MongoDB 数据分发
在MongoDB(版本 3.2.9)中,数据的分发是指将collection的数据拆分成块(chunk),分布到不同的分片(shard)上,数据分发主要有2种方式:基于数据块(chunk)数量的均衡分发和基于片键范围(range)的定向分发。MongoDB内置均衡器(balancer),用于拆分块和移动块,自动实现数据块在不同shard上的均匀分布。balancer只保证每个shard上的chunk数量大致相同,不保证每个shard上的doc数量大致相同。
一,数据按照chunk数量进行均衡分发
均衡分发是MongoDB自动实现的,使数据库架构对Application透明,简化系统的管理,使得向分片集群中增减分片变得容易。均衡分发是由MongoDB内置均衡器(balancer)来实现的,Balancer按照collection的索引字段来进行数据分发,该字段叫做片键(sharded key)。片键一般有三种类型:升序片键,随机片键和基于分组的片键。
块(chunk)是由多个doc组成的一个分组,在某个索引字段(片键)上是连续的,每个chunk的片键是有一定范围的。块的默认大小是64MB。有些chunk会非常大,包含的doc数量非常多,但是,在MongoDB看来,仍然是一个chunk,和没有任何doc的空chunk没有区别。均衡分发保证每个shard的chunk数量是大致相同的。因此,片键的选择直接影响分片的好坏。
例如:一个MongoDB分片集群有3个shard,分别是shard1,shar2,shard3。片键的最小值是:$MinKey,最大值是:$MaxKey。包含端值$MinKey的chunk是最小块,包含端值$MaxKey的chunk是最大块。
1,升序片键
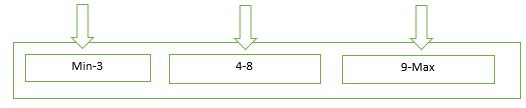
升序片键类似date字段或者_id字段,是一种随着时间稳定增长的字段。假如分片的字段是_id字段,集合foo中存在10个doc,每个shard中存在一个数据块,分别是:chunk1:$MinKey-3,chunk2:4-8,chunk3:9-$MaxKey。
使用升序片键的劣势是:每次插入一个新的doc,都会插入到最大块中,这会导致所有的写请求都会被路由到同一个分片,导致最大块不断增长,不断被拆分,然后不断被移动到其他分片中,导致数据的写入不均衡,块移动会额外增加Disk的写数量。使用升序片键的优势是:按照片键进行范围读时,性能高。

2,随机片键
随机片键是指片键的值不是固定增长,而是一些没有规律的键值。由于写入数据是随机分发的,各分片增长的速度大致相同,减少了chunk 迁移的次数。使用随机分片的弊端是:写入的位置是随机的,如果使用Hash Index来产生随机值,那么范围查询的速度会很慢。
3,基于分组的片键
基于分组的片键是两字段的复合片键,第一个字段用于分组,该字段的势最好是比较低的,势是在同一字段中不同值(distinct value)的数量或所占的比例;第二个字段用于自增,该字段最好是自增字段。这种片键策略是最好的,能够实现多热点数据的读写。
单个mongod 在处理升序写请求时是最有效的,数据只需要写入到集合的末尾。基于分组的片键,将数量不多的分组分布在分片集群中,每个shard只有少量的chunk,这样能够将数据的写操作分布在分片集群中的每个shard上,在单个shard上,以升序方式读写数据。一个shard上的分组太多,写请求就相当于随机写了,反而不好。
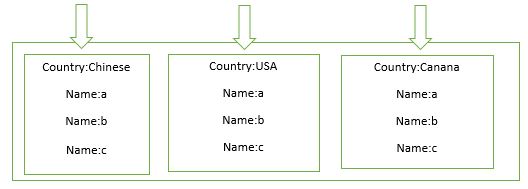
二,按照片键范围进行定向分发
如果希望特定范围的chunk被分发到特定的分片中,可以为分片添加tag,然后为tag指定相应的片键范围,这样,如果一个doc属于tag的片键范围,就会被定向到特定的shard中。
1,为shard指定tag
sh.addShardTag("shar1","shard_tag1");
sh.addShardTag("shar2","shard_tag2");
sh.addShardTag("shar3","shard_tag2");
2,为tag指定片键范围
sh.addTagRange(
"db_name.collection_name",
{field:"min_value"},
{field:"max_value"},
"shard_tag"
)
每个shard的tag可以使用任意数量的tag,MongoDB的均衡器在移动块时,会将特定片键范围的chunk移动到特定的shard上。
三,手动进行数据的分发
MongoDB内置均衡器(balancer),自动实现数据块的拆分和移动,有时,可以关闭balancer,使用moveChunk命令手动移动数据块。
1,关闭balancer
连接到一个mongos,更新config.setting命名空间
use config
db.setting.update({"_id":"balancer"},{"enabled":false},true) --or
sh.setBalancerState(false);
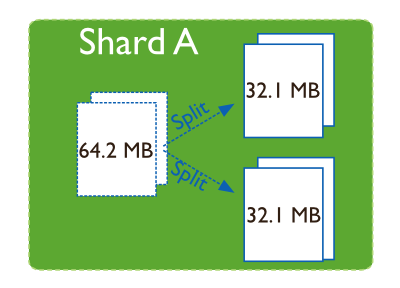
2,拆分块
拆分块是指新增一个边界点,将一个chunk在边界点处拆分成两个chunk。在MongoDB中,将片键从小到大排序,边界值属于右边的chunk。
sh.splitAt("db_name.collection_name",{sharded_filed:"new_boundary_value"})
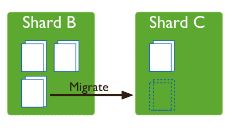
3,移动块
MongoDB将包含指定文档的chunk移动到指定的shard上,必须使用片键来查找所要一定的chunk。
sh.moveChunk("db_name.collection_name",{sharded_filed:"value_in_chunk"},"new_shard_name")
4,启用balancer
sh.setBalancerState(true)
5,刷新mongos的缓存
在Application layer 和数据存储之间,存在一个Query Router,即mongos,mongos会在第一次启动或分片的元数据被更新之后,从config server 同步配置数据,并缓存在mongos中。有时,mongos无法从config server上及时同步最新的配置信息,导致无法路由到相应的chunk,不能返回正确的数据,可以使用flushRouterConfig 命令手动刷新mongos的缓存
db.adminCommand({"flushRouterConfig":1})
参考文档:
MongoDB 数据分发的更多相关文章
- MongoDB 分片键分类与数据分发
In sharded clusters, if you do not use the _id field as the shard key, then your application must en ...
- [更新]跨平台物联网通讯框架 ServerSuperIO v1.2(SSIO),增加数据分发控制模式
1.[开源]C#跨平台物联网通讯框架ServerSuperIO(SSIO) 2.应用SuperIO(SIO)和开源跨平台物联网框架ServerSuperIO(SSIO)构建系统的整体方案 3.C#工业 ...
- MongoDB 数据迁移和同步
MongoDB 数据迁移和同步 MongoDB的数据同步 复制 mongodb的复制至少需要两个实例.其中一个是主节点master,负责处理客户端请求,其余的都是slave,负责从master上复制数 ...
- mongoDB 数据导出与导入
一.导出 命令格式:在mongodb/bin目录下 mongoexport -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 -c 表名 -f 字段 -q 条件导出 --csv ...
- MongoDB副本集配置系列十一:MongoDB 数据同步原理和自动故障转移的原理
1:数据同步的原理: 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步: 1:检查自己local库的oplog.rs集合找出最近的时间戳. 2:检查Primary ...
- mongodb数据文件内部结构
有人在Quora上提问:MongoDB数据文件内部的组织结构是什么样的.随后10gen的工程师Jared Rosoff出来做了简短的回答. 每一个数据库都有自己独立的文件.如果你开启了director ...
- 用elasticsearch索引mongodb数据
参照网页:单机搭建elasticsearch和mongodb的river 三个步骤: 一,搭建单机replicSet二,安装mongodb-river插件三,创建meta,验证使用 第一步,搭建单机m ...
- MongoDB学习笔记(三) 在MVC模式下通过Jqgrid表格操作MongoDB数据
看到下图,是通过Jqgrid实现表格数据的基本增删查改的操作.表格数据增删改是一般企业应用系统开发的常见功能,不过不同的是这个表格数据来源是非关系型的数据库MongoDB.nosql虽然概念新颖,但是 ...
- Mongodb数据备份恢复
Mongodb数据备份恢复 一.MongoDB数据库导入导出操作 1.导出数据库 twangback为备份的文件夹 命令: mongodump -h 127.0.0.1[服务器IP] -d advie ...
随机推荐
- mysql 数据库可以非本地访问
GRANT ALL PRIVILEGES ON 数据库名.* TO root@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
- three.js全景
<!DOCTYPE html> <html lang="en"> <head> <title>three.js webgl - eq ...
- java并发J.U.C AtomicReference VS Volatile
SpinLock实现,摘自并发编程网 package com.juc.simple; import java.util.concurrent.atomic.AtomicReference; /** * ...
- volatile不能保证原子性
1.看图自己体会 2.体会不了就给你个小程序 package cs.util; public class VolatileDemo { private volatile int count =0; p ...
- 统计学习方法 --- 感知机模型原理及c++实现
参考博客 Liam Q博客 和李航的<统计学习方法> 感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而 ...
- 获取设备UDID、IMEI、ICCID、序列号、Mac地址等信息
在iOS7之前, 可以方便的使用 [[UIDevice currentDevice] uniqueIdentifier] 来获取设备的UDID,但是在iOS7之后这个方法不再适用. 你可以用[[UID ...
- postman测试接口之POST提交本地文件数据
前言: 接口测试时,有时需要读取文件的数据:那么postman怎么添加一个文件作为参数呢? 实例: 接口地址: http://121.xxx.xxx.xxx:9003/marketAccount/ba ...
- Ubuntu install JDK适合像我的小白
1.#下载JDK,记住保存的目录 2. sudo mkdir /usr/java 3. sudo tar zxvf jdk-7u75-linux-x64.tar.gz -C /usr/java 4. ...
- Linux 升级glibc-2.14 失败 我遇到的问题
直接说步骤和流程: 1.到http://www.gnu.org/software/libc/下载最新版本,我这里下载了glibc-2.14.tar.gz 这个版本,解压到任意目录准备编译(/usr/l ...
- (学)解决诡异的 Exception type: SocketException 127.0.0.1:80
许久不发博了,老杨听完故事让我持续写一下“十万个为什么” 一.背景: 昨天我们亲密的战友HH刘老板亲临现场,指出我们协用的一个项目,客户方面反馈手持终端系统不定期“卡死”,要我们安排人飞到广州驻场解 ...