hive复杂类型实战
1、hive 数组简单实践:
CREATE TABLE `emp`(
`name` string,
`emps` array<string>)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://node:9000/user/hive/warehouse/daxin.db/emp' 存入数据,借助insert into ... select : insert into emp select "daxin",array('zhangsan','lisi','wangwu') from ptab; hive> select * from emp;
OK
daxin ["zhangsan","lisi","wangwu"]
mali ["jack","lixisan","fala"]
Time taken: 0.045 seconds, Fetched: 2 row(s)
hive>
>
> select * from emp LATERAL VIEW explode(emps) tmp ;
OK
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.047 seconds, Fetched: 6 row(s)
hive> select * from emp LATERAL VIEW explode(emps) tmp as empeeName ;
OK
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.038 seconds, Fetched: 6 row(s)
hive>
> set hive.cli.print.header=true;
hive> select * from emp LATERAL VIEW explode(emps) tmp as empeeName ;
OK
emp.name emp.emps tmp.empeename
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.046 seconds, Fetched: 6 row(s)
LATERAL VIEW explode(emps) tmp as empeeName 其中as后面的名字指定被拆分数组的字段名字为empeeName;
2、Hive复杂数据类型之Map
创建表语句:
CREATE TABLE `userinfo`(
`name` string,
`info` map<string,string>)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://node:9000/user/hive/warehouse/daxin.db/userinfo' 插入数据:
insert into userinfo select "daxin",map("addr","liaoning") from ptab limit ;
插入数据时候注意,map的key与value之间使用逗号分隔,而不是使用冒号!!!
hive> select * from userinfo;
OK
userinfo.name userinfo.info
daxin {"addr":"liaoning"}
Time taken: 0.04 seconds, Fetched: 1 row(s)
带有where条件查询:
hive> select * from userinfo where info['addr']="liaoning";
OK
userinfo.name userinfo.info
daxin {"addr":"liaoning"}
Time taken: 0.041 seconds, Fetched: 1 row(s)
hive> insert into userinfo select "zhansan",map("addr","beijing","sex","boy","word","coder") from ptab limit 1;
Query ID = liuguangxin_20181102201144_b74fcc0e-1c2d-49e6-9268-bdc97e79ba86
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1541155477807_0005, Tracking URL = http://10.12.141.138:8099/proxy/application_1541155477807_0005/
Kill Command = /Users/liuguangxin/bigdata/hadoop/bin/hadoop job -kill job_1541155477807_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-11-02 20:11:50,234 Stage-1 map = 0%, reduce = 0%
2018-11-02 20:11:55,370 Stage-1 map = 100%, reduce = 0%
2018-11-02 20:11:59,478 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1541155477807_0005
Loading data to table daxin.userinfo
Table daxin.userinfo stats: [numFiles=2, numRows=2, totalSize=60, rawDataSize=58]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 9552 HDFS Write: 110 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0 _c1
Time taken: 15.827 seconds
hive> select * from userinfo where info['addr1']="liaoning"; //当map中不存在key时候不会报错,只会查询不到数据
OK
userinfo.name userinfo.info
Time taken: 0.04 seconds
查看信息个数:
hive > select size(info) as infoCount,* from userinfo ;
OK
infocount userinfo.name userinfo.info
1 daxin {"addr":"liaoning"}
3 zhansan {"addr":"beijing","sex":"boy","word":"coder"}
Time taken: 0.045 seconds, Fetched: 2 row(s)
3、hive复杂数据类型Map
CREATE TABLE `fixuserinfo`(
`name` string,
`info` struct<addr:string,mail:string,sex:string>)
COMMENT 'the count of info is fixed'
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://node:9000/user/hive/warehouse/daxin.db/fixuserinfo'
插入数据:
参考一下:https://blog.csdn.net/xiaolang85/article/details/51330634
创建数据表
CREATE TABLE test(id int,course struct<course:string,score:int>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
数据
1 english,80
2 math,89
3 chinese,95
入库
LOAD DATA LOCAL INPATH '/home/hadoop/test.txt' OVERWRITE INTO TABLE test;
查询
hive> select * from test;
OK
1 {"course":"english","score":80}
2 {"course":"math","score":89}
3 {"course":"chinese","score":95}
Time taken: 0.275 seconds
hive> select course from test;
{"course":"english","score":80}
{"course":"math","score":89}
{"course":"chinese","score":95}
Time taken: 44.968 seconds
select t.course.course from test t;
english
math
chinese
Time taken: 15.827 seconds
hive> select t.course.score from test t;
80
89
95
Time taken: 13.235 seconds
4、数组查询数据的 : LATERAL VIEW explode(emps) tmp as empeeName使用:
对某一个字段进行展开,并将该字段指定一个名字,对于一个 表有多个array类型的表而言,每一条记录展开之后产生的记录数是该行记录的展开数组个数相乘,例如:
CREATE TABLE `empinfo`(
`name` string,
`emps` array<string>,
`sal` array<string>);
表中的数据:
empinfo.name empinfo.emps empinfo.sal
daxin ["zhangsan","lisi","wangwu"] ["99999","88888","999999"]
mali ["11","22","33"] ["6666","7777","8888"]
查询语句:
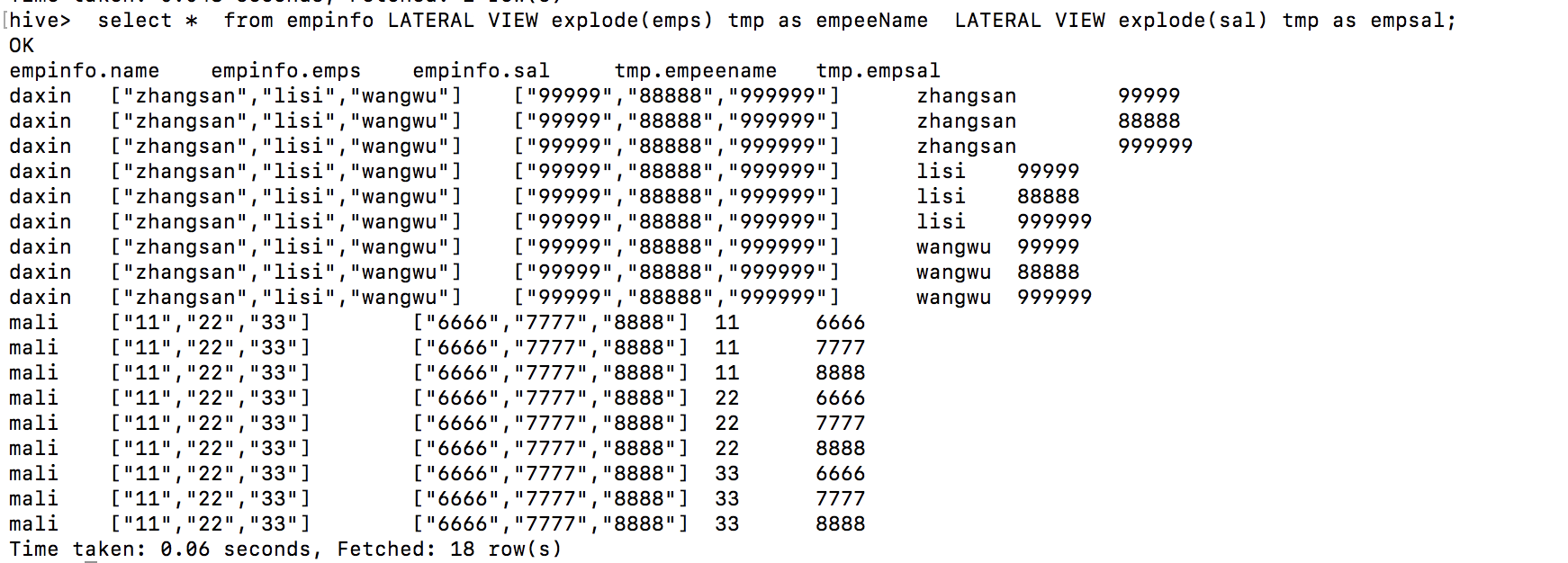
按照emps与sal进行展开,对与第一行数据的每一个数组都是3个元素,因此展开之后变成9条数据!第二行同理,所以共计18行记录!!!
5、Hive在线查看函数文档

参考官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
参考:https://blog.csdn.net/wangtao6791842/article/details/37966035
hive复杂类型实战的更多相关文章
- Scala 深入浅出实战经典 第54讲:Scala中复合类型实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第53讲:Scala中结构类型实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Hive 表类型简述
Hive 表类型简述 表类型一.管理表或内部表Table Type: MANAGED_TABLE example: create table Inner(id int,name string, ...
- hive 复杂类型
hive提供一种复合类型的数据 struct:可以使用"."来存取数据 map:可以使用键值对来存取数据 array:array中存取的数据为相同类型,其中的数据可以通过下表获取数 ...
- 第54讲:Scala中复合类型实战详解
今天学习了scala的复合类型的内容,让我们通过实战来看看代码: trait Compound_Type1trait Compound_Type2class Compound_Type extends ...
- sqoop mysql导入hive 数值类型变成null的问题分析
问题描述:mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null.设置各种行分隔符,列分隔符都没有效果. 问题分析:hive中单独将有问题的那几 ...
- 解决hue/hiveserver2对于hive date类型显示为NULL的问题
用户报在Hue中执行一条sql:select admission_date, discharge_date,birth_date from hm_004_20170309141149.inpatien ...
- Hive调优实战[转]
Hive优化总结 [转自:http://sznmail.iteye.com/blog/1499789] 优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解hadoo ...
- 转载:几种 hive join 类型简介
作为数据分析中经常进行的join 操作,传统DBMS 数据库已经将各种算法优化到了极致,而对于hadoop 使用的mapreduce 所进行的join 操作,去年开始也是有各种不同的算法论文出现,讨论 ...
随机推荐
- Netty 系列五(单元测试).
一.概述和原理 Netty 的单元测试,主要是对业务逻辑的 ChannelHandler 做测试(毕竟对 Bootstrap.EventLoop 这些做测试着实没有多大意义),模拟一次入站数据或者出站 ...
- Android Studio 学习(六)内容提供器
运行时权限 使用ContextCompat.checkSelfPermission(MainActivity.this,Manifest.permission.CALL_PHONE)!=Package ...
- struts配置文件说明
(1)DOCTYPE(文档类型),所有的struts配置文件都需要有正确的doctype. (2)<struts>是根标记元素,在其下使用<package>标签声明不同的包. ...
- 洛谷P2234 [HNOI2002]营业额统计
题目描述 Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger拿出了公司的账本,账本上记录了公司成立以来每天的营业额.分析营业情况是 ...
- 洛谷P2866 [USACO06NOV]糟糕的一天Bad Hair Day(单调栈)
题目描述 Some of Farmer John's N cows (1 ≤ N ≤ 80,000) are having a bad hair day! Since each cow is self ...
- loj#6032. 「雅礼集训 2017 Day2」水箱(并查集 贪心 扫描线)
题意 链接 Sol 神仙题+神仙做法%%%%%%%% 我再来复述一遍.. 首先按照\(y\)坐标排序,然后维护一个扫描线从低处往高处考虑. 一个连通块的内状态使用两个变量即可维护\(ans\)表示联通 ...
- ThinkPHP框架知识
php框架 一.真实项目开发步骤: 多人同时开发项目,协作开发项目.分工合理.效率有提高(代码风格不一样.分工不好) 测试阶段 上线运行 对项目进行维护.修改.升级(单个人维护项目,十分困难,代码风格 ...
- phpcms调用指定文章内容模型的ID
一.使用GET调用Phpcms V9指定id页面数据方法 {pc:get sql="SELECT * FROM cmsyou_news WHERE id='55'" cache=& ...
- iOS------自动查找项目中不用的图片资源
注意:删除的时候要谨慎!别什么图都删了,看看对项目有没有作用.这个插件有时也会有一定的误差. 具体操作步骤: 1.去github上下载LSUnusedResources(下载地址:https://gi ...
- slice()和subString()
substring() 方法用于提取字符串中介于两个指定下标之间的字符.slice()返回一个子片段,对原先的string没有影响,与subString的区别是,还可以用负数当参数,相当于是lengt ...