Distributed3:SQL Server 创建分布式数据库
分布式数据库的优势是将IO分散在不同的Physical Disk上,每次查询都由多台Server的CPU,I/O共同负载,通过各节点并行处理数据来提高性能,劣势是消耗大量的网络带宽资源,管理难度大。在SQL Server 2012 版本中,创建水平切分的分布式数据库,必须分两步来实现:划分子集和对子集进行并集操作。
划分子集是将原始表水平切分成若干个较小的成员表,每一个成员表都是全集的一个划分(各子集的并集是全集,其交集是空集)。每个成员表包含与原始表相同数量的列,并且每一列具有与原始表中的相应列同样的特性(如数据类型、大小、排序规则),成员表的schema和原始表相同,只是存储的数据不同。水平切分原始表,也叫做数据库水平分片,sharding。在查询时,利用分区视图来实现水平分片对用户透明,分区视图对分布在不同服务器中的分区数据进行并集操作,使数据看起来来自一个表。
分布在不同场地的SQL Server通过Linked Server相互通信,通过MSDTC来保证查询的事务特性。Linked Server定义从某一数据库服务器到另一数据库服务器的单向通信路径,而MSDTC能够保证一个事务在不同的Server上实现ACID属性。例如,在一个事务中存在 Server1上的 Insert 操作和 Server2上 Update 操作 ,如果事务回滚,那么MSDTC保证Server1 和 Server2的操作都要回滚;如果事务提交,MSDTC保证Server1 和 Server2的操作都要Commit。
设计目的:将table dbo.Person 的数据水平分片,分布到两天SQL Server上,Column [PersonType] 共有6个值,分别是:('IN','EM','SP'),('SC','VC','GC');
CREATE TABLE [dbo].[Person]
(
[PersonID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[FirstName] [sysname] NOT NULL,
[MiddleName] [sysname] NOT NULL,
[LastName] [sysname] NOT NULL
)
step1,打开Win10 MSDTC(Microsoft Distributed Transaction Coordinator)
参考《Win10 打开MSDTC》,不再赘述。
step2,分别在两台Server上创建数据库和表,数据库分别是DBtest1 和 DBTest2,将DBTest1作为Master DB,将DBTest2作为Slave DB。
--default instance
CREATE TABLE [dbo].[Person](
[PersonID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[FirstName] sysname,
[MiddleName] sysname ,
[LastName] sysname,
constraint chk__Person_PersonType check([PersonType] in ('IN','EM','SP'))
); --named instance
CREATE TABLE [dbo].[Person](
[PersonID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[FirstName] sysname,
[MiddleName] sysname ,
[LastName] sysname,
constraint chk__Person_PersonType check([PersonType] in ('SC','VC','GC'))
);
Step3,在Master DB中,添加Linked Server
--add linked server
exec sys.sp_addlinkedserver @server= N'db1'
,@srvproduct= N''
,@provider= N'SQLNCLI'
,@datasrc= N'LJHPC\NamedInstance1'
,@location= null
,@provstr= null
,@catalog= N'dbtest2' --check
select *
from sys.servers
where is_linked=1 --drop linked server
--EXEC sys.sp_dropserver @server=N'db1', @droplogins='droplogins' --add login
exec sp_addlinkedsrvlogin @rmtsrvname = 'db1'
,@useself=false
,@locallogin=null
,@rmtuser ='sa'
,@rmtpassword='sa'
step4,创建分布式水平分区视图
create view dbo.view_Person
as
select [PersonID]
,[PersonType]
,[FirstName]
,[MiddleName]
,[LastName]
from [dbo].[Person] with(nolock)
where [PersonType] in('IN','EM','SP')
union all
select [PersonID]
,[PersonType]
,[FirstName]
,[MiddleName]
,[LastName]
from db1.[DBTest2].[dbo].[Person] with(nolock)
where [PersonType] in('SC','VC','GC')
with check OPTION;
Step5,查询分布式数据,查看执行计划
SELECT *
from dbo.view_Person p
where p.PersonType in ('em','sc')
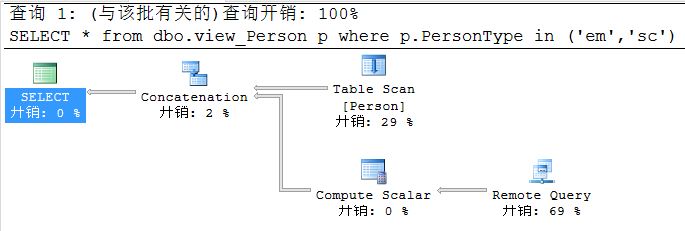
Step6,优化
分布式事务使用的资源远大于内部事务,通常使用OPENQUERY等相关行集函数,避免过度依赖分布式事务。
1,使用OpenQuery,避免DTC的干预
create view dbo.view_Person
as
select [PersonID]
,[PersonType]
,[FirstName]
,[MiddleName]
,[LastName]
from [dbo].[Person] with(nolock)
where [PersonType] in('IN','EM','SP')
union all
select [PersonID]
,[PersonType]
,[FirstName]
,[MiddleName]
,[LastName]
from OPENQUERY ( db1 ,
N'select [PersonID]
,[PersonType]
,[FirstName]
,[MiddleName]
,[LastName]
from db1.[DBTest2].[dbo].[Person] with(nolock)
where [PersonType] in(''SC'',''VC'',''GC'')' ) as p
with check OPTION;
2,在Local Server上更新分片数据
update db1.DBTEST2.dbo.person
set FirstName=N'Harm'
where PersonId=102; --修改成
exec db1.DBTEST2.sys.sp_executesql N'update dbo.person
set FirstName=N''Harm''
where PersonId=102;'
Appendix
--SQL Server 阻止了对组件 'Ad Hoc Distributed Queries'
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'Ad Hoc Distributed Queries',1
reconfigure
--使用完成后,关闭Ad Hoc Distributed Queries:
exec sp_configure 'Ad Hoc Distributed Queries',0
reconfigure
exec sp_configure 'show advanced options',0
reconfigure
参考doc:
Top 3 Performance Killers For Linked Server Queries
Distributed3:SQL Server 创建分布式数据库的更多相关文章
- Distributed2:SQL Server 创建分布式数据库
分布式数据库的优势是将IO分散在不同的Physical Disk上,每次查询都由多台Server的CPU,I/O共同负载,通过各节点并行处理数据来提高性能,劣势是消耗大量的网络带宽资源,管理难度大.在 ...
- sql server ------创建本地数据库 SQL Server 排序规则
sql server完整复制数据库 sql server导入导出方法 SQL Server 排序规则
- Confluence 6 SQL Server 创建一个数据库和数据库用户
一旦你成功安装了 SQL Server 服务器,请按照下面的方法为你的 Confluence 创建数据库用户和数据库: 使用你的 SQL 管理员权限,创建一个新的数据库(例如 confluence). ...
- SQL SERVER 创建远程数据库链接 mysql oracle sqlserver
遇到的坑 在连接Oracle时,因为服务器为10g 32位版本,然后在本地安装了32为10g客户端,然后一直报错[7302.7303],后来下载了12c 64位版本,安装成功后,问题解决 原因:mss ...
- SQL Server -----创建sqlserver 数据库 、表
新建数据库 1.右击 选择新建数据库 2.起一个名字 选择保存位置 3.放在之前建好的的文件夹中 点击确定 4.都要选择好 点击确定 5.确定之后如图 6.新建表 7.见一个表,常说的要满足三大 ...
- SQL Server 进阶 01 数据库的设计
SQL Server 进阶 01 数据库的设计 本篇目录 课程内容回顾及介绍 为什么需要规范的数据库设计 设计数据库的步骤 绘制E-R(实体-关系)图 实体-关系模型 如何将E-R图转换为表 数据规范 ...
- SQL Server 维护计划实现数据库备份(策略实战)
一.背景 之前写过一篇关于备份的文章:SQL Server 维护计划实现数据库备份,上面文章使用完整备份和差异备份基本上能解决数据库备份的问题,但是为了保障数据更加安全,我们需要再次完善我们的备份计划 ...
- SQL Server 2008 master 数据库损坏解决总结
SQL Server 2008 master数据库损坏后,SQL SERVER服务启动失败,查看错误日志,你会看到下面错误信息: 2015-10-27 10:15:21.01 spid6s ...
- SQL Server 2008 R2数据库镜像部署
概述 “数据库镜像”是一种针对数据库高可用性的基于软件的解决方案.其维护着一个数据库的两个相同的副本,这两个副本分别放置在不同的SQL Server数据库实例中.建议使用不同位置的两台服务器来承载.在 ...
随机推荐
- SQL Server 2012 数据库数据导出为脚本
转自:http://blog.csdn.net/ituff/article/details/8265822 将高版本的的SQL Server数据库移到低版本的SQL Server是一件十分蛋疼的事,最 ...
- Python调用HTTP接口并传递cookie
#get接口调用 import urllib import urllib2 get_url = "http://10.10.3.63/test?id=123&name=nba&quo ...
- seajs学习一天后的总结归纳
公司项目最近需要将js文件迁移到seajs来进行模块化管理,由于我以前主要接触模块化开发是接触的AMD规范的requireJS,没有接触过CMD规范,而且在实际项目中还没有用过类似技术.于是,我非常兴 ...
- linux shell重定向总结
command-line1 [-n] > file或文件操作符或设备 command-line1 [-n] >> file或文件操作符或设备 >suc.txt >err. ...
- java的基础知识运算符
一.运算符. 1.算数运算符:+,-,*,/,% 2.自增自减 :++ ,-- ++在前 先运算在赋值 ++在后 先赋值后运算 -- 减减同上. 3.赋值运算符 : = ,+=,-=,*=,/= 4. ...
- 深入理解javascript系列(4):立即调用的函数表达式
本文来自汤姆大叔 前言 大家学JavaScript的时候,经常遇到自执行匿名函数的代码,今天我们主要就来想想说一下自执行. 在详细了解这个之前,我们来谈了解一下“自执行”这个叫法,本文对这个功能的叫法 ...
- Spark优化之三:Kryo序列化
Spark默认采用Java的序列化器,这里建议采用Kryo序列化提高性能.实测性能最高甚至提高一倍. Spark之所以不默认使用Kryo序列化,可能的原因是需要对类进行注册. Java程序中注册很简单 ...
- centos7安装mysql5.7
http://jingyan.baidu.com/album/93f9803f010d8fe0e56f555e.html?picindex=15
- 关于[super dealloc]
销毁一个对象时,需要重写系统的dealloc方法来释放当前类所拥有的对象,在dealloc方法中需要先释放当前类中所有的对象,然后再调用[super dealloc]释放父类中所拥有的对象.如先调用[ ...
- linux 用户管理(一)
本节内容梗概: 1.用户管理配置文件 2.用户管理命令 3.用户组管理命令 4.批量添加用户 5.用户授权 学东西先讲原理,所以从配置文件入手 1.用户信息文件 /etc/passwd 存放了用户的 ...