python爬虫慕课基础2
实战演练:爬取百度百科1000个页面的数据

对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序
发现以下错误:
requests.exceptions.TooManyRedirects: Exceeded 30 redirects
错误提示是requests库有太多的重定向:超过了30个重定向。
查找别人的解决方式:
我是通过steam的appid来进行遍历的,但是steam不是所有appid都对应一个游戏,也就是说有一些是空的。这种情况下steam会重定向至steam主页,就会产生这个问题。
所以,我最终的解决方案就是仅请求不允许重新定向,因为重新定向中没有我需要的信息。在requests请求中添加一个对应的字段就ok了:
req=requests.get(url,headers=header,allow_redirects=False)这样就不会弹出上面的错误提示了,但是也关闭了重定向的功能。
发现以下错误:
Traceback (most recent call last):
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 39, in <module>
obj_spider.craw(root_url)
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 20, in craw
new_urls, new_data = self.parser.parse(new_url, html_cont)
TypeError: 'NoneType' object is not iterable
在20行上加入输出
html_cont = self.downloader.download(new_url) # content存放下载的url
print(html_cont)
new_urls, new_data = self.parser.parse(new_url, html_cont)
输出为空None,说明错误在downloader中 使用第三方包requests会导致302重定向问题,原因不明
改为使用urllib的request
成功爬取 生成的html文件直接打开是乱码,用txt打开则正常
加入语句fout.write('<meta charset="utf-8">')后输出正常
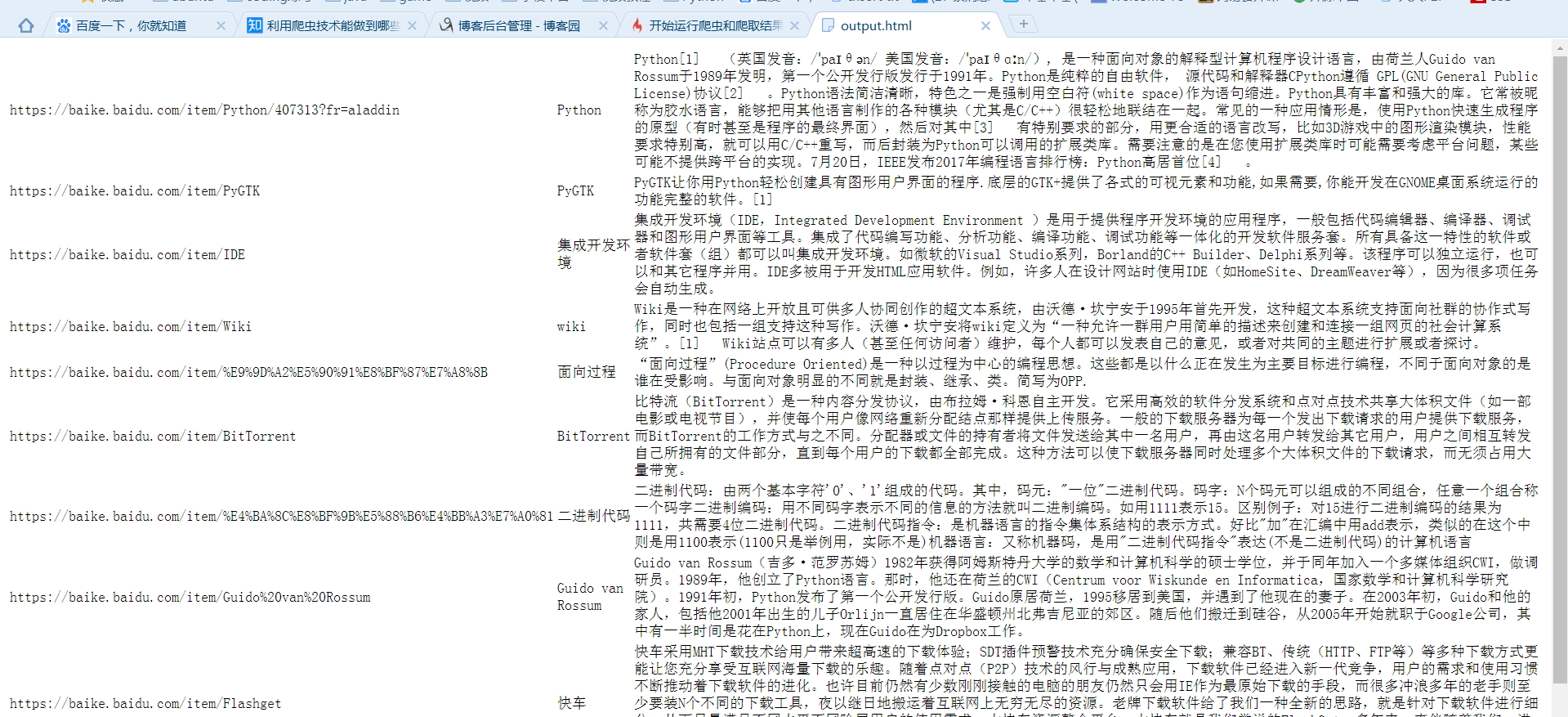
爬取时会遇到两个问题中止程序。a:网址中含有中文,b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错
a:网址中含有中文使用
url_ = quote(url, safe=string.printable)
解决问题
b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错添加判断语句解决:
if summary_node is not None:
res_data['summary'] = summary_node.get_text()
查看拼接url:
print('url拼接:', page_url, new_url, new_full_url) # 查看如何拼接
输出为:
url拼接: https://baike.baidu.com/item/Python/407313?fr=aladdin /item/史记·2016?fr=navbar https://baike.baidu.com/item/史记·2016?fr=navbar
可知:
通过正则表达式
links = soup.find_all('a', href=re.compile(r"/item/"))
获得的是/item/及后面部分如/item/史记·2016?fr=navbar
python爬虫慕课基础2的更多相关文章
- python爬虫慕课基础1
test_urllib2.py import http.cookiejar from urllib import request url = "http://www.baidu.com&qu ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
- python爬虫相关基础概念
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.但是php在实现爬虫中支持多线程和多进程方面做得不好. 2.java ...
- Python爬虫零基础入门(系列)
一.前言上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. update ...
- Python爬虫-正则表达式基础
import re #常规匹配 content = 'Hello 1234567 World_This is a Regex Demo' #result = re.match('^Hello\s\d\ ...
- python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一) 网络爬虫 网络爬虫也叫网络蜘蛛.网络机器人.如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情.网络爬虫的产生就是代替人 ...
- Python爬虫入门(1-2):综述、爬虫基础了解
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python实战:爬虫的基础
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
随机推荐
- 搭建gogs常见问题
1.无法连接ssh,显示connection refuse. 原因是“custom/conf/app.ini”没有开启ssh功能,改为以下配置就行了 START_SSH_SERVER = true ...
- Java简单工厂模式(SimpleFactoryMode)
何为简单工厂模式? 由一个工厂类根据传入的参数,动态创建并返回相应的具体的实例! 三个构成元素: 1.工厂类 2.抽象产品 3.具体产品 优点: 1.提高扩展性 2.隐藏具体的实现类,并不需要知道产品 ...
- TCP/IP 和 HTTP 的区别和联系是什么?
作者:车小胖链接:https://www.zhihu.com/question/38648948/answer/240006409来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注 ...
- Billiard CFR484 div2 (数论)
就是一个点从开始的点在一个矩形内往某个方向一直运动,如果碰到了矩形的边,那么就反弹,我们可以把这个矩形拓展开,那么就是问题变成了我有没有一个点,这个点的坐标(Tx, Ty)满足n|Tx,m|Ty 那么 ...
- 洛谷P2468 SDOI 2010 粟粟的书架
题意:给你一个矩形书架,每个点是这本书的页数,每次询问(x1,y1)(x2,y2)这个小矩形里最少需要取几本书使得页数和等于Hi. 题解:小数据二位前缀和预处理+二分答案,大数据一行所以用主席树做,感 ...
- C/C++ 控制台窗口暂停
为什么我看不到控制台的输出结果? 在编写C++程序中,经常会出现,控制台窗口一闪就消失了的情况 为什么会这样? 原因简单到有点可笑:因为程序运行结束了 对于控制台程序,操作系统让它开始运行前会为它造一 ...
- hdu1272 小希的迷宫(并查集)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1272 题目: 小希的迷宫 Time Limit: 2000/1000 MS (Java/Others) ...
- twitter api
1,twurl安装 1.1,安装软件管理包工具,在管理员身份打开的cmd中执行: @"%SystemRoot%\System32\WindowsPowerShell\v1.0\powersh ...
- 设置SVN不需要提交的文件
设置SVN不需要提交的文件 .project .classpath .settings .externalToolBuilders 也可以在TortoiseSVN中设置
- Flask 键盘事件
<div class="container" style="margin-top: 300px; "> <div class="ro ...