【linux】文字提取
提取IP地址:
方法①:
ifconfig eth3|grep Bcast|cut -d ":" -f2|cut -d " " -f1
ifconfig: 显示或配置网络设备的命令 后面跟的是设备名。
ifconfig eth3 的显示如下:
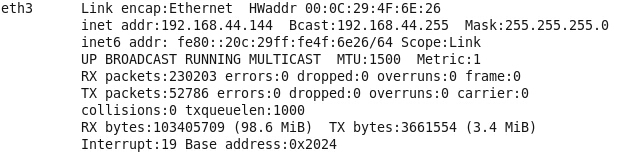
grep: 后面接正则表达式,显示正则表达式出现的行
ifconfig eth3|grep Bcast的显示为:

cut: -d 后面接分割符 -f后面的数字表示要获取分割后的第几个数据
ifconfig eth3|grep Bcast|cut -d ":" -f2 后显示为:

ifconfig eth3|grep Bcast|cut -d ":" -f2|cut -d " " -f1 后就获取了ip地址

awk小例子
来自http://www.cnblogs.com/xupeizhi/archive/2012/07/23/2605371.html
①输出文件中包含符合某正则表达式的行
awk '/111*/' text 输出text文件中包含符合111* 字段的行

②输出文件中每行的第n个字段
awk '{print $1}' text 输出text文件中每行的第一个字段 $0表示全部
awk '{print $1,$3}' text 输出text文件中每行的第一和第三个字段 空格分隔
awk '/111*/{print $1,$3}' text 输出text文件中有符合111*字段行的第一和第三个字段
tr:
来自http://blog.sina.com.cn/s/blog_58c3f7960100uttl.html
tr -c -d -s ["string1_to_translate_from"] ["string2_to_translate_to"] < input-file
这里:
-c 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
input-file是转换文件名。虽然可以使用其他格式输入,但这种格式最常用。
例子
1、
# cat file | tr [a-z] [A-Z] > new_file
# cat file | tr [A-Z] [a-z] > new_file
或者
# cat file | tr -s "\r" "\n" > new_file
sort:
来自http://www.cnblogs.com/dong008259/archive/2011/12/08/2281214.html
sort命令是帮我们依据不同的数据类型进行排序,其语法及常用参数格式:
sort [-bcfMnrtk][源文件][-o 输出文件]
补充说明:sort可针对文本文件的内容,以行为单位来排序。
参 数:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-f 排序时,忽略大小写字母。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
-k 选择以哪个区间进行排序。
uniq:
来自:http://blog.csdn.net/jesseen/article/details/8005056

综合应用:
Write a bash script to calculate the frequency of each word in a text file words.txt.
For simplicity sake, you may assume:
words.txtcontains only lowercase characters and space' 'characters.- Each word must consist of lowercase characters only.
- Words are separated by one or more whitespace characters.
For example, assume that words.txt has the following content:
the day is sunny the the
the sunny is is
Your script should output the following, sorted by descending frequency:
the 4
is 3
sunny 2
day 1
方法一:
解答:为了方便使用sort函数,首先要把每个字符串单独放在一行 要用tr, 然后用sort排序,用uniq统计每个单词的数量,再用sort按照数量排序,最后用awk按格式输出。
cat words.txt | tr -s ' ' '\n'|sort|uniq -c|sort -nr|awk '{print $2,$1}'
方法二:只用awk
awk '\
{ for (i=1; i<=NF; i++) { ++D[$i]; } }\
END { for (i in D) { print i, D[i] } }\
' words.txt | sort -nr -k 2
awk原理:来自http://www.cnblogs.com/xupeizhi/archive/2012/07/23/2605371.html
1):awk使用一行作为输入,并将这一行赋给内部变量$0,默认时每一行也可以称为一个记录,以换行符结束。
2):然后,行被空格分解成字段,每一个字段存储在已编号的变量中,从$1开始,可以多达100个字段。
3):awk如何知道空格是用来分隔字段的呢?因为有另一个内部变量FS用来确定字段的分隔符。初始时,FS被赋为空格——包含制表符和空格符。如果需要使用其他的字符分隔符,如冒号或破折号,则需要将FS变量的值设为新的字段分隔符。
4):awk打印字段时,将以下面的方式使用print函数:{print $1,$3};逗号比较特殊,它映射为另一个内部变量,称为输出字段分隔符OFS,OFS默认为空格。逗号被OFS变量中存储的字符替换。
5):awk输出之后,将从文件中获取另一行,并将其存储到$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。这个过程将持续到整个文件的所有行都处理完毕。
转义序列:转义序列用一个反斜杠后跟一个字母或数字来表示。它们可以用在字符串中,代表制表符,换行符,换页符等。
5:awk '/zhangfei/{print "\t\twu hu shangjiang:" $1,$2 "!"}'
wu hu shangjiang:zhangfei xiuhua!
\t:制表符,tab键
6.打印数字时,可能需要控制数字的格式。这可以通过printf函数来实现,但是,通过设置一个特殊的awk变量OFMT,使用print函数时也可以控制数字的打印格式。OFMT的默认值时“%.6gd",表示只打印小数部分的前六位。
awk 'BEGIN{OFMT="%.2f";print 1.23456789,12E-2}'
1.23 0.12
如果设置了变量OFMT,在打印浮点数时,就只打印小数部分的前两位。百分号表示接下来要定义格式。
BEGIN:必须大写
7:
1):[root@localhost tmp]# echo "UNIX" | awk '{printf "|%-15s|\n",$1}'
|UNIX |
2):[root@localhost tmp]# echo "UNIX" | awk '{printf "|%15s|\n",$1}'
| UNIX|
1): 对于echo命令的输出,unix是经管道发给awk。printf函数包含一份控制串。百分号让printf做好准备,它要打印一个占15非格,向左对 齐的字符串,这个字符串夹在两个竖杠之间,并且以换行符结尾。百分号后的短划线表示左对齐。控制穿后面跟了一个逗号和$1。printf将根据控制串中的 格式说明来格式化字符串unix。
2):字符串unix被打印成一个占15格,向右对齐的字符串,夹在两个竖杠之间,以换行符结尾。
8.[root@localhost tmp]# awk '{printf "The name is: %-15s ID is: %-15d Money is: %-15d\n",$1,$2,$3}' liuguanzhang
The name is: liubei ID is: 1 Money is: 10000
The name is: guanyu ID is: 2 Money is: 2000
The name is: zhangfei ID is: 3 Money is: 1000
9.[root@localhost tmp]# awk '{printf "|%-15s| %-15s| %-15s\n",$1,$2,$3}' liuguanzhang
|liubei | 1 | 10000
|guanyu | 2 | 2000
|zhangfei | 3 | 1000
10:root@localhost tmp]# awk '{max=($1>$2)?$1:$2;print max}' filename
如果记录的第一个字段的值大于第二个字段的值,则把问号后面那个表达式的值赋给max,否则就将冒号后面的那个表单时的赋给max。
11:awk -F: 'NF != 7{printf("line %d,does not have 7 fields: %s\n",NR,$0)} $1 !~/[A-Za-z0-9]/{printf("line %d,nonalphanunmeric user id: %s\n",NR,$0)} $2=="*"{printf("line %d,no password:%s\n",NR,$0)}' passwd
awk的字段分隔 符是冒号;如果字段数(NF)不等于7,则执行接下来的操作块;printf函数打印字符串“line<行号>,does not have 7 fields:”,后面跟上当前记录的记录号(NR)和记录本身($0);如果第一个字段($1)中不含任何字母和数字字符,printf函数就打印字符 串“nonalphanumberic user id:”,后面跟上当前记录的记录号和内容;如果第二个字段是一个星号,就打印字符串“no passwd:",后面跟上记录号和记录本身.
12:awk -F: '/Nancy McNeil/{$1="Louise Mclnnes";print $0}' test
【linux】文字提取的更多相关文章
- [Linux] 如何在 Linux 中提取随机数
如何在 Linux 中提取随机数 一.设备文件 /dev/random & /dev/urandom 字符特殊文件 /dev/random 和 /dev/urandom (存在于Linux 1 ...
- Linux文字分段裁剪命令cut(转)
Linux cut命令用于显示每行从开头算起num1到num2的文字. 语法 cut [-bn] [file] cut [-c] [file] cut [-df] [file] 使用说明: cut命令 ...
- php抓取图片进行内容提取解析,文字性pdf进行内容文字提取解析
2018年7月7日18:52:17 php是用纯算法,自己是提取图片内容不是不行,可以但是优化起来很麻烦还得设计学习库,去矫正数据的正确率 对于大多数项目来说,如果不是做ocr服务,就不必要做需求工具 ...
- Linux shell 提取文件名和目录名的一些方法(转)
很多时候在使用Linux的shell时,我们都需要对文件名或目录名进行处理,通常的操作是由路径中提取出文件名,从路径中提取出目录名,提取文件后缀名等等.例如,从路径/dir1/dir2/file.tx ...
- python实现图片文字提取,准确率高达99%,强无敌!!!
上次我使用的百度AI开放平台的API接口实现图片的转化,后来有许多小伙伴都私信问我,怎么获取百度AI平台的AK和SK.为了统一回答大家的问题,今天我又使用百度API实现了一个从图片中提取文字和识别身份 ...
- Linux shell 提取文件名和目录名
${}用于字符串的读取,提取和替换功能,可以使用${} 提取字符串 1.提取文件名 [root@localhost log]# var=/dir1/dir2/file.txt [root@localh ...
- 基于tess4j的图片文字提取
1.文件结构目录 2.具体实现 ①添加maven依赖 <dependency> <groupId>net.sourceforge.tess4j</groupId> ...
- Linux下提取IP至文件
ifconfig | grep 'inet[^6]' | sed 's/^\s*//g' | cut -d ' ' -f2 > ips.txt 排除127开头的IP: ifconfig | gr ...
- hanlp中文智能分词自动识别文字提取实例
需求:客户给销售员自己的个人信息,销售帮助客户下单,此过程需要销售人员手动复制粘贴收获地址,电话,姓名等等,一个智能的分词系统可以让销售人员一键识别以上各种信息 经过调研,找到了一下开源项目 1.wo ...
随机推荐
- PF_RING 总结
1.背景 目前收包存在的问题: 第一:inpterrupt livelock, 当收到包的时候,网卡驱动程序就会产生一次中断.在大流量的情况下,操作系统将花费大量时间用于处理中断,而只有 少量的时间用 ...
- Java从入门到精通——调错篇之SVN 出现 Loced错误
我在更新SVN的时候同时并打开了在这SVN上的一个文档结果导致了我更新的时候提示Loced错误 解决方法:出现这个问题后使用"清理"功能,如果还不行,就直接到上一级目录,再执行&q ...
- shell-IF判断
#!/bin/bash echo "-----------------strat---------------" read -p "Enter a number:&quo ...
- Swift给每个开发者赢取500万的机会!不看一生后悔。
[导语] Swift的横空出世,很多有想法的人已经发现其中的蕴含的巨大商机,而很多新手却只是云里雾里,只知道大家最近讨论Swift很欢乐.内行看门道,外行看热闹,说的就是这个理.如果你能把swift用 ...
- ExtJS MVC结构
概述 大型的应用在开发和运维上都存在着困难.应用功能的调整和开发人员的调动都会影响对项目的掌控.ExtJS4带来了一种新的应用结构.这种结构不止用于组织代码,也能有效的减少必要的代码量. 这次ExtJ ...
- matlab 函数的编写与调用
matlab中写个函数,在主程序中调用该函数的方法 跟其它的编程语言都一样,但是子函数与主函数要存于不同的文件中,文件名就是函数名字.文件必须保存在current directory中,才能调用. 函 ...
- DES,3DES,AES这三种对称密钥的区别与联系
DES:Data Encryption Standard(数据加密标准,又美国国密局,选中的IBM的方案,密钥长度为56,标准提出是要使用64位长的密钥,但是实际中DES算法只用了64位中的56位密钥 ...
- 30道小学生四则运算题C/C++编程
软件工程科课上,老师通过实例讲解什么是程序,程序和软件的区别,要求我们通过短时间写一道编程题, 题目就是编写30道小学生四则运算题.以下就是源代码: #include<iostream.h> ...
- windows下将多个文件里面的内容合并成一个一个文件
如题:例如有多个章节的小说,现在要把他们合并成一个txt文件. 利用windows自带cmd工具: 一.拷贝合并1.将你的txt文档按照顺序分别命名为01.txt 02.txt 03.txt……2.将 ...
- 你所必须掌握的三种异步编程方法callbacks,listeners,promise
目录: 前言 Callbacks Listeners Promise 前言 coder都知道,javascript语言运行环境是单线程的,这意味着任何两行代码都不能同时运行.多任务同时进行时,实质上形 ...