oracle数据泵导入导出命令
1.在PL/SQL的界面,找到Directories文件夹,找到目录文件的路径
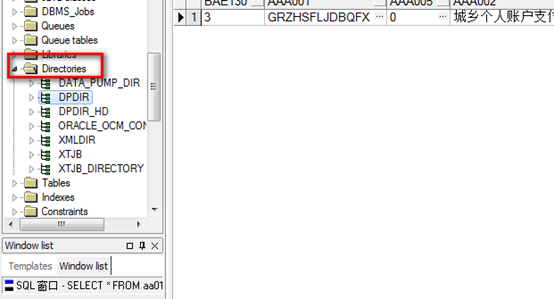
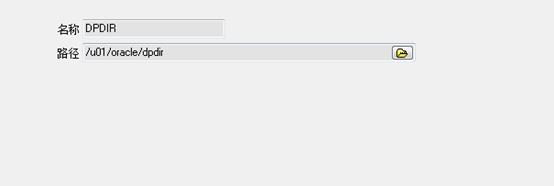
2.通过SSH进入服务器
找到相应的路径 cd /u01/oracle/dpdir
输入指令
df -h 查看资源使用量
su – oracle 进入系统的oracle用户
3.导出数据库文件
expdp userid=hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp job_name=hbcxjm logfile=hbcxjmlog parallel=2 schemas=hbcxjm
PS:
其中userid是要导出的目标库的用户名密码,directory是建立的路径名称,dumpfile是目标文件名称
4.新建数据库用户
PS:注意表空间问题,确保表空间充足,否则导入会报错
5.导入数据
impdp hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp REMAP_SCHEMA=hbcxjm:hbcxjm REMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJM
table_exists_action = truncate logfile=hbcxjmimp.log SCHEMAS=hbcxjm
PS:
REMAP_SCHEMA:导出数据用户的名称和导入数据用户的名称
REMAP_TABLESPACE:导出数据用户的表空间和导入数据用户的表空间
table_exists_action:如果表中有数据的处理方式,此处采用truncate处理
logfile:日志文件名称
例子:
文件导出:
expdp userid=hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp job_name=hbcxjm logfile=hbcxjmlog parallel=2 schemas=hbcxjm
expdp userid=drm_hbcxjm/oracle directory=dpdir dumpfile=drm_hbcxjm.dmp job_name=drm_hbcxjm logfile=drm_hbcxjmlog parallel=2 schemas=drm_hbcxjm
expdp userid=hbcxjm_report/oracle directory=dpdir dumpfile=hbcxjm_report.dmp job_name=hbcxjm_report logfile=hbcxjm_reportlog parallel=2 schemas=hbcxjm_report
expdp userid=hbcxjm_siif/oracle directory=dpdir dumpfile=hbcxjm_siif.dmp job_name=hbcxjm_siif logfile=hbcxjm_siiflog parallel=2 schemas=hbcxjm_siif
expdp userid=hxpt3dd/oracle directory=dpdir dumpfile=hxpt3dd.dmp job_name=hxpt3dd logfile=hxpt3ddlog parallel=2 schemas=hxpt3dd
expdp userid=drm_hxpt3dd/oracle directory=dpdir dumpfile=drm_hxpt3dd.dmp job_name=drm_hxpt3dd logfile=drm_hxpt3ddlog parallel=2 schemas=drm_hxpt3dd
文件导入:
impdp hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp REMAP_SCHEMA=hbcxjm:hbcxjm REMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJM table_exists_action = truncate logfile=hbcxjmimp.log SCHEMAS=hbcxjm
impdp drm_hbcxjm/oracle directory=dpdir dumpfile=drm_hbcxjm.dmp REMAP_SCHEMA=drm_hbcxjm:drm_hbcxjm REMAP_TABLESPACE=TP_HBCXJM_DRM:TP_HBCXJM_DRM table_exists_action = truncate logfile=drm_hbcxjmimp.log SCHEMAS=drm_hbcxjm
impdp hbcxjm_report/oracle directory=dpdir dumpfile=hbcxjm_report.dmp REMAP_SCHEMA=hbcxjm_report:hbcxjm_report REMAP_TABLESPACE=TP_HBCXJM_DRM:TP_HBCXJM_DRM table_exists_action = truncate logfile=hbcxjm_reportimp.log SCHEMAS=hbcxjm_report
impdp hbcxjm_siif/oracle directory=dpdir dumpfile=hbcxjm_siif.dmp REMAP_SCHEMA=hbcxjm_siif:hbcxjm_siif REMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJM table_exists_action = truncate logfile=hbcxjm_siifimp.log SCHEMAS=hbcxjm_siif
impdp hxpt3dd/oracle directory=dpdir dumpfile=hxpt3dd.dmp REMAP_SCHEMA=hxpt3dd:hxpt3dd REMAP_TABLESPACE=TP_HBCXJM_YBDD:TP_HBCXJM_YBDD table_exists_action = truncate logfile=hxpt3ddimp.log SCHEMAS=hxpt3dd
impdp drm_hxpt3dd/oracle directory=dpdir dumpfile=drm_hxpt3dd.dmp REMAP_SCHEMA=drm_hxpt3dd:drm_hxpt3dd REMAP_TABLESPACE=TP_HBCXJM_YBDD:TP_HBCXJM_YBDD table_exists_action = truncate logfile=drm_hxpt3ddimp.log SCHEMAS=drm_hxpt3dd
oracle数据泵导入导出命令的更多相关文章
- Oracle 数据泵导入导出总结
Oracle 数据泵(IMPDP/EXPDP)导入导出总结 Oracle数据泵导入导出是日常工作中常用的基本技术之一,它相对传统的逻辑导入导出要高效,这种特性更适合数据库对象数量巨大的情形,因为我日常 ...
- 【EXPDP/IMPDP】ORACLE数据泵导入导出案例(expdp & impdp)
概要: 因项目需要,通常需要将生产库下的部分数据抽取并恢复到测试库上 本文主要介绍数据泵导入导出的几种情况以及错误处理 案例环境: rhel-server-6.5-x86_64 oracle 11.2 ...
- Oracle数据泵导入导出数据,建立表空
Oracle11g 数据导入到oracle10g 中:1.在oracle11g 服务器命令行中用expdp 导出数据expdp ts/ts@orcl directory=expdp_dir dumpf ...
- 基于多用户的Oracle数据泵导入导出数据
登陆SqlPlus: SqlPlus sys/syspwd@MyOrcl AS sysdba 其中:syspwd:sys的登陆密码:MyOrcl:所创建的数据库服务名. 创建数据泵: create o ...
- oracle数据泵导入导出部分用户
问题描述:需要将140服务器中的tbomnew实例下的部分用户导入到118服务器下的tbompx实例中,本次导入导出的两个数据库均为19C 部分用户名:CORE,MSTDATA,BOMMGMT,CFG ...
- oracle数据泵导入导出
1.首先建立DUMP_DIR sqlplus / as sysdba select * from dba_directories 如果没有DUMP_DIR就执行下面的语句 CREATE OR REPL ...
- Oracle基础 exp/imp 数据泵导入/导出 命令
一.导出方式: 使用exp/imp方式导出数据分为四种方式: 1.表方式导出:一个或多个指定的表,包括表的定义.表数据.表的所有者授权.表索引.表约束,以及创建在该表上的触发器.也可以只导出结构,不导 ...
- oracle数据泵导入导出数据
expdp 导出 1.管理员用户登入sqlplus sqlplus system/manger@pdb1 2.创建逻辑导出目录 create directory dpdata as '/home/or ...
- Oracle 数据泵导入导出
imp zminfo/zminfo fromuser=zminfo touser=zminfo file=E:\zBONDDT.dmp log=e:\bonddt.log buffer=1000000 ...
随机推荐
- 性能测试工具 Locust
https://docs.locust.io/en/latest/quickstart.html
- BZOJ5119 生成树计数(prufer+生成函数+分治FFT+多项式exp)
https://www.luogu.org/problemnew/solution/P4002 神树的题解写的很清楚了.稍微补充: 1.[x^i]ln(A(ax))=a^i[x^i]ln(A(x)), ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- P1064 金明的预算方案
思路:就是一个背包问题 因为数据范围小,所以不把 1个带附着物的东西 拆成 带1个带2个或不带 #include<bits/stdc++.h> using namespace std; ...
- scrapy 登陆知乎
参考 https://github.com/zkqiang/Zhihu-Login # -*- coding: utf-8 -*- import scrapy import time import r ...
- SpringMVC 拦截器使用说明
spring-content.xml <!-- 配置用于session验证的拦截器 --> <!-- 如果有多个拦截器满足拦截处理的要求,则依据配置的先后顺序来执行 --> & ...
- 【CF997E】Good Subsegments (线段树+单调栈)
Description 原题链接 给你一个长度为\(n\)的排列\(~P\),定义一段子区间是好的,当且仅当这个子区间内的值构成了连续的一段.例如对于排列\(\{1,3,2 \}\),\([1, 1] ...
- 洛谷AT2046 Namori(思维,基环树,树形DP)
洛谷题目传送门 神仙思维题还是要写点东西才好. 树 每次操作把相邻且同色的点反色,直接这样思考会发现状态有很强的后效性,没办法考虑转移. 因为树是二分图,所以我们转化模型:在树的奇数层的所有点上都有一 ...
- 【Luogu3602】Koishi Loves Segments(贪心)
[Luogu3602]Koishi Loves Segments(贪心) 题面 洛谷 题解 离散区间之后把所有的线段挂在左端点上,从左往右扫一遍. 对于当前点的限制如果不满足显然会删掉右端点最靠右的那 ...
- luogu3811 乘法逆元
逆元定义:若a*x=1(mod p),(a,p互质),则x为a mod p意义下的逆元 做法见https://www.luogu.org/blog/zjp-shadow/cheng-fa-ni-yua ...