nlp学习杂记
什么是 token embedding?
输入一个word,在字典里查找得到它对应的下标就是token,然后用该数字下标去lookup表查找得到该词对应的词向量(词嵌入)就是embedding
word2vec
2013年,Google开源了一款用于词向量计算的工具——word2vec。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。
随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
词袋模型(Bag of Words, BOW)
词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。
词向量(Word Embedding)模型
词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
Embedding
是一个将离散变量转为连续向量表示的一个方式
embedding 有以下 3 个主要目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
这也就意味对于上面我们所说的维基百科书籍表示而言,使用 Neural Network Embedding,我们可以在维基百科上获取到的所有 37,000 本书,对于每一篇,仅仅用一个包含 50 个数字的向量即可表示。此外,因为 embedding 是可学习的,因此在不断的训练过程中,更相似的书籍的表示在 embedding space 中将彼此更接近。
总结
Embedding 的价值并不仅仅在于 word embedding 或者 entity embedding,这种将类别数据用低维表示且可自学习的思想更存在价值。通过这种方式,我们可以将神经网络,深度学习用于更广泛的领域,Embedding 可以表示更多的东西,而这其中的关键在于要想清楚我们需要解决的问题和应用 Embedding 表示我们得到的是什么。
什么是cbow
输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,即先验概率。
什么是skip-gram
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量,即后验概率。
什么是viterbi 算法
https://www.zhihu.com/question/20136144/answer/763021768
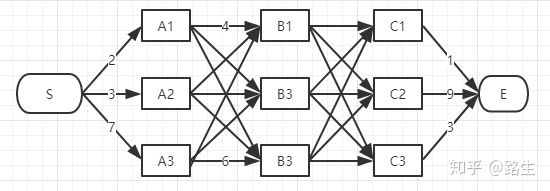
如何找到s到e之间的最短距离?
先分别找到s-b1 、s-b2 、s-b3 的三个最短的距离;然后继续找 s-c1、 s-c2、s-c3 的三个最短距离;最后比较 s-c1-e、s-c2-e、s-c3-e的距离,求的最小距离;
什么是Dropout
我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
nlp学习杂记的更多相关文章
- [Flask]学习杂记--模板
这个学习杂记主要不是分享经验,更多是记录下falsk的体验过程,以后做东西在深入研究,因为django之前用的时间比较长,所以很多概念都是一看而过,做个试验了解下flask的功能. flask中使用是 ...
- TF-IDF与主题模型 - NLP学习(3-2)
分词(Tokenization) - NLP学习(1) N-grams模型.停顿词(stopwords)和标准化处理 - NLP学习(2) 文本向量化及词袋模型 - NLP学习(3-1) 在上一篇博文 ...
- 文本向量化及词袋模型 - NLP学习(3-1)
分词(Tokenization) - NLP学习(1) N-grams模型.停顿词(stopwords)和标准化处理 - NLP学习(2) 之前我们都了解了如何对文本进行处理:(1)如用NLTK文 ...
- NLP学习(5)----attention/ self-attention/ seq2seq/ transformer
目录: 1. 前提 2. attention (1)为什么使用attention (2)attention的定义以及四种相似度计算方式 (3)attention类型(scaled dot-produc ...
- NLP学习(3)---Bert模型
一.BERT模型: 前提:Seq2Seq模型 前提:transformer模型 bert实战教程1 使用BERT生成句向量,BERT做文本分类.文本相似度计算 bert中文分类实践 用bert做中文命 ...
- Java编程思想学习杂记(1-4章)
程序流程控制 移位运算符 移位运算符面向的运算对象是二进制的位,可单独用它们处理整数类型.左移位运算符(<<)能将运算符左边的运算对象向左移动运算符右侧指定的位数(在低位补0)." ...
- Thinking in Java学习杂记(5-6章)
Java中可以通过访问控制符来控制访问权限.其中包含的类别有:public, "有好的"(无关键字), protected 以及 private.在C++中,访问指示符控制着它后面 ...
- Thinking in Java学习杂记(第7章)
将一个方法调用同一个方法主体连接到一起就称为"绑定"(Binding).若在程序运行以前执行绑定,就叫做"早期绑定".而Java中绑定的所有方法都采用后期绑定技 ...
- Stanford NLP 学习笔记2:文本处理基础(text processing)
I. 正则表达式(regular expression) 正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里). ^(在字符前): 负选择,匹配除括号以外 ...
随机推荐
- 07-C#笔记-运算符
1. 支持++和-- 含义和C++中相同 2. 条件运算 同C++ 3. 位运算 ^ 异或 ~ 取反 4. 支持?:运算 5. 特殊 is 判断对象是否为某一类型. If( Ford is Car) ...
- Debian 安装docker
1 $ curl -fsSL get.docker.com -o get-docker.sh 2 $ sudo sh get-docker.sh --mirror Aliyun
- 模拟赛 T1 费马小定理+质因数分解+exgcd
求:$a^{bx \%p}\equiv 1(\mod p)$ 的一个可行的 $x$. 根据欧拉定理,我们知道 $a^{\phi(p)}\equiv 1(\mod p)$ 而在 $a^x\equiv 1 ...
- Luogu P3228 HNOI2013 数列 组合数学
题面 看了题解的推导发现其实并不复杂,但是如果你想要用多项式或者组合数求解的话,就GG了 其实如果把式子列出来的话,不需要怎么推导就能算出来,关键是要想到这个巧妙的式子. 设\(b_i=a_{i+1} ...
- Django ORM性能优化 和 图片验证码
一,ORM性能相关 1. 关联外键, 只拿一次数据 all_users = models.User.objects.all().values('name', 'age', 'role__name') ...
- 团体项目(饱了嘛)_第一组_UML图
UML图 需求分析报告 https://www.cnblogs.com/Clover-yee/p/11771395.html 类图 user(用户类):主要保存用户的基本信息 shop(商铺类):主要 ...
- 将fasta fastq文件线性化处理
将fasta文件线性化处理 awk '/^>/ {printf("%s%s\t",(N>0?"\n":""),$0);N++;n ...
- ACT开发初步(二)——XML
由于pc无法发文,先挖坑,慢慢填
- java对象转变为map
直接上代码 package com.**.**.**.common; import com.**.**.**.util.JsonUtils; import org.springframework.be ...
- Eureka比Zookeeper好在哪里?
Eureka遵守AP,Zookeeper遵守CP RDBMS(oracle/mysql.sqlServer) ====> ACID, 关系型数据库遵循ACID原则: NoSQL(redis/mo ...