面就不是固定的,那么绑定固定的URL显然不妥. 两个方法的区别 既然history.ba ...