基于opencv的手写数字识别(MFC,HOG,SVM)
参考了秋风细雨的文章:http://blog.csdn.net/candyforever/article/details/8564746
花了点时间编写出了程序,先看看效果吧。
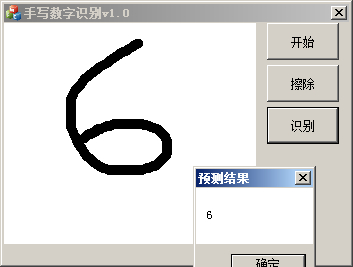
识别效果大概都能正确。
好了,开始正题:
因为本程序是提取HOG特征,使用SVM进行分类的,所以大概了解下HOG的一些知识,其中我觉得怎么计算图像HOG特征的维度会对程序了解有帮助
关于HOG,我们可以参考:
http://gz-ricky.blogbus.com/logs/85326280.html
http://blog.csdn.net/raodotcong/article/details/6239431
关于手写的数字0-9的数据库下载地址和如何生成此数据库HOG特征的xml文件可以参考文章开头的参考博客。
本人提供一个已经训练好的关于此库我生成的xml文件,下载地址:
http://pan.baidu.com/s/1qXSYp
训练模型
#include <iostream>
#include <opencv2/opencv.hpp>
#include <fstream>
using namespace std;
using namespace cv;
int main()
{
vector<string> img_path;//输入文件名变量
vector<int> img_catg;
int nLine = 0;
string buf;
ifstream svm_data( "D:/project/HOG/t10k-images-bmp/t10k-images/result.txt" );//训练样本图片的路径都写在这个txt文件中,使用bat批处理文件可以得到这个txt文件
unsigned long n;
while( svm_data )//将训练样本文件依次读取进来
{
if( getline( svm_data, buf ) )
{
nLine ++;
if( nLine % 2 == 0 )//注:奇数行是图片全路径,偶数行是标签
{
img_catg.push_back( atoi( buf.c_str() ) );//atoi将字符串转换成整型,标志(0,1,2,...,9),注意这里至少要有两个类别,否则会出错
}
else
{
img_path.push_back( buf );//图像路径
}
}
}
svm_data.close();//关闭文件
CvMat *data_mat, *res_mat;
int nImgNum = nLine / 2; //nImgNum是样本数量,只有文本行数的一半,另一半是标签
data_mat = cvCreateMat( nImgNum, 324, CV_32FC1 ); //第二个参数,即矩阵的列是由下面的descriptors的大小决定的,可以由descriptors.size()得到,且对于不同大小的输入训练图片,这个值是不同的
cvSetZero( data_mat );
//类型矩阵,存储每个样本的类型标志
res_mat = cvCreateMat( nImgNum, 1, CV_32FC1 );
cvSetZero( res_mat );
IplImage* src;
IplImage* trainImg=cvCreateImage(cvSize(28,28),8,3);//需要分析的图片,这里默认设定图片是28*28大小,所以上面定义了324,如果要更改图片大小,可以先用debug查看一下descriptors是多少,然后设定好再运行
//处理HOG特征
for( string::size_type i = 0; i != img_path.size(); i++ )
{
src=cvLoadImage(img_path[i].c_str(),1);
if( src == NULL )
{
cout<<" can not load the image: "<<img_path[i].c_str()<<endl;
continue;
}
cout<<"deal with\t"<<img_path[i].c_str()<<endl;
cvResize(src,trainImg);
HOGDescriptor *hog=new HOGDescriptor(cvSize(28,28),cvSize(14,14),cvSize(7,7),cvSize(7,7),9);
vector<float>descriptors;//存放结果
hog->compute(trainImg, descriptors,Size(1,1), Size(0,0)); //Hog特征计算
cout<<"HOG dims: "<<descriptors.size()<<endl;
n=0;
for(vector<float>::iterator iter=descriptors.begin();iter!=descriptors.end();iter++)
{
cvmSet(data_mat,i,n,*iter);//存储HOG特征
n++;
}
cvmSet( res_mat, i, 0, img_catg[i] );
cout<<"Done !!!: "<<img_path[i].c_str()<<" "<<img_catg[i]<<endl;
}
CvSVM svm;//新建一个SVM
CvSVMParams param;//这里是SVM训练相关参数
CvTermCriteria criteria;
criteria = cvTermCriteria( CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
param = CvSVMParams( CvSVM::C_SVC, CvSVM::RBF, 10.0, 0.09, 1.0, 10.0, 0.5, 1.0, NULL, criteria );
svm.train( data_mat, res_mat, NULL, NULL, param );//训练数据
//保存训练好的分类器
svm.save( "HOG_SVM_DATA.xml" );
cout<<"HOG_SVM_DATA.xml is saved !!! \n exit program"<<endl;
cvReleaseMat( &data_mat );
cvReleaseMat( &res_mat );
cvReleaseImage(&trainImg);
return 0;
}
D:/project/HOG/t10k-images-bmp/t10k-images/result.txt 的生成方法
使用createpath.py脚本
import os, sys
def get_filepaths(directory):
file_paths = [] # List which will store all of the full filepaths.
for root, directories, files in os.walk(directory):
for filename in files:
# Join the two strings in order to form the full filepath.
filepath = os.path.join(root, filename)
file_paths.append(filepath) # Add it to the list.
return file_paths # Self-explanatory.
lists = get_filepaths(os.path.dirname(os.path.abspath(__file__)))
with open('result.txt', 'a') as f:
for url in lists:
if (os.path.basename(url).startswith('0_')):
f.write(url)
f.write('\n')
f.write('0\n')
if (os.path.basename(url).startswith('1_')):
f.write(url)
f.write('\n')
f.write('1\n')
if (os.path.basename(url).startswith('2_')):
f.write(url)
f.write('\n')
f.write('2\n')
if (os.path.basename(url).startswith('3_')):
f.write(url)
f.write('\n')
f.write('3\n')
if (os.path.basename(url).startswith('4_')):
f.write(url)
f.write('\n')
f.write('4\n')
if (os.path.basename(url).startswith('5_')):
f.write(url)
f.write('\n')
f.write('5\n')
if (os.path.basename(url).startswith('6_')):
f.write(url)
f.write('\n')
f.write('6\n')
if (os.path.basename(url).startswith('7_')):
f.write(url)
f.write('\n')
f.write('7\n')
if (os.path.basename(url).startswith('8_')):
f.write(url)
f.write('\n')
f.write('8\n')
if (os.path.basename(url).startswith('9_')):
f.write(url)
f.write('\n')
f.write('9\n')

生成result.txt

使用模型
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
IplImage *test;
char result[]; //存放预测结果 CvSVM svm;
svm.load("d:\\HOG_SVM_DATA.xml");//加载训练好的xml文件,这里训练的是10K个手写数字
//检测样本
test = cvLoadImage("d:\\test.bmp", ); //待预测图片,用系统自带的画图工具随便手写
if (!test)
{
cout<<"not exist"<<endl;
return -;
}
cout<<"load image done"<<endl;
IplImage* trainTempImg=cvCreateImage(cvSize(,),,);
cvZero(trainTempImg);
cvResize(test,trainTempImg);
HOGDescriptor *hog=new HOGDescriptor(cvSize(,),cvSize(,),cvSize(,),cvSize(,),);
vector<float>descriptors;//存放结果
hog->compute(trainTempImg, descriptors,Size(,), Size(,)); //Hog特征计算
cout<<"HOG dims: "<<descriptors.size()<<endl; //打印Hog特征维数 ,这里是324
CvMat* SVMtrainMat=cvCreateMat(,descriptors.size(),CV_32FC1);
int n=;
for(vector<float>::iterator iter=descriptors.begin();iter!=descriptors.end();iter++)
{
cvmSet(SVMtrainMat,,n,*iter);
n++;
} int ret = svm.predict(SVMtrainMat);//检测结果
sprintf(result, "%d\r\n",ret );
cvNamedWindow("dst",);
cvShowImage("dst",test);
cout<<"result:"<<result<<endl;
waitKey ();
cvReleaseImage(&test);
cvReleaseImage(&trainTempImg); return ;
}
工程源码(MFC):
http://pan.baidu.com/s/1rDQbO
程序下载(裸机可运行,无需环境):
http://pan.baidu.com/s/1byQeX
QT控制台版本(包含手写数据库,训练模型,使用模型)
http://pan.baidu.com/s/1pJ45bwZ
基于opencv的手写数字识别(MFC,HOG,SVM)的更多相关文章
- 机器学习初探(手写数字识别)HOG图片
这里我们讲一下使用HOG的方法进行手写数字识别: 首先把 代码分享出来: hog1.m function B = hog1(A) %A是28*28的 B=[]; [x,y] = size(A); %外 ...
- 基于opencv的手写数字字符识别
摘要 本程序主要参照论文,<基于OpenCV的脱机手写字符识别技术>实现了,对于手写阿拉伯数字的识别工作.识别工作分为三大步骤:预处理,特征提取,分类识别.预处理过程主要找到图像的ROI部 ...
- keras基于卷积网络手写数字识别
import time import keras from keras.utils import np_utils start = time.time() (x_train, y_train), (x ...
- OpenCV+TensorFlow图片手写数字识别(附源码)
初次接触TensorFlow,而手写数字训练识别是其最基本的入门教程,网上关于训练的教程很多,但是模型的测试大多都是官方提供的一些素材,能不能自己随便写一串数字让机器识别出来呢?纸上得来终觉浅,带着这 ...
- 基于OpenCV的KNN算法实现手写数字识别
基于OpenCV的KNN算法实现手写数字识别 一.数据预处理 # 导入所需模块 import cv2 import numpy as np import matplotlib.pyplot as pl ...
- 手写数字识别 ----在已经训练好的数据上根据28*28的图片获取识别概率(基于Tensorflow,Python)
通过: 手写数字识别 ----卷积神经网络模型官方案例详解(基于Tensorflow,Python) 手写数字识别 ----Softmax回归模型官方案例详解(基于Tensorflow,Pytho ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- [Python]基于CNN的MNIST手写数字识别
目录 一.背景介绍 1.1 卷积神经网络 1.2 深度学习框架 1.3 MNIST 数据集 二.方法和原理 2.1 部署网络模型 (1)权重初始化 (2)卷积和池化 (3)搭建卷积层1 (4)搭建卷积 ...
随机推荐
- 基于webpivottable做的透视表
1.绑定数据和配置: var wptConfig=<%= wptConfig%>; webPivotTable.setCsvData(<%=dataFields %>, < ...
- vim快捷键笔记【原创】
Vim zR 全部展开 zM全部合并 vim 快捷键 shift + i (‘I’) 进行编辑 shift + 4 (‘$’) 跳到行尾 shift ...
- 如何实现wpf的多国语言
http://www.cnblogs.com/horan/archive/2012/04/20/wpf-multilanguage.html 4.0版本的locbaml http://michaels ...
- 【转】Android 使用ORMLite 操作数据库
Android 使用ORMLite 操作数据库 用过ssh,s2sh的肯定不会陌生 ,应该一学就会 第一步: 下载ormlite-android-4.41.jar和ormlite-core-4.4 ...
- Java好文统计( 引用 )
1. java 关于类的路径及编译问题 windows 版本:http://www.ibm.com/developerworks/cn/java/j-classpath-windows/ unix & ...
- TCSRM5961000
一直没想到怎么去重 看了眼别人的代码...so easy啊 同余啊 唉..脑子被僵尸吃掉了 难得1000出个简单的 #include <iostream> #include<cstd ...
- 运行时报错 ADB server didn’t ACK
查看进程中所有和ADB有关的进程,全都结束了,包括什么豌豆荚之类的(大多数情况是占用端口),之后重新启动Eclipse.
- hibernate lazy=false annotation设置
工程报错如下: org.hibernate.LazyInitializationException: could not initialize proxy - no Session 解决方法: 在类的 ...
- Uploadify上传Excel到数据库
前两章简单的介绍了Uploadify上传插件的基本使用和相关的属性说明.这一章结合Uploadify+ssh框架+jquery实现Excel上传并保存到数据库. 以前写的这篇文章 Jq ...
- 设置sudo不输入密码 sudoers 编辑出错后的补救方法
一 设置sudo为不需要密码 有时候我们只需要执行一条root权限的命令也要su到root,是不是有些不方便?这时可以用sudo代替.默认新建的用户不在sudo组,需要编辑/etc/sudoers文件 ...