Azkaban 3.x 编译及部署
一、Azkaban 源码编译
1.1 下载并解压
Azkaban 在 3.0 版本之后就不提供对应的安装包,需要自己下载源码进行编译。
下载所需版本的源码,Azkaban 的源码托管在 GitHub 上,地址为 https://github.com/azkaban/azkaban 。可以使用 git clone 的方式获取源码,也可以使用 wget 直接下载对应 release 版本的 tar.gz 文件,这里我采用第二种方式:
# 下载
wget https://github.com/azkaban/azkaban/archive/3.70.0.tar.gz
# 解压
tar -zxvf azkaban-3.70.0.tar.gz1.2 准备编译环境
1. JDK
Azkaban 编译依赖 JDK 1.8+ ,JDK 安装方式见本仓库:
2. Gradle
Azkaban 3.70.0 编译需要依赖 gradle-4.6-all.zip。Gradle 是一个项目自动化构建开源工具,类似于 Maven,但由于采用 Groovy 语言进行项目配置,所以比 Maven 更为灵活,目前广泛用于 Android 开发、Spring 项目的构建。
需要注意的是不同版本的 Azkaban 依赖 Gradle 版本不同,可以在解压后的 /gradle/wrapper/gradle-wrapper.properties 文件查看
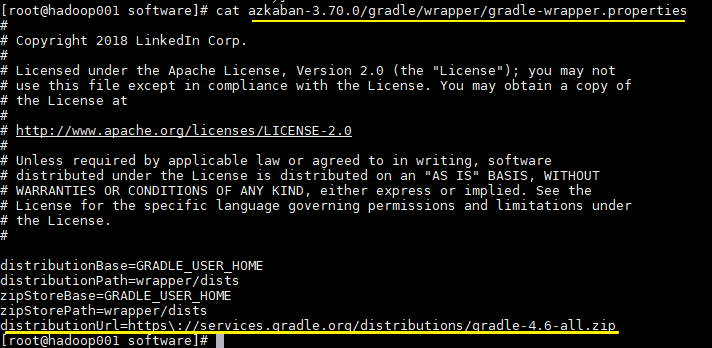
在编译时程序会自动去图中所示的地址进行下载,但是下载速度很慢。为避免影响编译过程,建议先手动下载至 /gradle/wrapper/ 目录下:
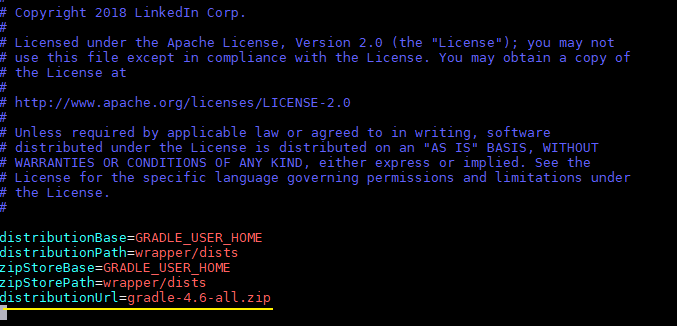
# wget https://services.gradle.org/distributions/gradle-4.6-all.zip然后修改配置文件 gradle-wrapper.properties 中的 distributionUrl 属性,指明使用本地的 gradle。
3. Git
Azkaban 的编译过程需要用 Git 下载部分 JAR 包,所以需要预先安装 Git:
# yum install git1.3 项目编译
在根目录下执行编译命令,编译成功后会有 BUILD SUCCESSFUL 的提示:
# ./gradlew build installDist -x test编译过程中需要注意以下问题:
- 因为编译的过程需要下载大量的 Jar 包,下载速度根据网络情况而定,通常都不会很快,如果网络不好,耗费半个小时,一个小时都是很正常的;
- 编译过程中如果出现网络问题而导致 JAR 无法下载,编译可能会被强行终止,这时候重复执行编译命令即可,gradle 会把已经下载的 JAR 缓存到本地,所以不用担心会重复下载 JAR 包。
二、Azkaban 部署模式
After version 3.0, we provide two modes: the stand alone “solo-server” mode and distributed multiple-executor mode. The following describes thedifferences between the two modes.
按照官方文档的说明,Azkaban 3.x 之后版本提供 2 种运行模式:
- solo server model(单服务模式) :元数据默认存放在内置的 H2 数据库(可以修改为 MySQL),该模式中
webServer(管理服务器) 和executorServer(执行服务器) 运行在同一个进程中,进程名是AzkabanSingleServer。该模式适用于小规模工作流的调度。 - multiple-executor(分布式多服务模式) :存放元数据的数据库为 MySQL,MySQL 应采用主从模式进行备份和容错。这种模式下
webServer和executorServer在不同进程中运行,彼此之间互不影响,适合用于生产环境。
下面主要介绍 Solo Server 模式。
三 、Solo Server 模式部署
2.1 解压
Solo Server 模式安装包在编译后的 /azkaban-solo-server/build/distributions 目录下,找到后进行解压即可:
# 解压
tar -zxvf azkaban-solo-server-3.70.0.tar.gz2.2 修改时区
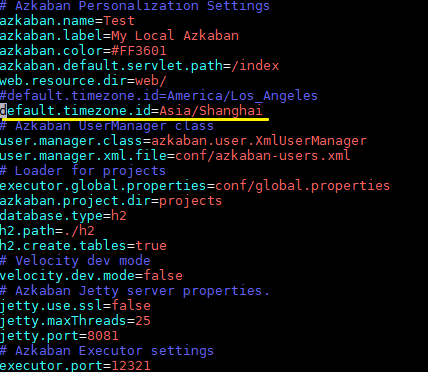
这一步不是必须的。但是因为 Azkaban 默认采用的时区是 America/Los_Angeles,如果你的调度任务中有定时任务的话,就需要进行相应的更改,这里我更改为常用的 Asia/Shanghai
2.3 启动
执行启动命令,需要注意的是一定要在根目录下执行,不能进入 bin 目录下执行,不然会抛出 Cannot find 'database.properties' 异常。
# bin/start-solo.sh2.4 验证
验证方式一:使用 jps 命令查看是否有 AzkabanSingleServer 进程:

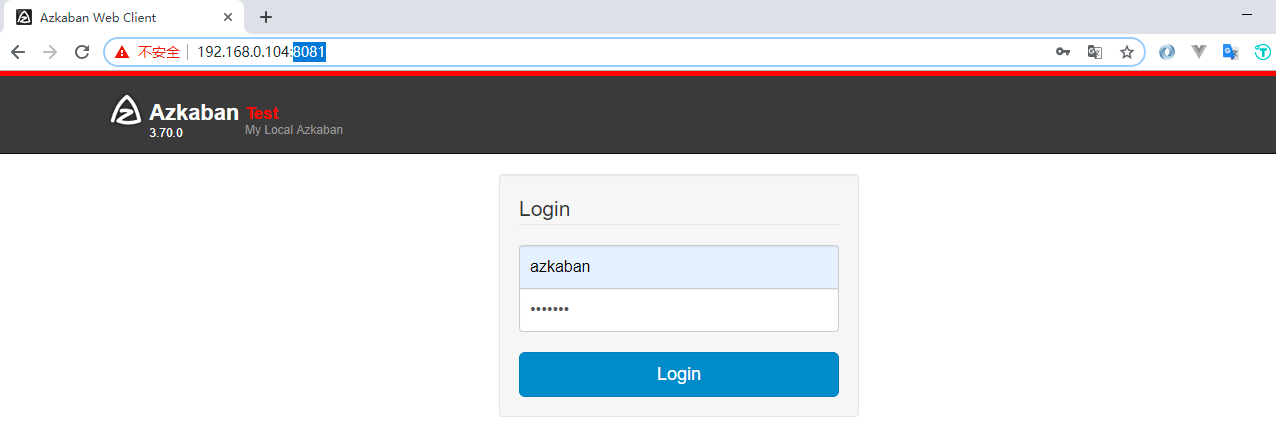
验证方式二:访问 8081 端口,查看 Web UI 界面,默认的登录名密码都是 azkaban,如果需要修改或新增用户,可以在 conf/azkaban-users.xml 文件中进行配置:
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Azkaban 3.x 编译及部署的更多相关文章
- Azkaban学习之路(二)—— Azkaban 3.x 编译及部署
一.Azkaban 源码编译 1.1 下载并解压 Azkaban 在3.0版本之后就不提供对应的安装包,需要自己下载源码进行编译. 下载所需版本的源码,Azkaban的源码托管在GitHub上,地址为 ...
- Azkaban —— 编译及部署
一.Azkaban 源码编译 1.1 下载并解压 Azkaban 在3.0版本之后就不提供对应的安装包,需要自己下载源码进行编译. 下载所需版本的源码,Azkaban的源码托管在GitHub上,地址为 ...
- Azkaban(3.x)编译安装使用
官网地址:https://azkaban.readthedocs.io Azkaban 有三种部署方式:单服务模式.2个服务模式.分布式多服务模式 简单实用仅需单服务模式即可 2个服务模式,需要配置m ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Windows Phone 8初学者开发—第8部分:理解编译和部署
原文 Windows Phone 8初学者开发—第8部分:理解编译和部署 第8部分:理解编译和部署 原文地址: http://channel9.msdn.com/Series/Windows-Phon ...
- Spark编译与部署
Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建 [注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.S ...
- Qt 5.9.4 如何静态编译和部署?
Qt 5.9.4 如何静态编译和部署? MSVC2015 x86 静态编译 Qt 部署静态库 VS2015 部署静态库 1. MSVC2015 x86 静态编译 1.1 Qt 官网下载最新源代码 立即 ...
随机推荐
- Oracle 11.2.0.4打补丁
所需补丁及高版本opatch 上传后将p6880880_112000_Linux-x86-64.zip解压覆盖$ORACLE_HOME/OPatch目录即可 [oracle@localhost OPa ...
- sqlmap选项卡介绍及常用语句
sqlmap的使用方式:python sqlmap.py [options]: sqlmap中一共有以下十六个选项卡: 1.帮助选项卡: 2.Target(目标选项卡): 3.Request(请求选项 ...
- JMX——以可视化形式管理与监控正在运行中的Java程序
简单理解: MBean:管理的最小单元,一个MBean就是一个可以被监控的JavaBean. MBeanServer:一个池子,各个MBean都会注册到该池子中,并且该池子提供一系列的管理.监控API ...
- LCD编程_使用调色板
在前面的博客中,使用的像素格式都是16bpp,24bpp(24bpp实际实际上就是32bpp)?如果想使用8bpp时,就需要使用调色板. 在以前的博客中,曾经说过,在framebuffer中如果每个像 ...
- LCD编程_显示文字
在上篇博客中,实现了画点操作,然后在画点的基础上实现了画线.画圆的操作.实际上显示文字也是在画点的基础上实现的. 文字是由点组成的,那么这些点阵是在哪里获得的呢? 随便打开一个内核文件,搜索font, ...
- 08-C#笔记-判读语句
同C++ 支持if.switch.?: 不同之处 1. switch case支持字符. 参考: http://www.runoob.com/csharp/csharp-switch.html htt ...
- 重新学习Spring注解——AOP
面向切面编程——思想:在一个地方定义通用功能,但是可以通过声明的方式定义这个功能要以何种方式在何处运用,而无须修改受影响的类. 切面:横切关注点可以被模块化为特殊的类. 优点: 1.每个关注点都集中在 ...
- Python前言之Pycharm常用快捷键
pycharm常用快捷键 ctrl+a 全选 ctrl+c 复制(默认复制整行) ctrl+v 粘贴 ctrl+x 剪切(默认复制整行) ctrl+f 搜索 ctrl+z 撤销 ctrl+shift+ ...
- ORA-00923: FROM keyword not found where expected
网上搜索这类错误还是挺多的,只提供我遇到的一种情景. 本地数据库环境:Oracle10g 导入别人的项目后,有一段SQL查询总是报如下错误信息: Cause: java.sql.SQLExceptio ...
- PATA1005Spell It Right
考虑输入为0的特殊情况 参考代码: #define _CRT_SECURE_NO_WARNINGS #include<cstdio> #include<cstring> #in ...