python爬虫慕课基础2
实战演练:爬取百度百科1000个页面的数据

对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序
发现以下错误:
requests.exceptions.TooManyRedirects: Exceeded 30 redirects
错误提示是requests库有太多的重定向:超过了30个重定向。
查找别人的解决方式:
我是通过steam的appid来进行遍历的,但是steam不是所有appid都对应一个游戏,也就是说有一些是空的。这种情况下steam会重定向至steam主页,就会产生这个问题。
所以,我最终的解决方案就是仅请求不允许重新定向,因为重新定向中没有我需要的信息。在requests请求中添加一个对应的字段就ok了:
req=requests.get(url,headers=header,allow_redirects=False)这样就不会弹出上面的错误提示了,但是也关闭了重定向的功能。
发现以下错误:
Traceback (most recent call last):
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 39, in <module>
obj_spider.craw(root_url)
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 20, in craw
new_urls, new_data = self.parser.parse(new_url, html_cont)
TypeError: 'NoneType' object is not iterable
在20行上加入输出
html_cont = self.downloader.download(new_url) # content存放下载的url
print(html_cont)
new_urls, new_data = self.parser.parse(new_url, html_cont)
输出为空None,说明错误在downloader中 使用第三方包requests会导致302重定向问题,原因不明
改为使用urllib的request
成功爬取 生成的html文件直接打开是乱码,用txt打开则正常
加入语句fout.write('<meta charset="utf-8">')后输出正常
爬取时会遇到两个问题中止程序。a:网址中含有中文,b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错
a:网址中含有中文使用
url_ = quote(url, safe=string.printable)
解决问题
b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错添加判断语句解决:
if summary_node is not None:
res_data['summary'] = summary_node.get_text()
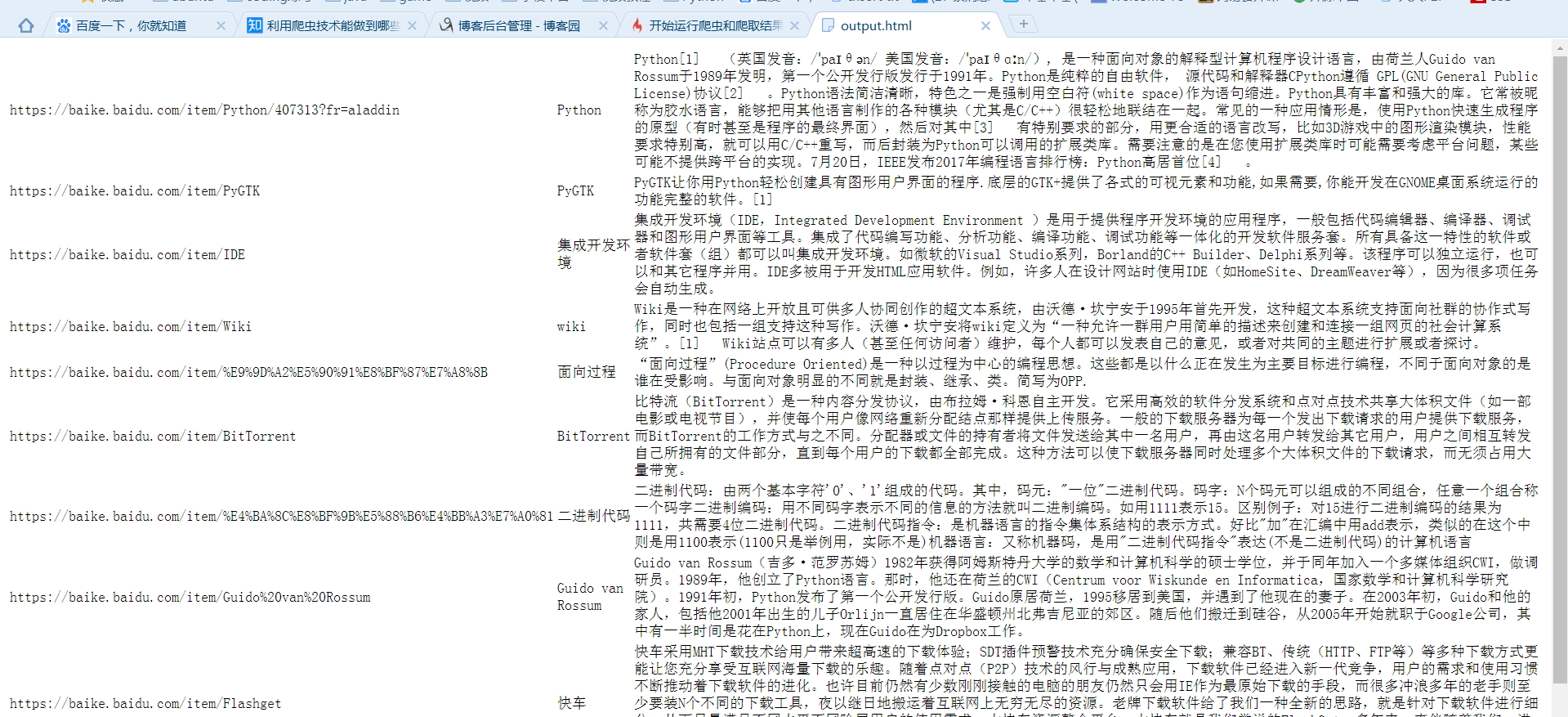
查看拼接url:
print('url拼接:', page_url, new_url, new_full_url) # 查看如何拼接
输出为:
url拼接: https://baike.baidu.com/item/Python/407313?fr=aladdin /item/史记·2016?fr=navbar https://baike.baidu.com/item/史记·2016?fr=navbar
可知:
通过正则表达式
links = soup.find_all('a', href=re.compile(r"/item/"))
获得的是/item/及后面部分如/item/史记·2016?fr=navbar
python爬虫慕课基础2的更多相关文章
- python爬虫慕课基础1
test_urllib2.py import http.cookiejar from urllib import request url = "http://www.baidu.com&qu ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
- python爬虫相关基础概念
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.但是php在实现爬虫中支持多线程和多进程方面做得不好. 2.java ...
- Python爬虫零基础入门(系列)
一.前言上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. update ...
- Python爬虫-正则表达式基础
import re #常规匹配 content = 'Hello 1234567 World_This is a Regex Demo' #result = re.match('^Hello\s\d\ ...
- python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一) 网络爬虫 网络爬虫也叫网络蜘蛛.网络机器人.如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情.网络爬虫的产生就是代替人 ...
- Python爬虫入门(1-2):综述、爬虫基础了解
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python实战:爬虫的基础
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
随机推荐
- topcoder SRM642 div1 hard WheelofFortune
题目链接:vjudge 大意:有两个人参加一场游戏,这个游戏在一个编号为\(0\text~n-1\)的轮盘上进行,一开始轮盘上的数字均为0:一共有\(m\)轮,每一轮都有一个操作参数\(s_i\),主 ...
- php插入日志到数据库,对象转json
打印插入日志数据到库 M()->table("t_log")->data(array( 'id'=>'6'.time(), 't'=> json_encod ...
- MT【310】均值不等式
(2014北约自主招生)已知正实数$x_1,x_2,\cdots,x_n$满足$x_1x_2\cdots x_n=1,$求证:$(\sqrt{2}+x_1)(\sqrt{2}+x_2)\cdots(\ ...
- The Python Challenge 谜题全解(持续更新)
Python Challenge(0-2) The Python Challengehttp://www.pythonchallenge.com/ 是个很有意思的网站,可以磨练使用python的技巧, ...
- Python的快排应有的样子
快排算法 简单来说就是定一个位置然后,然后把比它小的数放左边,比他大的数放右边,这显然是一个递归的定义,根据这个思路很容易可以写出快排的代码 快排是我学ACM路上第一个让我记住的代码,印象很深 ...
- 「SCOI2016」背单词 解题报告
「SCOI2016」背单词 出题人sb 题意有毒 大概是告诉你,你给一堆n个单词安排顺序 如果当前位置为x 当前单词的后缀没在这堆单词出现过,代价x 这里的后缀是原意,但不算自己,举个例子比如abc的 ...
- poj2373 Dividing the Path (单调队列+dp)
题意:给一个长度为L的线段,把它分成一些份,其中每份的长度∈[2A,2B]且为偶数,而且不能在某一些区间内部切开,求最小要分成几份 设f[i]为在i处切一刀,前面的满足要求的最小份数,则f[L]为答案 ...
- OO第一阶段纪实
$ 0 写在前面 在DDL一次次的推动下,历经三个周期的更迭,一个月的时光匆匆而过.谨撰此博文,以记录这一段见证成长的心路历程. $ 0-0 JAVA“一天速成”没有修习过传说中的“OO先导课”,在学 ...
- [hdu5215][Cycle]
题目链接 思路 首先可以通过二分图染色找到奇环和一部分偶环.这个比较简单 但是还有一种偶环容易忽略. 如图(别问我为啥没节点4) 第一次可以找到1-2-3-1)这个奇环,第二次可以找到(3-5-6-3 ...
- System.Web.Optimization对脚本和样式表的压缩操作
1 是否允许样式表压缩 BundleTable.EnableOptimizations = true; 在MVC项目中的 BundleConfig操作中是微软已经给我们准备好的CSS和JS压缩,我们可 ...