Kafka02--Kafka生产者简要原理
前言
在Kafka01--Kafka生产者使用方式中对KafkaProducer的基本使用方式进行了了解。以上只是使用方面,一个好的开元框架必定是易于开发者使用的,但是对生产者的基本逻辑流程和数据流转并没有什么概念。
KafkaProducer原理分析
生产者客户端的基本架构图:
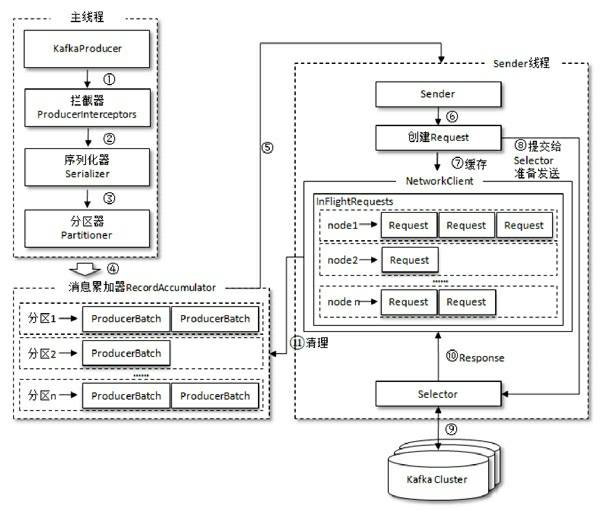
由上图可以看出:KafkaProducer有两个基本线程:
- 主线程:负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器RecoderAccumulator中(这里可以看出拦截器确实在序列化和分区之前执行);
- 消息收集器RecoderAccumulator为每个分区都维护了一个 Deque<ProducerBatch> 类型的双端队列。
- ProducerBatch 可以暂时理解为是 ProducerRecord 的集合,批量发送有利于提升吞吐量,降低网络影响;
- 由于生产者客户端使用 java.io.ByteBuffer 在发送消息之前进行消息保存,并维护了一个 BufferPool 实现 ByteBuffer 的复用;该缓存池只针对特定大小( batch.size 指定)的 ByteBuffer进行管理,对于消息过大的缓存,不能做到重复利用。
- 每次追加一条ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取一个ProducerBatch,判断当前消息的大小是否可以写入该批次中。若可以写入则写入;若不可以写入,则新建一个ProducerBatch,判断该消息大小是否超过客户端参数配置 batch.size 的值,不超过,则以 batch.size建立新的ProducerBatch,这样方便进行缓存重复利用;若超过,则以计算的消息大小建立对应的 ProducerBatch ,缺点就是该内存不能被复用了。
- Sender线程:(先简单了解,有个大概,后续说明)
- 该线程从消息收集器获取缓存的消息,将其处理为 <Node, List<ProducerBatch> 的形式, Node 表示集群的broker节点。
- 进一步将<Node, List<ProducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。
- 在发送之前,Sender线程将消息以 Map<NodeId, Deque<Request>> 的形式保存到 InFlightRequests 中进行缓存,可以通过其获取 leastLoadedNode ,即当前Node中负载压力最小的一个,以实现消息的尽快发出。
Kafka集群的元数据
什么是元数据?怎么获取?
卡夫卡集群中的元数据记录了,集群中有哪些主题,每个主题下有哪些分区,分区的leader副本和follower副本各分部在哪些节点上,哪些副本在AR,ISR集合中,控制节点是哪一个等信息。
一个最简单的发送消息的示例代码中,只填写了broker的地址以及topic信息,就能实现发送,其中就包含了客户端从服务端获取元数据信息的过程。
举例来说,客户端首先要获取该topic下的parition数量,计算得出目标分区,然后获取leader副本所在broker节点,才能建立连接实现数据发送。
当客户端没有元数据信息或者元数据信息过时( metadata.max.age.ms(默认5min) ),会通过上述的 leastLoadedNode,获取服务端元数据信息。
Kafka02--Kafka生产者简要原理的更多相关文章
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- kafka知识体系-kafka设计和原理分析
kafka设计和原理分析 kafka在1.0版本以前,官方主要定义为分布式多分区多副本的消息队列,而1.0后定义为分布式流处理平台,就是说处理传递消息外,kafka还能进行流式计算,类似Strom和S ...
- kafka生产者和消费者流程
前言 根据源码分析kafka java客户端的生产者和消费者的流程. 基于zookeeper的旧消费者 kafka消费者从消费数据到关闭经历的流程. 由于3个核心线程 基于zookeeper的连接器监 ...
- JAVA封装消息中间件调用一(kafka生产者篇)
这段时间因为工作关系一直在忙于消息中间件的发开,现在趁着项目收尾阶段分享下对kafka的一些使用心得. kafka的原理我这里就不做介绍了,可参考http://orchome.com/kafka/in ...
- 《转载》仅需3分钟,你就能明白Kafka的工作原理
仅需3分钟,你就能明白Kafka的工作原理 周末无聊刷着手机,某宝网 App 突然蹦出来一条消息“为了回馈老客户,女朋友买一送一,活动仅限今天!”. 买一送一还有这种好事,那我可不能错过!忍不住立马点 ...
- 了解Kafka生产者
了解Kafka生产者 之前对kafka的整体架构有浅显的了解,这次正好有时间,准备深入了解一下kafka,首先先从数据的生产者开始吧. 生产者的整体架构 可以看到整个生产者进程主要由两个线程进 ...
- Kafka内部实现原理
Kafka是什么 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 1)Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开 ...
- 【转】 详解Kafka生产者Producer配置
粘贴一下这个配置,与我自己的程序做对比,看看能不能完善我的异步带代码: ----------------------------------------- 详解Kafka生产者Produce ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
随机推荐
- [WPF] 使用 Effect 玩玩阴影、内阴影、 长阴影
最近在学习怎么用 Shazzam Shader Editor 编写自定义的 Effect,并试着去实现阴影.内阴影和长阴影的效果.结果我第一步就放弃了,因为阴影用到的高斯模糊算法对我来说太太太太太太太 ...
- SaaS平台是什么,为什么字节、腾讯等大厂都在抢相关人才
SaaS平台很多人可能没听说是什么,但是从事TO B公司的员工来说,SaaS平台应该都有所耳闻.从2016年开始,腾讯开始发力TO B算起,到处在挖TO B公司的骨干人才,而熟悉SaaS平台的人才竞 ...
- Hadoop - HA学习笔记
Hadoop HA概述 工作要点 通过双NameNode消除单点故障 元数据管理方式需要改变:内存中各自保存一份元数据:Edits 日志只有 Active 状态的NameNode节点可以做写操作:两个 ...
- 用MySQL碰到的一些“坑”
本篇文章持续更新. 这里说坑,也不算坑,只是对我一个经常用SQL Server的来说有点不习惯而已. 一.GroupBy 的不同 create table Customer ( CustomerNum ...
- VSCode好用的插件
一.Chinese: 汉化 二.Live Server: Live Serve这是一个为静态和动态页面启动具有实时重新加载功能的开发本地服务器. 安装好后,在html页面右键:Open With Li ...
- 用RecyclerView实现水平滚动和网格视图
建立RecyclerViewActivity.java文件 1 public class RecyclerViewActivity extends AppCompatActivity { 2 priv ...
- 通过IP访问公司公共资源库(共享文件)
今天,公司发通知说公司内部共享资源库已搭建完成,给了一个IP地址说可以访问了,那么如何去查看其他电脑的共享文件,下面以Windows7为例进行说明: 1:点击开始-运行(如图),或者快捷键(Win+R ...
- 设置vim永久显示编号
永久显示行号,需要我们设置配置文件,两种配置方式: 1. /etc/vimrc 是系统范围的初始化配置 2. -/.vimrc 个人的vim初始化配置 编辑配置文件,以个人为例: vi ...
- C#控制台输入密码星号显示
在Program类中的Main方法里: 1 public class Program 2 { 3 static void Main(string[] args) 4 { 5 Console.Write ...
- 快速整透Redis中的压缩列表到底是个啥
压缩列表简介 压缩列表(ziplist)是由一个连续内存组成的顺序型数据结构.一个压缩列表可以包含任意多个节点,每个节点上可以保存一个字节数组或整数值.它是Redis为了节省内存空间而开发的. 压缩列 ...