Python机器学习2.2
使用Python实现感知器学习算法
在《Python机器学习》中的2.2节中,创建了罗森布拉特感知器的类,通过fit方法初始化权重self.w_,再fit方法循环迭代样本,更新权重,使用predict方法计算类标,将每轮迭代中错误分类样本的数量存放于列表self.errors_中。罗森布拉特感知器可以参考这个网址或自行百度。https://www.jb51.net/article/130970.htm
import numpy as np
class Perceptron(object):
"""感知器分类器. 参数
----------
eta(学习速率) : float
学习率(介于0和1之间)
n_iter(迭代次数) : int
通过训练数据集. 属性
----------
w_ : id-array
fit方法后的权重.
errors_ : list
每轮迭代错误分类样本的数量存放列表. """
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter def fit(self, X, y):
"""拟合训练数据. 参数
----------
X : {array-like}, shape = {n_samples, n_features}
训练向量, 其中n_samples是样本的数目,
n_features是特征的数目(维数).
y : array-like, shape = {n_samples}
目标值. 返回
----------
self : object """
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = [] for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0] def predict(self, X):
"""每一步后返回类标签"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
Perceptron类
书中选用了鸢尾花数据集中的山鸢尾(Setosa)和变色鸢尾(Versicolor)俩种信息作为测试数据。出于可视化,选取了萼片长度(sepal length)和花瓣长度(petal-length)两个特征。
使用pandas库直接从UCI机器学习库中获取鸢尾花数据集(iris.data)并转换为DataFrame对象加载到内存中,使用tail方法显示数据确保正确加载。
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
df.tail()
获取iris.data

提取前100个类标,其中山鸢尾(Setosa)和变色鸢尾(Versicolor)各50个,并将类标用两个整数表示:1表示变色鸢尾,-1表示山鸢尾,赋给NumPy的向量y。类似的,提取前100个训练样本的第一个特征列()和第三个特征列(),赋给X。用二位散点图进行可视化。
import matplotlib.pyplot as plt
import numpy as np
#jupyter notebook显示图片
%matplotlib inline
#中文字体显示
plt.rc('font', family='SimHei', size=13) y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0,2]].values
plt.scatter(X[:50, 0], X[:50, 1],
color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1],
color='blue', marker='x', label='versicolor')
plt.xlabel('花瓣长度(cm)')
plt.ylabel('萼片长度(cm)')
plt.legend(loc='upper left')
plt.show()
可视化

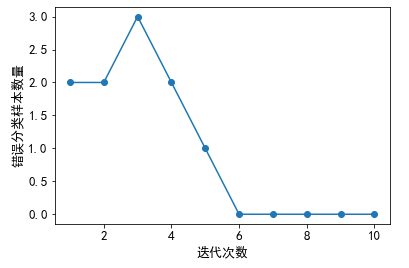
利用抽取的鸢尾花数据子集训练感知器。绘制每次迭代错误分类数量的折线图。
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_,
marker='o')
plt.xlabel('迭代次数')
plt.ylabel('错误分类样本数量')
plt.show()
检验算法
待续。。。
Python机器学习2.2的更多相关文章
- 常用python机器学习库总结
开始学习Python,之后渐渐成为我学习工作中的第一辅助脚本语言,虽然开发语言是Java,但平时的很多文本数据处理任务都交给了Python.这些年来,接触和使用了很多Python工具包,特别是在文本处 ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 【转】常见的python机器学习工具包比较
http://algosolo.com/ 分析对比了常见的python机器学习工具包,包括: scikit-learn mlpy Modular toolkit for Data Processing ...
- python机器学习《回归 一》
唠嗑唠嗑 依旧是每一次随便讲两句生活小事.表示最近有点懒,可能是快要考试的原因,外加这两天都有笔试和各种面试,让心情变得没那么安静的敲代码,没那么安静的学习算法.搞得第一次和技术总监聊天的时候都不太懂 ...
- 2016年GitHub排名前20的Python机器学习开源项目(转)
当今时代,开源是创新和技术快速发展的核心.本文来自 KDnuggets 的年度盘点,介绍了 2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们 ...
- [resource]Python机器学习库
reference: http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块: ...
- Python机器学习包
常用Python机器学习包 Numpy:用于科学计算的包 Pandas:提供高性能,易于使用的数据结构和数据分析工具 Scipy:用于数学,科学工程的软件 StatsModels:用于探索数据.估计统 ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
随机推荐
- bzoj 2331: [SCOI2011]地板【插头dp】
一开始设计了四种状态,多了一种已经拐弯但是长度为0的情况,后来发现不用,设012表示没插头,没拐弯的插头,拐了弯的插头,然后转移的话12,21,22都不合法,剩下的转移脑补一下即可,ans只能在11, ...
- Luogu P3393 逃离僵尸岛【最短路】By cellur925
题目传送门 题目大意:(其实概括出来也就基本做完了hh)在一张有$n$个点,$m$条边的无向图上,有$k$个点是不能经过的,而与之距离不超过$s$的点,到他们会花费$Q$元,到其他点会花费$p$元,求 ...
- iptables 使用总结
Linux 系统的防火墙功能是由内核实现的 2.0 版内核中,包过滤机制是 ipfw,管理工具是 ipfwadm 2.2 版内核中,包过滤机制是 ipchain,管理工具是 ipchains 2.4 ...
- Odd sum CodeForces - 797B
Odd sum CodeForces - 797B 好方法:贪心 贪心2 糟糕(不用动脑)的方法:dp ans[i][0]表示到第i个和为偶数最大,ans[i][1]表示到第i个和为奇数最大. 但是, ...
- Android APK加壳技术方案
Android APK加壳技术方案[1] Android APK加壳技术方案[2]
- 168 Excel Sheet Column Title Excel表列名称
给定一个正整数,返回它在Excel表中相对应的列名称.示例: 1 -> A 2 -> B 3 -> C ... 26 -> Z 27 -&g ...
- KEIL软件仿真死在等待外部晶振起振
这是由于是Debug里面的设置有问题 主要是下面2项设置 Dialog DLL默认是DCM3.DLL Parameter默认是-pCM3 应改为 Dialog DLL默认是DARMSTM.DLL Pa ...
- 微服务dubbo面试题
dubbo的工作原理? dubbo支持的序列化协议? dubbo的负载均衡和高可用策略?动态代理策略? dubbo的SPI思想? 如何基于dubbo进行服务治理.服务降级.失败重试以及超时重试? du ...
- python_9(模块补充)
第1章 re模块补充 1.1 贪婪匹配:回溯算法 1.2 .*?的用法 1.3 例:分组<name>取值 1.4 匹配整数删除小数 1.5 正则测试地址 第2章 重点模块 2.1 hash ...
- solr 常见异常
solr4.3本地数据提交异常分析 (2013-06-19 16:03:15) 转载▼ 异常一. Exception in thread "main" java.lang.No ...