Feature Extractor[ResNet]
0. 背景
众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响。而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的现象。
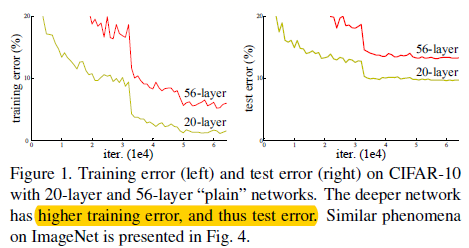
图0.1 不同层数的传统网络下的结果表现
最开始,我们认为随着深度的增加,网络效果不好,那是因为存在着梯度消失和梯度爆炸的原因。不过随着大家的努力,这些问题可以通过归一化初始化(即用特定的初始化算法)和归一化层(Batch Normailzation)来极大的缓解。
可是,我们仍然能够发现随着网络深度的增加,网络反而在某些时刻结果变差了,如图0.1所示。这并不是过拟合造成的,而且随着网络层数再增加,错误反而变得更高了。作者将这一现象称之为“退化”现象。从这个现象中,我们得知,不是所有系统的优化方式都是一样的。
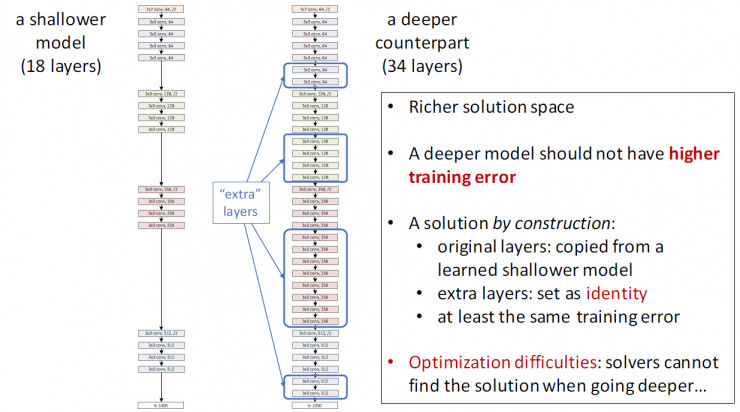
图0.1 "退化"现象
如图0.1所示。我们假设这么一个场景:先训练一个浅层的网络A,然后构建一个深层的网络B,其中网络B比网络A多出的那些层是为了学到恒等映射(identity mapping)(即y=x),然后与A相同的部分就直接用A代替。那么我们可以很自然的认为网络B的错误率应该不会超过网络A。可是我们现在能用到的方法都显示达不到这样的效果。
何恺明大神等人从恒等映射出发,并通过前人的工作中发现,如果将一个问题进行形式转换,那么可能可以得到更容易的解决方法(如SVM中的对偶),也就是对问题进行重新定义或者预先条件约束,那么就能更容易解决这个优化问题。他们发明的残差网络,直接将之前的googlenet和vgg等不到40层的网络直接提升到1000层(虽然大神实验发现101的挺不错),不过后续大家大多还是用着ResNet-101和ResNet-152这两个。
1. ResNet
1.1 残差学习
假设想要拟合的函数为\(H(x)\),我们用堆叠的非线性层网络去拟合另一个函数\(F(x)=H(x)-x\),从而想要学习的函数可以表示成\(H(x)=F(x)+x\)。假如在极端情况下,恒等映射是最优的(即我们学习的函数就是一个恒等函数),那么,将残差逼近到0(\(F(x)=0\))相比于只用堆叠非线性层的网络去拟合恒等映射(\(H(x)=x\))要更容易。这是因为如果直接学习该函数,并不是那么容易(前人的大量实验也证明了这点),可是如果学习的是残差,那么网络可以变得敏感起来,微小的扰动都能让网络产生较大的反映,即优化算法让网络中的权重都趋近于0从而达到恒等映射的目的。
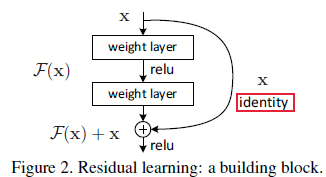
图1.1.1 残差学习:一个构建块
然而现实生活中,恒等映射并不是最优的。如果希望拟合的最优函数更像恒等函数(\(H(x)=x\))而不是0映射(\(F(x)=0\)),那么对于优化算法来说,找到扰动总比学习一个新函数要简单。后续实验也证实了ResNet通常有较小的响应,这表明恒等映射提供了对函数合理的预定义条件。
1.2 快捷连接
1 - feature map和通道维度相同时:
\begin{align}
y=F(x,{W_i})+x \
\end{align}
这里\(x\)和\(y\)分别对应输入和输出,函数\(F(x,{W_i})\)就是需要学的残差映射,如果拿图1.1.1举例,那么\(F=W_2\sigma(W_1x)\),其中\(\sigma\)就是ReLU了。\(F+x\)就是一个快捷连接,并且是逐像素的,所以他们能够计算的前提就是维度相同。而且该方法不需要引入新的参数
2 - 维度不同时:
- 1 - 采用维度相同时候的公式,只不过将不能匹配的部分用0填充;
- 2 - 如下面式子:
\begin{align}
y=F(x,{W_i})+W_sx \
\end{align}
其中\(W_s\)可以看成是\(1*1\)的卷积形式(如64通道需要输出x,连接到128通道上去)。
对于这2种方法,如果上下的feature map维度不同,那么采用stride的方式,如图1.3.1,虚线的部分就是stride=2进行跳跃的
因为恒等映射已经足够处理"退化"问题了,所以这里的\(W_s\)只是为了处理维度不匹配的问题而已(相对维度相同基础上,这里引入的额外参数就是\(W_s\))。
作者并比较了3种不同的升维方式,如图

图1.2.1 不同的模型结果对比
图1.2.1中,其中(A)表示用0扩展的方式来升维,此方法不增加额外的参数; (B) 在需要升维的部分使用\(W_s\)的方式,其他部分直连;(C) 都使用\(W_s\)的方式,且可以看出ABC都比没有快捷连接的效果好,而C比B只好一点点,所以通过\(W_s\)的方式升维的并不是处理"退化"问题的最优选择,所以为了时间复杂度和模型参数量(即尺度),后续都不再用C方法,从而在1.3部分,作者又设计出了瓶颈式构建块。
1.3 网络结构
如图1.1.1所示,ResNet相比传统的网络的区别就是将某一层的输出接着连接到后面的几层,这其中可以跳2层,3层(1层的话就是个线性层,一点效果都没了)。具体的网络结构对比如下。

图1.3.1 3种网络结构:VGG;没有残差快捷连接的网络;34层的ResNet网络
如图1.3.1所示,作者基于第二种模型基础上,增加了残差的快捷连接(ResNet网络中黑色实线表示直接连接,虚线表示需要处理升维的问题),且在每个卷积层中卷积后,激活函数前放置BN层。
为了对模型训练进行加速,作者对图1.1.1的构建块进行了重新设计,如图1.3.2。
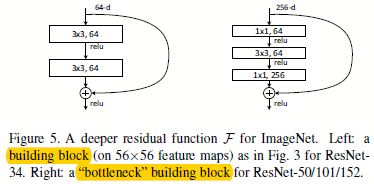
图1.3.2,正常构建块和瓶颈式构建块
其中\(1*1\)的卷积就是负责先降维,然后升维的。可以看出这种方式特别适合使用1.2中,维度相同时候的快捷连接方案。如果将瓶颈式构建块用1.2中维度不同时候的快捷连接方案,那么模型的复杂度和尺度都会翻倍。所以这种设计的构建块更能加速网络训练和减少网络尺度。
通过使用图1.3.2的瓶颈式构建块,作者设计出了不同层下的ResNet网络结构,如图1.3.3所示。
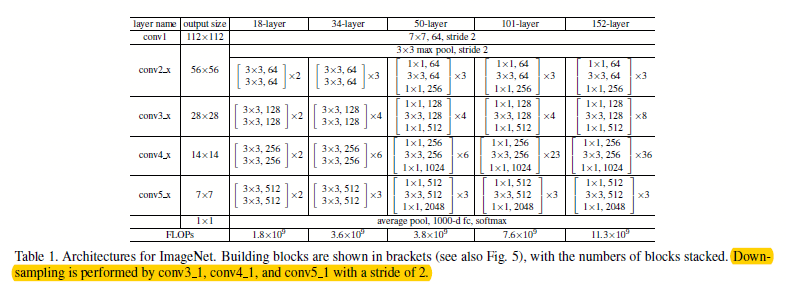
图1.3.3 不同层下的ResNet网络结构
ps:在不同数据集上,训练也略微有点不同,如在cifar-10上训练的时候,0.1开始的学习率太大了,模型不收敛,所以先设成0.01,然后在训练了大约400次迭代的时候,再将学习率设成0.1
ps:顺带贴上不同层下的ResNet的神经元响应
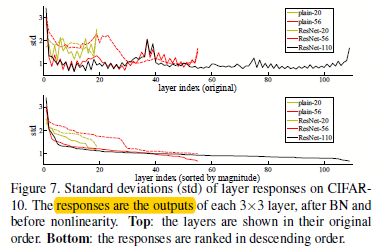
图1.3.4不同层下网络的响应
从图1.3.4中可以看出,越是深的ResNet就有越小的响应,而且越是深的Resnet,单层越是少的去修改信号。
参考文献:
- [本文] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
- [初始化] Y. LeCun, L. Bottou, G. B. Orr, and K.-R.M¨uller. Efficient backprop.In Neural Networks: Tricks of the Trade, pages 9–50. Springer, 1998.
- [初始化] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
- [初始化] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv:1312.6120, 2013.
- [初始化] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015
Feature Extractor[ResNet]的更多相关文章
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- Feature Extractor[DenseNet]
0.背景 随着CNN变得越来越深,人们发现会有梯度消失的现象.这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成 ...
- Feature Extractor[SENet]
0.背景 这个模型是<Deep Learning高质量>群里的牛津大神Weidi Xie在介绍他们的VGG face2时候,看到对应的论文<VGGFace2: A dataset f ...
- Feature Extractor[content]
0. AlexNet 1. VGG VGG网络相对来说,结构简单,通俗易懂,作者通过分析2013年imagenet的比赛的最好模型,并发现感受野还是小的好,然后再加上<network in ne ...
- Feature Extractor[VGG]
0. 背景 Karen Simonyan等人在2014年参加Imagenet挑战赛的时候提出的深度卷积神经网络.作者通过对2013年的ILSVRC中最好的深度神经网络模型(他们最初的对应模型都是ale ...
- Feature Extractor[inception v2 v3]
0 - 背景 在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在<Rethinking the Inception Architecture for Com ...
- Feature Extractor[Inception v4]
0. 背景 随着何凯明等人提出的ResNet v1,google这边坐不住了,他们基于inception v3的基础上,引入了残差结构,提出了inception-resnet-v1和inception ...
- 图像金字塔(pyramid)与 SIFT 图像特征提取(feature extractor)
David Lowe(SIFT 的提出者) 0. 图像金字塔变换(matlab) matlab 对图像金字塔变换接口的支持(impyramid),十分简单好用. 其支持在reduce和expand两种 ...
- Feature Extractor[googlenet v1]
1 - V1 google团队在模型上,更多考虑的是实用性,也就是如何能让强大的深度学习模型能够用在嵌入式或者移动设备上.传统的想增强模型的方法无非就是深度和宽度,而如果简单的增加深度和宽度,那么带来 ...
随机推荐
- saltstack部署配置
共计使用三台虚拟机进行部署实验,系统环境:centos7.3 在master上进行部署配置: 配置主机名 [root@localhost ~]# hostname salt-master [root@ ...
- Android项目实战(五十):微信支付 坑总结
大部分APP必备需求,使用总结 Android接入文章在此:官方文档 文档很简单,Android分为四步: 1.后台配置 2.Android 内 注册appId 3.Android 内 调起支付 4. ...
- DAY5(PYTHON) 字典的增删改查和dict嵌套
一.字典的增删改查 dic={'name':'hui','age':17,'weight':168} dict1={'height':180,'sex':'b','class':3,'age':16} ...
- Microsoft Teams 集成 (协作, 沟通 和 行为)
Microsoft Teams 集成 (协作, 沟通 和 行为) 概述 Microsoft Teams是在Office 365中以chat为中心的工作空间.软件开发团队可以快速获得在一个专门的团队协作 ...
- 前后端分离djangorestframework——解析渲染组件
解析器 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己想要的数据类型的过程,本质就是对请求体中的数据进行解析 Accept是告诉对方我能解析什么样的数据,通常也可以表示我想要什么样的数 ...
- 洗礼灵魂,修炼python(84)-- 知识拾遗篇 —— 网络编程之socket
学习本篇文章的前提,你需要了解网络技术基础,请参阅我的另一个分类的博文:网络互联技术(4)——计算机网络常识.原理剖析 网络通信要素 1.IP地址: 用来标识网络上一台独立的终端(PC或者主机) ip ...
- 自动化测试基础篇--Selenium浏览器操作
摘自https://www.cnblogs.com/sanzangTst/p/7462056.html 学习 Selenium 主要提供的是操作页面上各种元素的方法,但它也提供了操作浏览器本身的方法 ...
- jar包导入导出
java项目: 在classLoader加载jar和class的时候,是分开加载的,一般jar导入分两种: 1.在web-inf下的lib中直接引入 2.在user library上引入 无论以上哪种 ...
- php配置文件php.ini的详细解析(续)
file_uploads = On // ...
- 企业级仓库harbor搭建
1.Harbor是什么? Harbor是Vmvare中国团队开发的开源registry仓库,相比docker官方拥有更丰富的权限权利和完善的架构设计,适用大规模docker集群部署提供仓库服务.在企业 ...