Kafka02--Kafka生产者简要原理
前言
在Kafka01--Kafka生产者使用方式中对KafkaProducer的基本使用方式进行了了解。以上只是使用方面,一个好的开元框架必定是易于开发者使用的,但是对生产者的基本逻辑流程和数据流转并没有什么概念。
KafkaProducer原理分析
生产者客户端的基本架构图:
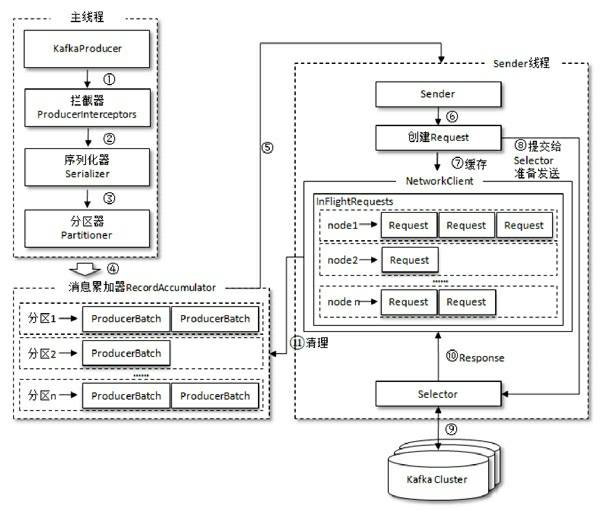
由上图可以看出:KafkaProducer有两个基本线程:
- 主线程:负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器RecoderAccumulator中(这里可以看出拦截器确实在序列化和分区之前执行);
- 消息收集器RecoderAccumulator为每个分区都维护了一个 Deque<ProducerBatch> 类型的双端队列。
- ProducerBatch 可以暂时理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低网络影响;
- 由于生产者客户端使用 java.io.ByteBuffer 在发送消息之前进行消息保存,并维护了一个 BufferPool 实现 ByteBuffer 的复用;该缓存池只针对特定大小( batch.size 指定)的 ByteBuffer进行管理,对于消息过大的缓存,不能做到重复利用。
- 每次追加一条ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取一个ProducerBatch,判断当前消息的大小是否可以写入该批次中。若可以写入则写入;若不可以写入,则新建一个ProducerBatch,判断该消息大小是否超过客户端参数配置 batch.size 的值,不超过,则以 batch.size建立新的ProducerBatch,这样方便进行缓存重复利用;若超过,则以计算的消息大小建立对应的 ProducerBatch ,缺点就是该内存不能被复用了。
- Sender线程:(先简单了解,有个大概,后续说明)
- 该线程从消息收集器获取缓存的消息,将其处理为 <Node, List<ProducerBatch> 的形式, Node 表示集群的broker节点。
- 进一步将<Node, List<ProducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。
- 在发送之前,Sender线程将消息以 Map<NodeId, Deque<Request>> 的形式保存到 InFlightRequests 中进行缓存,可以通过其获取 leastLoadedNode ,即当前Node中负载压力最小的一个,以实现消息的尽快发出。
Kafka集群的元数据
什么是元数据?怎么获取?
卡夫卡集群中的元数据记录了,集群中有哪些主题,每个主题下有哪些分区,分区的leader副本和follower副本各分部在哪些节点上,哪些副本在AR,ISR集合中,控制节点是哪一个等信息。
一个最简单的发送消息的示例代码中,只填写了broker的地址以及topic信息,就能实现发送,其中就包含了客户端从服务端获取元数据信息的过程。
举例来说,客户端首先要获取该topic下的parition数量,计算得出目标分区,然后获取leader副本所在broker节点,才能建立连接实现数据发送。
当客户端没有元数据信息或者元数据信息过时( metadata.max.age.ms(默认5min) ),会通过上述的 leastLoadedNode,获取服务端元数据信息。
Kafka02--Kafka生产者简要原理的更多相关文章
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- kafka知识体系-kafka设计和原理分析
kafka设计和原理分析 kafka在1.0版本以前,官方主要定义为分布式多分区多副本的消息队列,而1.0后定义为分布式流处理平台,就是说处理传递消息外,kafka还能进行流式计算,类似Strom和S ...
- kafka生产者和消费者流程
前言 根据源码分析kafka java客户端的生产者和消费者的流程. 基于zookeeper的旧消费者 kafka消费者从消费数据到关闭经历的流程. 由于3个核心线程 基于zookeeper的连接器监 ...
- JAVA封装消息中间件调用一(kafka生产者篇)
这段时间因为工作关系一直在忙于消息中间件的发开,现在趁着项目收尾阶段分享下对kafka的一些使用心得. kafka的原理我这里就不做介绍了,可参考http://orchome.com/kafka/in ...
- 《转载》仅需3分钟,你就能明白Kafka的工作原理
仅需3分钟,你就能明白Kafka的工作原理 周末无聊刷着手机,某宝网 App 突然蹦出来一条消息“为了回馈老客户,女朋友买一送一,活动仅限今天!”. 买一送一还有这种好事,那我可不能错过!忍不住立马点 ...
- 了解Kafka生产者
了解Kafka生产者 之前对kafka的整体架构有浅显的了解,这次正好有时间,准备深入了解一下kafka,首先先从数据的生产者开始吧. 生产者的整体架构 可以看到整个生产者进程主要由两个线程进 ...
- Kafka内部实现原理
Kafka是什么 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 1)Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开 ...
- 【转】 详解Kafka生产者Producer配置
粘贴一下这个配置,与我自己的程序做对比,看看能不能完善我的异步带代码: ----------------------------------------- 详解Kafka生产者Produce ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
随机推荐
- Linux性能优化之内存性能调优
一.根据性能指标找工具 二.根据工具查性能 三.内存优化策略 常见的优化思路有这么几种: 1)最好禁止 Swap.如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的 ...
- SpringBoot是如何做到自动装配的
背景 众所周知,如下即可启动一个最简单的Spring应用.查看@SpringBootApplication注解的源码,发现这个注解上有一个重要的注解@EnableAutoConfiguration,而 ...
- Windows原理深入学习系列-强制完整性控制
欢迎关注微信公众号:[信安成长计划] 0x00 目录 0x01 介绍 0x02 完整性等级 0x03 文件读取测试 0x04 进程注入测试 0x05 原理分析 Win10_x64_20H2 0x06 ...
- wireshark-1
wireshark-1题目来源: 广西首届网络安全选拔赛题目描述:黑客通过wireshark抓到管理员登陆网站的一段流量包(管理员的密码即是答案). flag提交形式为flag{XXXX}附件解压后, ...
- C#中default 、base 、this关键字用法简介
C#中default关键字用法简介 default 关键字可在switch语句或泛型代码中使用.switch语句:指定默认标签.泛型代码:指定类型参数的默认值.对于引用类型为空,对于值类型为零swi ...
- Oracle之SQL限定查询
WHERE限定条件 /*语法结构:SELECT * | 列名1[,列名2...] | 表达式FROM 表名 WHERE 限定条件; */ --查询职位为CLERK的员工信息 SELECT * FROM ...
- Hadoop权威指南 - 学习笔记
初识Hadoop.关于MapReduce Hadoop宏观介绍 相对于其他系统的优势 关系型数据库管理系统 为什么不能用配有大量硬盘的数据库进行大规模分析?为什么需要Hadoop? 因为计算机硬盘的发 ...
- oracle 11g rac修改监听端口(远程监听和本地监听)
转至:https://www.cnblogs.com/yj411511/p/12459533.html 目录 1.修改远程监听端口 1.1 查看远程监听状态 1.2 修改SCAN listener端口 ...
- ShapeNet: An Information-Rich 3D Model Repository 阅读笔记
ShapeNet: An Information-Rich 3D Model Repository 注:本论文只是讲述数据库建立方法 摘要 ShapeNet是一个有丰富注释的大型形状存储库,由对象的3 ...
- Python:wordcloud
wordcloud官方文档 1.简介 wordcloud是优秀的词云展示的第三方库 2.导入模块 import wordcloud 3.wordcloud对象初始化 以下参数值均为官方文档给出的默认值 ...