Flink 之 Data Sink
首先 Sink 的中文释义为:
下沉; 下陷; 沉没; 使下沉; 使沉没; 倒下; 坐下;
所以,对应 Data sink 意思有点把数据存储下来(落库)的意思;
Source 数据源 ---- > Compute 计算 -----> sink 落库
如上图,Source 就是数据的来源,中间的 Compute 其实就是 Flink 干的事情,可以做一系列的操作,操作完后就把计算后的数据结果 Sink 到某个地方。(可以是 MySQL、ElasticSearch、Kafka、Cassandra 等)。
这里我说下自己目前做告警这块就是把 Compute 计算后的结果 Sink 直接告警出来了(发送告警消息到钉钉群、邮件、短信等),这个 sink 的意思也不一定非得说成要把数据存储到某个地方去。
其实官网用的 Connector 来形容要去的地方更合适,这个 Connector 可以有 MySQL、ElasticSearch、Kafka、Cassandra RabbitMQ 等。
Data Source 介绍了 Flink Data Source 有哪些,这里也看看 Flink Data Sink 支持的有哪些:

看下源码有哪些呢?

可以看到有 Kafka、ElasticSearch、Socket、RabbitMQ、JDBC、Cassandra POJO、File、Print 等 Sink 的方式。
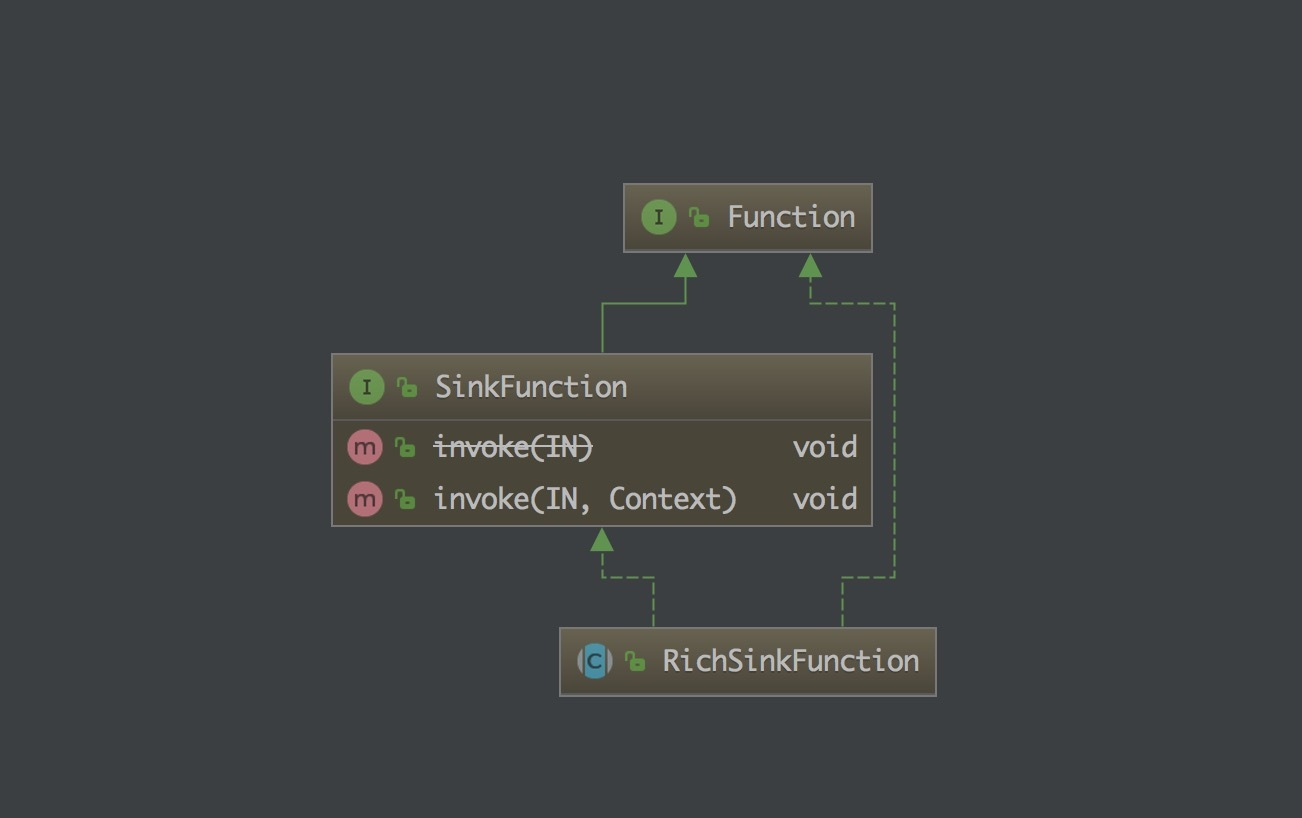
从上图可以看到 SinkFunction 接口有 invoke 方法,它有一个 RichSinkFunction 抽象类。
上面的那些自带的 Sink 可以看到都是继承了 RichSinkFunction 抽象类,实现了其中的方法,那么我们要是自己定义自己的 Sink 的话其实也是要按照这个套路来做的。
这里就拿个较为简单的 PrintSinkFunction 源码来讲下:
@PublicEvolving
public class PrintSinkFunction<IN> extends RichSinkFunction<IN> {
private static final long serialVersionUID = 1L; private static final boolean STD_OUT = false;
private static final boolean STD_ERR = true; private boolean target;
private transient PrintStream stream;
private transient String prefix; /**
* Instantiates a print sink function that prints to standard out.
*/
public PrintSinkFunction() {} /**
* Instantiates a print sink function that prints to standard out.
*
* @param stdErr True, if the format should print to standard error instead of standard out.
*/
public PrintSinkFunction(boolean stdErr) {
target = stdErr;
} public void setTargetToStandardOut() {
target = STD_OUT;
} public void setTargetToStandardErr() {
target = STD_ERR;
} @Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
StreamingRuntimeContext context = (StreamingRuntimeContext) getRuntimeContext();
// get the target stream
stream = target == STD_OUT ? System.out : System.err; // set the prefix if we have a >1 parallelism
prefix = (context.getNumberOfParallelSubtasks() > 1) ?
((context.getIndexOfThisSubtask() + 1) + "> ") : null;
} @Override
public void invoke(IN record) {
if (prefix != null) {
stream.println(prefix + record.toString());
}
else {
stream.println(record.toString());
}
} @Override
public void close() {
this.stream = null;
this.prefix = null;
} @Override
public String toString() {
return "Print to " + (target == STD_OUT ? "System.out" : "System.err");
}
}
可以看到它就是实现了 RichSinkFunction 抽象类,然后实现了 invoke 方法,这里 invoke 方法就是把记录打印出来了就是,没做其他的额外操作。
如何使用?
SingleOutputStreamOperator.addSink(new PrintSinkFunction<>();
这样就可以了,如果是其他的 Sink Function 的话需要换成对应的。
使用这个 Function 其效果就是打印从 Source 过来的数据,和直接 Source.print() 效果一样。

下篇文章我们将讲解下如何自定义自己的 Sink Function,并使用一个 demo 来教大家,让大家知道这个套路,且能够在自己工作中自定义自己需要的 Sink Function,来完成自己的工作需求。
最后
本文主要讲了下 Flink 的 Data Sink,并介绍了常见的 Data Sink,也看了下源码的 SinkFunction,介绍了一个简单的 Function 使用, 告诉了大家自定义 Sink Function 的套路,下篇文章带大家写个。
原创地址为:http://www.54tianzhisheng.cn/2018/10/29/flink-sink/
Flink 之 Data Sink的更多相关文章
- 《从0到1学习Flink》—— Data Sink 介绍
前言 再上一篇文章中 <从0到1学习Flink>-- Data Source 介绍 讲解了 Flink Data Source ,那么这里就来讲讲 Flink Data Sink 吧. 首 ...
- 《从0到1学习Flink》—— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- 《从0到1学习Flink》—— Data Source 介绍
前言 Data Sources 是什么呢?就字面意思其实就可以知道:数据来源. Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集.历史的数据集:也可以用来做流处理,即实时的处理些 ...
- flink with rabbitmq,sink source mysql redis es
flink-dockerhttps://github.com/melentye/flink-docker https://shekharsingh.com/blog/2016/11/12/apache ...
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- Flink 之 Data Source
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源. Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集.历史的数据集: 也可以用来做流处理,即实时的处理些实时 ...
- 《从0到1学习Flink》—— Flink Data transformation(转换)
前言 在第一篇介绍 Flink 的文章 <<从0到1学习Flink>-- Apache Flink 介绍> 中就说过 Flink 程序的结构 Flink 应用程序结构就是如上图 ...
随机推荐
- 4.kafka API producer
1.Producer流程首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer.send方法进行发送.KafkaProducer接收到消息后首先对其进行序列化,然后结 ...
- LInux-命令在后台运行
在终端运行一个持续很久的命令,一旦开始运行这个终端就会等待命令结束,才能输入下个指令,所以可以让这种指令放到后台运行,终端可以继续执行新指令. 后台运行 这种命令要满足1.要运行一段时间2.不需要与用 ...
- PHP开发工具 zend studio
一.搭建PHP开发环境Apahce服务器Dreamwear创建站点 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional/ ...
- Scyther tool 入门
1.Scyther 适合分析什么样的协议 首先协议分析工具并不是可以分析所有的协议,每种协议都有其自己适合的分析方法,并不都是可以使用形式化方法来分析. 目前协议分析方法: 模态逻辑分析(BAN ...
- 2013.5.1 - KDD第十三天
今天把昨天的思路整理了一下,给中秋发过去了,还没回我. 然后就全天看代码了,把NER跟LTP的接口又过了一下.晚上师兄跟我约好这周六一起把LTP写完,到时候我们俩都早点过来. 这之前需要做的有: 1. ...
- Shell排序——软考(五)
希尔排序是一种插入排序,是对直接插入排序的一种改进,该算法出自于D.L.Shell,因此得名为希尔.Shell排序又名缩小增量排序. 思想 假设初始序列为n个元素,先取一个小于n的整数d1作 ...
- 基于h5+的微信分享,hbuilder打包
1.打开app项目的manifest.json的文件,选择模块权限配置,将Share(分享)模块添加至已选模块中 2.选择SDK配置,在plus.share·分享中,勾选□ 微信消息及朋友圈,配置好a ...
- Bias vs. Variance(3)---用learning curves来判断bias/variance problem
画learning curves可以用来检查我们的学习算法运行是否正常或者用来改进我们的算法,我们经常使用learning cruves来判断我们的算法是否存在bias problem/varianc ...
- Win10 系统 Mysql 安装
对于本地开发环境,小型的 Mysql 比较适合本地学习. 本文环境 win10 + mysql8 1.下载 去 Mysql 官网下载安装包 - https://dev.mysql.com/downlo ...
- 软件测试过程中如何区分什么是功能bug,什么是需求bug,什么是设计bug?
问题描述: 测试过程中如何区分什么是功能bug,什么是需求bug,什么是设计bug? 精彩答案: 会员 土土的豆豆: 本期问题其实主要是针对不同方面或纬度上对于bug的一个归类和定位. 个人认为,从软 ...