HyperLedger Fabric 1.0的Transaction处理流程
如果把区块链比作一个只能读写,不能删改的分布式数据库的话,那么事务和查询就是对这个数据库进行的最重要的操作。以比特币来说,我们通过钱包或者Blockchain.info进行区块链的查询操作,而转账行为就是Transaction的处理。而HyperLedger Fabric在1.0对系统架构进行了升级,使得事务的处理更加复杂。
一、架构
让我们来看看Fabric 0.6到1.0的架构图:
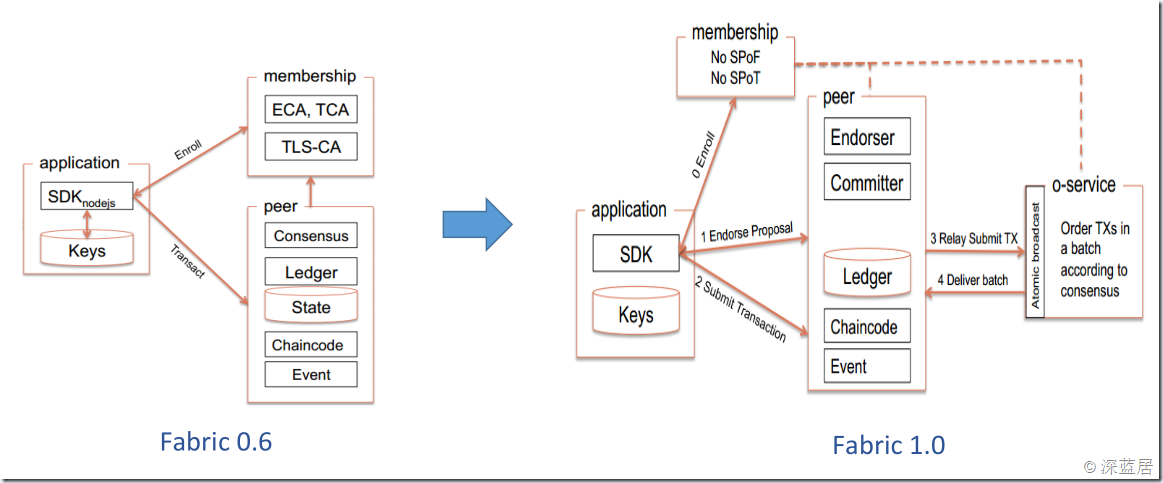
这个图来自IBM微课堂第三讲,我们可以看到原来单一的peer节点在1.0中进行了拆分,分为peer(背书节点和提交节点)和orderer(排序节点)。membership也就是我们在1.0中说的CA节点,其中也涉及到很多密码学和安全相关的知识,我们暂且按住不表,只说SDK、Peer和Orderer之间的关系。
二、账本
要了解Fabric对事务的处理,首先我们需要了解Fabric中的账本,也就是实际存储和查询数据的地方。这是IBM微讲堂中对Fabric账本的示意图:
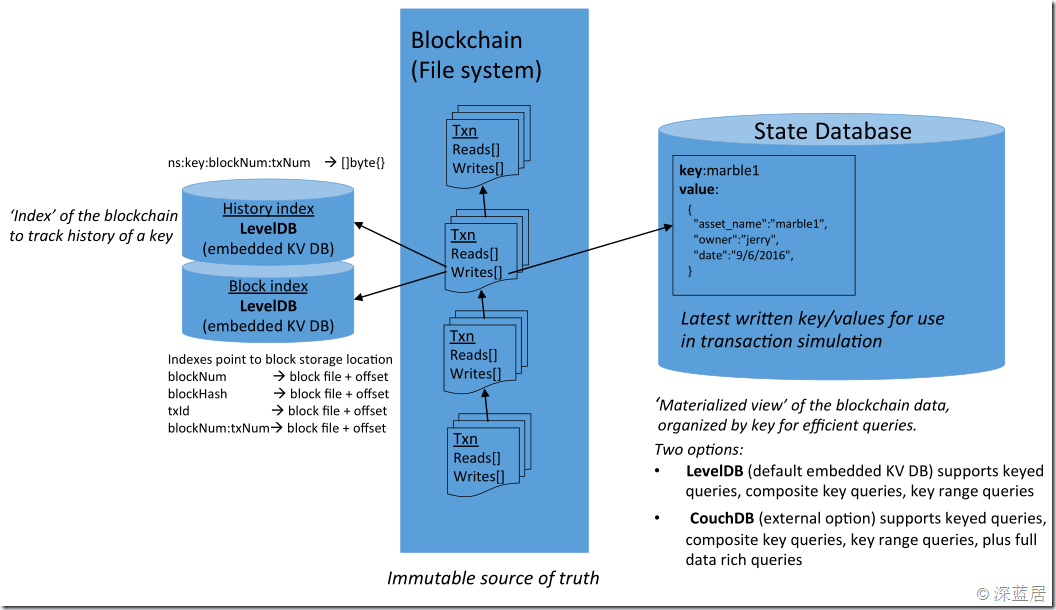
Fabric 1.0中的账本分为3种:
- 区块链数据,这是用文件系统存储在Committer节点上的。区块链中存储了Transaction的读写集。
- 为了检索区块链的方便,所以用LevelDB对其中的Transaction进行了索引。
- ChainCode操作的实际数据存储在State Database中,这是一个Key Value的数据库,默认采用的LevelDB,现在1.0也支持使用CouchDB作为State Database。
三、事务提交过程
了解了Fabric中的账本,接下来我们来了解一下对这些账本的操作涉及到的Transaction。
我们仍然以Example02为例,具体准备过程可参看我之前的博客:http://www.cnblogs.com/studyzy/p/6973334.html
当执行a向b转账10元,我们在cli中执行的命令为:
peer chaincode invoke -o orderer.example.com: --tls $CORE_PEER_TLS_ENABLED --cafile /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/cacerts/ca.example.com-cert.pem -C mychannel -n devincc -c '{"Args":["invoke","a","b","10"]}'
当CLI中运行该命令时,发生了什么呢?我们来看看IBM微讲堂中PPT关于事务生命周期和相关账本的示例图:
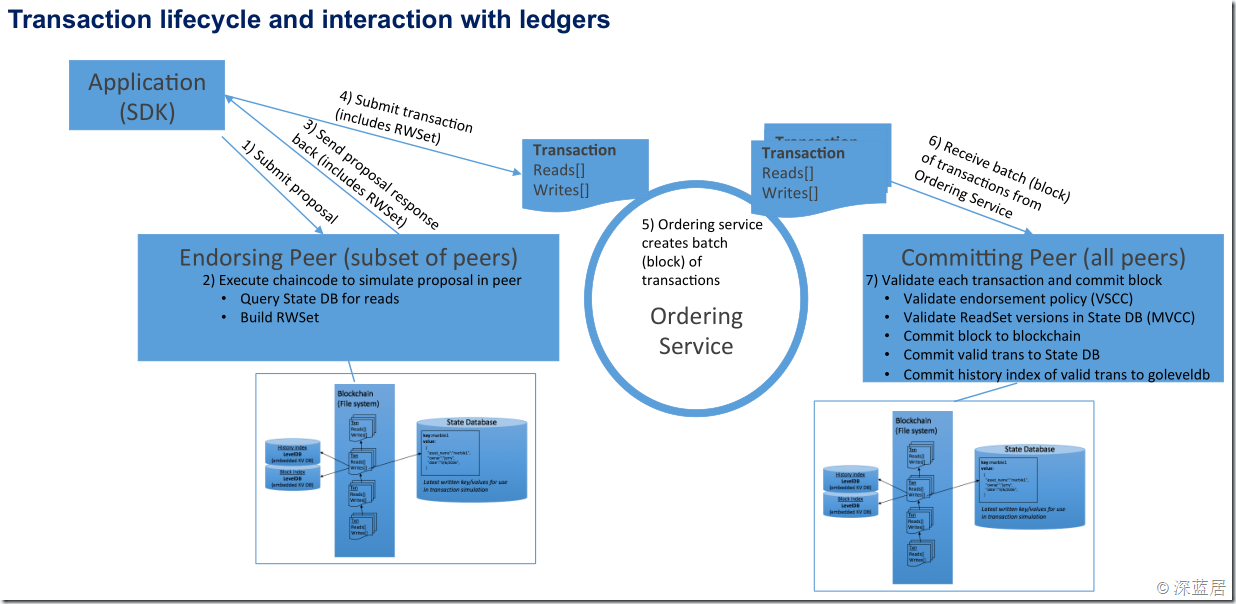
其中peer chaincode invoke表明这是一个Transaction调用。-c '{"Args":["invoke","a","b","10"]}'中的”invoke”说明调用的是example02.go中的invoke函数,具体函数我们可以看看到底实现了什么功能:
// Transaction makes payment of X units from A to B
func (t *SimpleChaincode) invoke(stub shim.ChaincodeStubInterface, args []string) pb.Response {
var A, B string // Entities
var Aval, Bval int // Asset holdings
var X int // Transaction value
var err error
if len(args) != {
return shim.Error("Incorrect number of arguments. Expecting 3")
}
A = args[]
B = args[]
// Get the state from the ledger
// TODO: will be nice to have a GetAllState call to ledger
Avalbytes, err := stub.GetState(A)
if err != nil {
return shim.Error("Failed to get state")
}
if Avalbytes == nil {
return shim.Error("Entity not found")
}
Aval, _ = strconv.Atoi(string(Avalbytes))
Bvalbytes, err := stub.GetState(B)
if err != nil {
return shim.Error("Failed to get state")
}
if Bvalbytes == nil {
return shim.Error("Entity not found")
}
Bval, _ = strconv.Atoi(string(Bvalbytes))
// Perform the execution
X, err = strconv.Atoi(args[])
if err != nil {
return shim.Error("Invalid transaction amount, expecting a integer value")
}
Aval = Aval - X
Bval = Bval + X
fmt.Printf("Aval = %d, Bval = %d\n", Aval, Bval)
// Write the state back to the ledger
err = stub.PutState(A, []byte(strconv.Itoa(Aval)))
if err != nil {
return shim.Error(err.Error())
}
err = stub.PutState(B, []byte(strconv.Itoa(Bval)))
if err != nil {
return shim.Error(err.Error())
}
return shim.Success(nil)
}
其中主要的4个关于StateDatabase调用是:
Avalbytes, err := stub.GetState(A)
Bvalbytes, err := stub.GetState(B)
err = stub.PutState(A, []byte(strconv.Itoa(Aval)))
err = stub.PutState(B, []byte(strconv.Itoa(Bval)))
1.客户端SDK把'{"Args":["invoke","a","b","10"]}'这些参数发送到endorser peer节点,
2.endorser peer会与ChainCode的docker实例通信,并为其提供模拟的State Database的读写集,也就是说ChainCode会执行完逻辑,但是并不会在stub.PutState的时候写数据库。
3.endorser把这些读写集连同签名返回给Client SDK。
4.SDK再把读写集发送给Orderer节点,Orderer节点是进行共识的排序节点,在测试的情况下,只启动一个orderer节点,没有容错。在生产环境,要进行Crash容错,需要启用Zookeeper和Kafka。在1.0中移除了拜占庭容错,没有0.6的PBFT,也没有传说中的SBFT,不得不说是一个遗憾。
5.Orderer节点只是负责排序和打包工作,处理的结果是一个Batch的Transactions,也就是一个Block,这个Block的产生有两种情况,一种情况是Transaction很多,Block的大小达到了设定的大小,而另一种情况是Transaction很少,没有达到设定的大小,那么Orderer就会等,等到大小足够大或者超时时间。这些设置是在configtx.yaml中设定的。
6.打包好的一堆Transactions会发送给Committer Peer提交节点,
7.提交节点收到Orderer节点的数据后,会先进行VSCC校验,检查Block的数据是否正确。接下来是对每个Transaction的验证,主要是验证Transaction中的读写数据集是否与State Database的数据版本一致。验证完Block中的所有Transactions后,提交节点会把吧Block写入区块链。然后把所有验证通过的Transaction的读写集中的写的部分写入State Database。另外对于区块链,本身是文件系统,不是数据库,所有也会有把区块中的数据在LevelDB中建立索引。
四、查询
如果我们只是通过ChainCode查询数据,而存在写入数据,那么会有什么区别呢?在CLI中peer命令提供了query子命令,比如Example02中,查询a账户的余额是:
peer chaincode query -C mychannel -n devincc -c '{"Args":["query","a"]}'
这样系统会调用ChainCode中的invoke函数,但是传入的function name是query。也就是会执行如下代码:
} else if function == "query" {
// the old "Query" is now implemtned in invoke
return t.query(stub, args)
}
// query callback representing the query of a chaincode
func (t *SimpleChaincode) query(stub shim.ChaincodeStubInterface, args []string) pb.Response {
var A string // Entities
var err error
if len(args) != {
return shim.Error("Incorrect number of arguments. Expecting name of the person to query")
}
A = args[]
// Get the state from the ledger
Avalbytes, err := stub.GetState(A)
if err != nil {
jsonResp := "{\"Error\":\"Failed to get state for " + A + "\"}"
return shim.Error(jsonResp)
}
if Avalbytes == nil {
jsonResp := "{\"Error\":\"Nil amount for " + A + "\"}"
return shim.Error(jsonResp)
}
jsonResp := "{\"Name\":\"" + A + "\",\"Amount\":\"" + string(Avalbytes) + "\"}"
fmt.Printf("Query Response:%s\n", jsonResp)
return shim.Success(Avalbytes)
}
我们可以看到,我们只是调用了stub.GetState(A),并没有写操作,那么会像前面说的Transaction一样那么复杂吗?答案是不会。
因为调用调用的是peer query,在代码中,只有invoke的时候才会执行Transaction步骤中的4、5、6、7.
但是如果我们使用peer invoke,那么会怎么样呢?比如如下的命令:
peer chaincode invoke -o orderer.example.com: --tls $CORE_PEER_TLS_ENABLED --cafile /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/cacerts/ca.example.com-cert.pem -C mychannel -n mycc -c '{"Args":["query","a"]}'
那么从代码上来看,虽然我们是一个查询,却会以Transaction的生命周期来处理。
五、小结
通过对这个Transaction过程的分析,我们可以得出以下结论:
- Fabric不支持对同一个数据的并发事务处理,也就是说,如果我们同时运行了a->b 10元,b->a 10元,那么只会第一条Transaction成功,而第二条失败。因为在Committer节点进行读写集版本验证的时候,第二条Transaction会验证失败。这是我完全无法接受的一点!
- Fabric是异步的系统,在Endorser的时候a->b 10元,b->a 10元都会返回给SDK成功,而第二条Transaction在Committer验证失败后不进行State Database的写入,但是并不会通知Client SDK,所以必须使用EventHub通知Client或者Client重新查询才能知道是否写入成功。
- 不管在提交节点对事务的读写数据版本验证是否通过,因为Block已经在Orderer节点生成了,所以Block是被整块写入区块链的,而在State Database不会写入,所以会在Transaction之外的地方标识该Transaction是无效的。
- query没有独立的函数出来,并不是根据只有读集没有写集而判断是query还是Transaction。
HyperLedger Fabric 1.0的Transaction处理流程的更多相关文章
- Hyperledger Fabric 1.0 从零开始(十三)——orderer分布式方案
简述 在搭建HyperLedger Fabric环境的过程中,我们会用到一个configtx.yaml文件(可参考Hyperledger Fabric 1.0 从零开始(八)——Fabric多节点集群 ...
- Hyperledger Fabric 1.0 从零开始(八)——Fabric多节点集群生产部署
6.1.平台特定使用的二进制文件配置 该方案与Hyperledger Fabric 1.0 从零开始(五)--运行测试e2e类似,根据企业需要,可以控制各节点的域名,及联盟链的统一域名.可以指定单独节 ...
- Hyperledger Fabric 1.0 从零开始(一)——吐槽
在HyperLedger/Fabric发布0.6的时候,公司就已经安排了一个团队研究这一块,后来也请IBM的专家组过来培训了一批人,不幸的是,这批人后来全走了,然后没过多久1.0就发布了.自从2017 ...
- Hyperledger Fabric 1.0 从零开始(十二)——fabric-sdk-java应用
Hyperledger Fabric 1.0 从零开始(十)--智能合约 Hyperledger Fabric 1.0 从零开始(十一)--CouchDB 上述两章,最近网上各路大神文章云集,方案多多 ...
- 三、主流区块链技术特点及Hyperledger Fabric V1.0版本特点
一.Hyperledger fabric V1.0 架构 1.逻辑架构: 2.区块链网络 3.运行时架构 二.架构总结 1.架构要点 分拆Peer的功能,将Blockchain的数据维护和共识服务进行 ...
- Hyperledger Fabric 1.0 从零开始(一)
在HyperLedger/Fabric发布0.6的时候,公司就已经安排了一个团队研究这一块,后来也请IBM的专家组过来培训了一批人,不幸的是,这批人后来全走了,然后1.0就发布了.自从2017年7月H ...
- 003-主流区块链技术特点及Hyperledger Fabric V1.0版本特点
一.Hyperledger fabric V1.0 架构 1.逻辑架构: 2.区块链网络 3.运行时架构 二.架构总结 1.架构要点 分拆Peer的功能,将Blockchain的数据维护和共识服务进行 ...
- hyperledger fabric 1.0.5 分布式部署 (六)
如何在相同的peer 节点上创建多个 channel 作者在hyperledger fabric 1.0.5 分布式部署 (五)已经向读者们介绍了一个简单的fabric 的部署流程,那么根据上一篇博客 ...
- hyperledger fabric 1.0.5 分布式部署 (五)
梳理fabric e2e_cli 测试程序的具体步骤 作者在 hyperledger fabric 1.0.5 分布式部署 (一)中给读者们介绍了如何从零开始部署一个测试的 demo 环境,如果细心的 ...
随机推荐
- HTML之元素分类(HTML基础知识)
HTML之元素分类 一.按照块级元素还是行内元素分类 块级元素(block-level)和行内元素(inline-level,也叫作“内联”元素). a.块级元素(独占一行) 块级元素:其最明显的特征 ...
- 中国最强AI超级服务器问世,每秒提供AI计算2000万亿次
https://mp.weixin.qq.com/s/1EVczHp11OJ4GEjeE3z5cA 业内唯一以“AI计算”为核心的人工智能大会昨天发布了一份重要报告. 9月12日,<中国AI计算 ...
- Flutter 布局(三)- FittedBox、AspectRatio、ConstrainedBox详解
本文主要介绍Flutter布局中的FittedBox.AspectRatio.ConstrainedBox,详细介绍了其布局行为以及使用场景,并对源码进行了分析. 1. FittedBox Scale ...
- (后端)mybatis中使用Java8的日期LocalDate、LocalDateTime
原文地址:https://blog.csdn.net/weixin_38553453/article/details/75050632 MyBatis的型处理器是属性“createdtime参数映射为 ...
- DataGridView的单元格如何嵌入多个按钮控件
前段时间我有一个朋友面试公司的时候遇到这个面试题,他也给了份原题给我瞧瞧,并没有什么特别的要点,关于这一类问题,如何在网格上的单元格嵌入多个控件(如按钮.超链接等)问题,我在网上搜索了下这类问题,发现 ...
- Java读取.properties配置文件
一.介绍 Properties文件在Java中主要为配置文件,文件类型为:.properties,格式为文本文件,内容格式为"键=值" 二.读取 这里我采用的是getResourc ...
- python 常见函数的用法
filter(function,ls) 函数包括两个参数,分别是function和list.该函数根据function参数返回的结果是否为真来过滤list参数中的项,最后返回一个新列表. 如: map ...
- 在微信小程序中使用LeanCloud(一)
之前学习了微信小程序前端,使用到LeanCloud线上数据库 [传送门].作为一个前端开发人员,了解后端及数据库是学习工作的需要. LeanCloud直接登录,未注册直接创建账户.它是一款免费的线上数 ...
- Python: datetime 转换
Directive Meaning Example Notes %a Weekday as locale’s abbreviated name. Sun, Mon, …, Sat (en_US); S ...
- 为什么zookeeper集群中节点配置个数是奇数个?
Zookeeper的大部分操作都是通过选举产生的.比如,标记一个写是否成功是要在超过一半节点发送写请求成功时才认为有效.同样,Zookeeper选择领导者节点也是在超过一半节点同意时才有效.最后,Zo ...