IDEA快速生成数据库表的实体类
IDEA连接数据库
IDEA右边侧栏有个DataSource,可以通过这个来连接数据库,我们先成功连接数据库
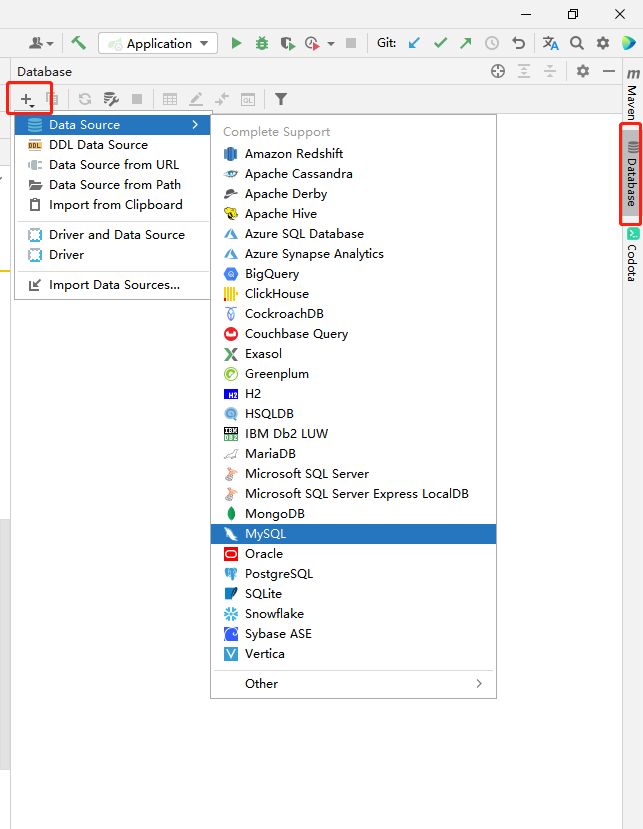
点击进入后填写数据库进行连接,注意记得一定要去Test Connection 确保正常连接
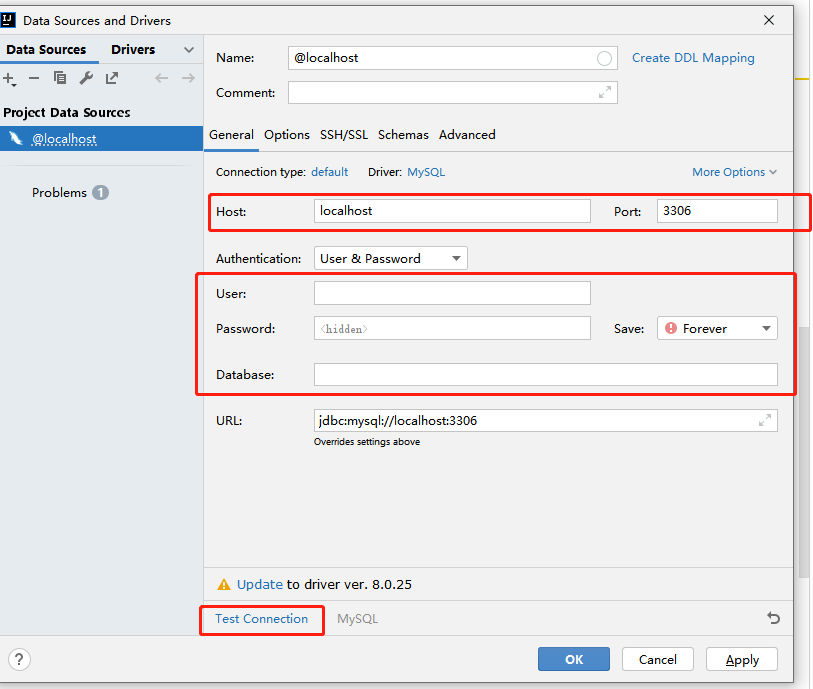
注意,这里可能遇到没有mysql连接的jar包
解决方案:1找一个jar包放进来
2从maven仓库引进来
2的截图
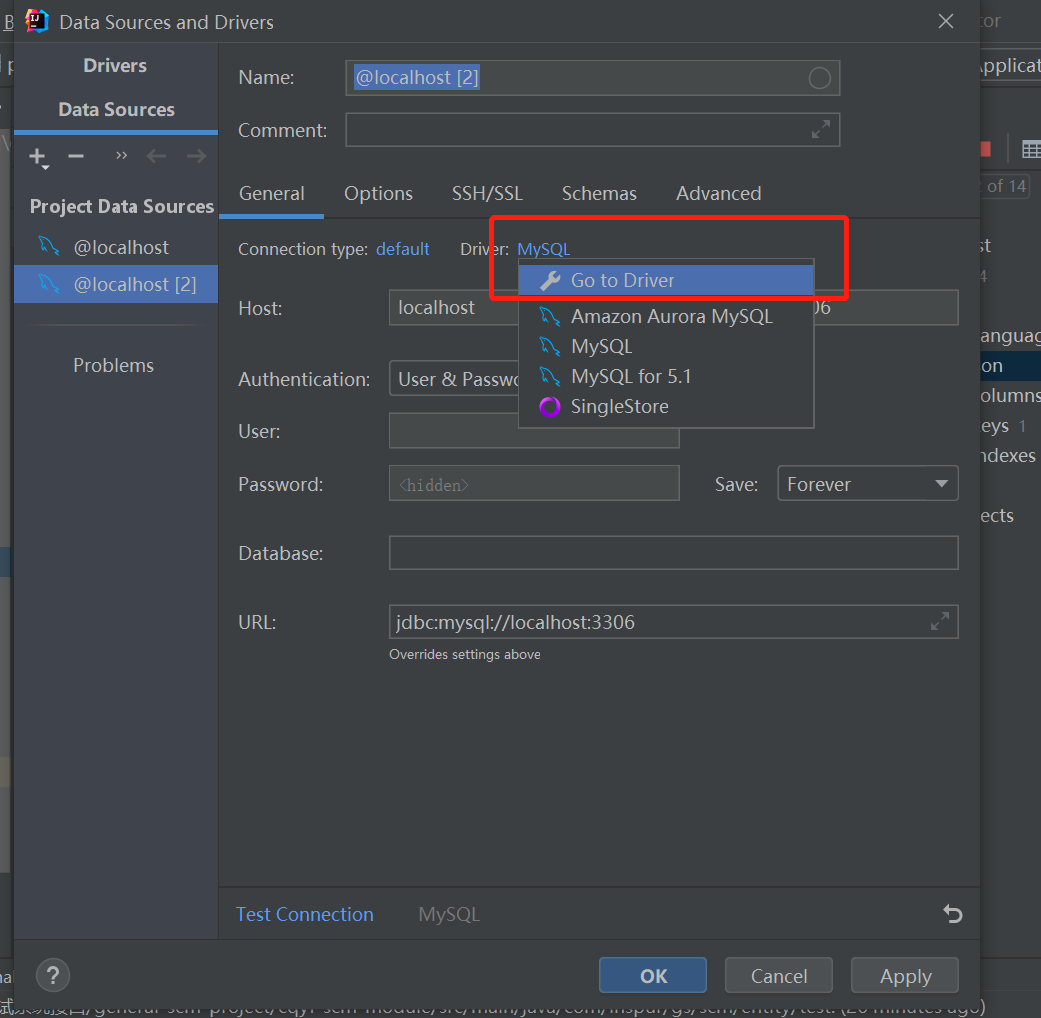
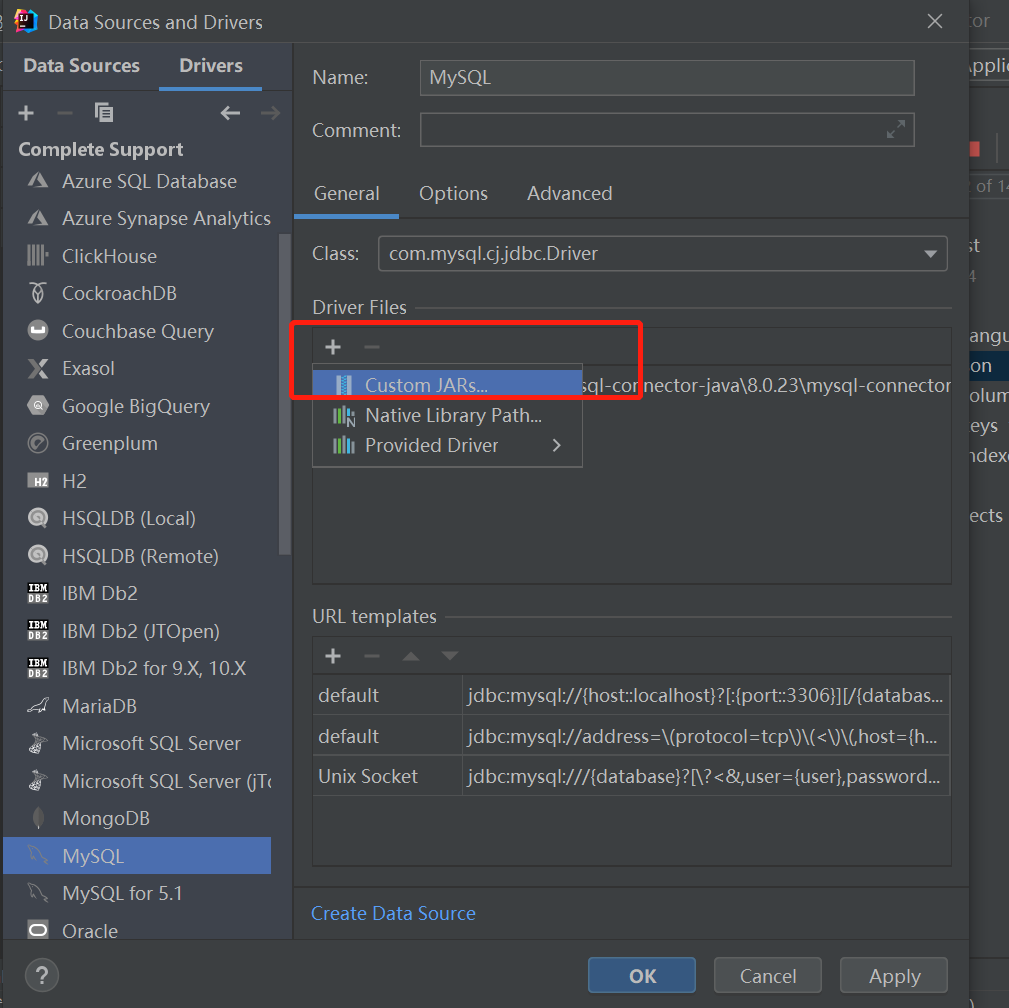
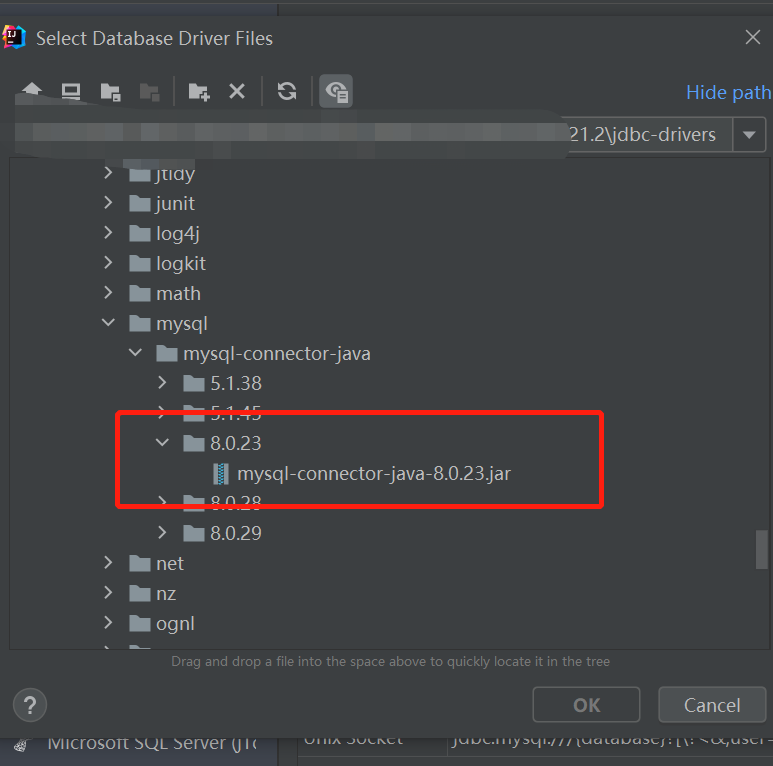
选择表生成实体
选择一个表右键,选择如下选项进行生成,会弹出一个选择存放实体类路径的窗口,选择放在合适的目录下就好
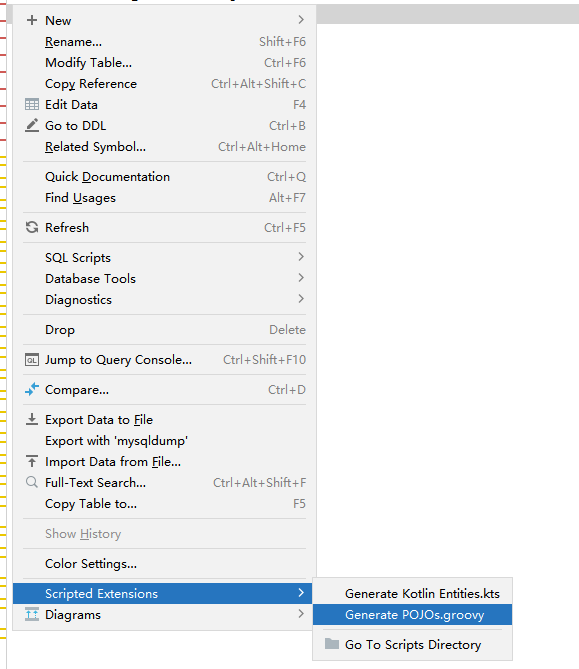
自定义配置
如果发现数据库的某些字段没有转换成你需要的字段,如varbinary会自动转换成String,但你想让其转换为byte或其他类型,可以更改groovy脚本,在project中的如下位置找到groovy脚本
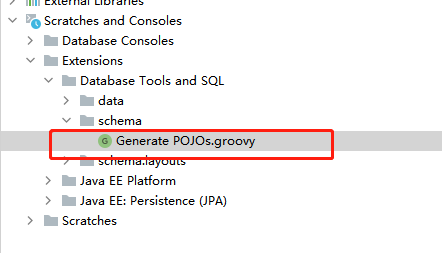
可以在文件的这一部分更改映射关系

如果想在生成的字段上加一些注释,可以在groovy脚本中找到generate函数,然后在其输出这里进行更改,如我在这里增加了
@TableField注解
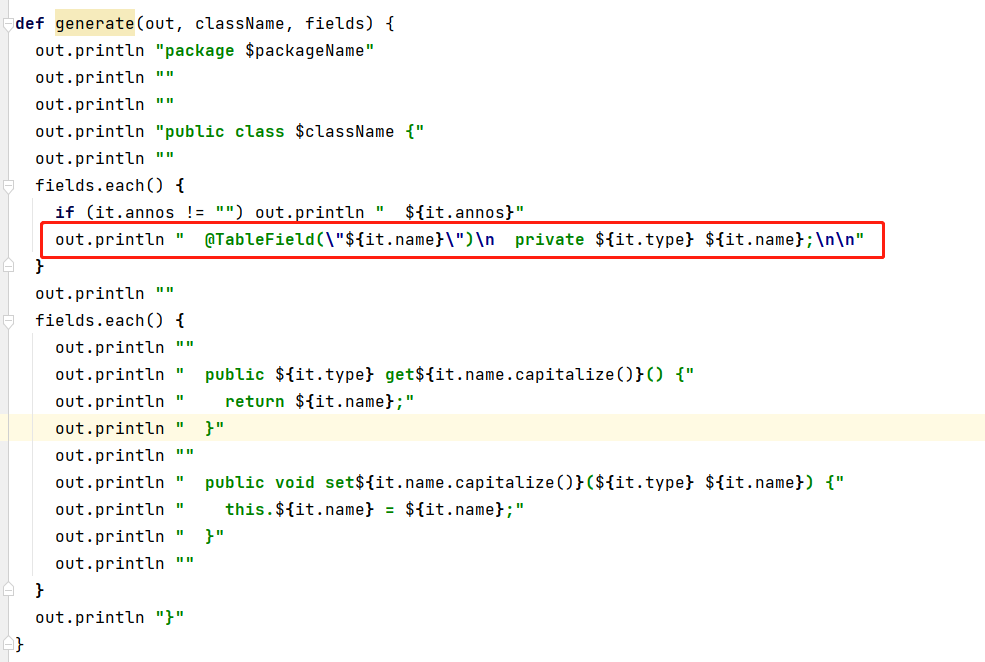
比较完善的一个groovy脚本,可以直接粘贴内容替换原来的groovy脚本
import com.intellij.database.model.DasTable
import com.intellij.database.model.ObjectKind
import com.intellij.database.util.Case
import com.intellij.database.util.DasUtil
import java.io.*
import java.text.SimpleDateFormat
//自定义包名
packageName = ""
typeMapping = [
//类型映射
(~/(?i)tinyint|smallint|mediumint/) : "Integer",
(~/(?i)int/) : "Long",
(~/(?i)bool|bit/) : "Boolean",
(~/(?i)float|double|decimal|real/) : "BigDecimal",
(~/(?i)datetime|timestamp|date|time/) : "Date",
(~/(?i)blob|binary|bfile|clob|raw|image/): "InputStream",
(~/(?i)/) : "String"
]
FILES.chooseDirectoryAndSave("Choose directory", "Choose where to store generated files") { dir ->
SELECTION.filter { it instanceof DasTable && it.getKind() == ObjectKind.TABLE }.each { generate(it, dir) }
}
def generate(table, dir) {
def className = javaName(table.getName(), true)
def fields = calcFields(table)
packageName = getPackageName(dir)
PrintWriter printWriter = new PrintWriter(new OutputStreamWriter(new FileOutputStream(new File(dir, className + ".java")), "UTF-8"))
printWriter.withPrintWriter {out -> generate(out, className, fields,table)}
}
def getPackageName(dir) {
return dir.toString().replaceAll("\\\\", ".").replaceAll("/", ".").replaceAll("^.*src(\\.main\\.java\\.)?", "") + ";"
}
def generate(out, className, fields,table) {
out.println "package $packageName"
out.println ""
out.println "import javax.persistence.Column;"
out.println "import javax.persistence.Entity;"
out.println "import javax.persistence.Table;"
out.println "import java.io.Serializable;"
out.println "import lombok.Data;"
out.println("import javax.persistence.Id;")
Set types = new HashSet()
fields.each() {
types.add(it.type)
}
if (types.contains("Date")) {
out.println "import java.util.Date;"
}
if (types.contains("InputStream")) {
out.println "import java.io.InputStream;"
}
out.println ""
out.println "/**\n" +
" * @Title "+ table.getName()+" \n" +
" * @Description \n" +
" * @author liyuan \n" +
" * @Date "+ new SimpleDateFormat("yyyy-MM-dd").format(new Date()) + " \n" +
" */"
out.println ""
out.println "@Entity"
out.println "@Table ( name =\""+table.getName() +"\" )"
out.println "@Data"
out.println "public class $className implements Serializable {"
out.println ""
out.println genSerialID()
fields.each() {
out.println ""
//添加字段注释
if (isNotEmpty(it.commoent)) {
out.println "\t/**"
out.println "\t * ${it.commoent.toString()}"
out.println "\t */"
}
//为字段添加注解
if (it.annos != "") out.println " ${it.annos.replace("[@Id]", "")}"
//显示变量
out.println "\tprivate ${it.type} ${it.name};"
}
out.println ""
out.println "}"
}
def calcFields(table) {
DasUtil.getColumns(table).reduce([]) { fields, col ->
def spec = Case.LOWER.apply(col.getDataType().getSpecification())
def typeStr = typeMapping.find { p, t -> p.matcher(spec).find() }.value
def comm =[
colName : col.getName(),
name : javaName(col.getName(), false),
type : typeStr,
commoent: col.getComment(),
annos: "\t@Column(name = \""+col.getName()+"\")"]
if("id".equals(Case.LOWER.apply(col.getName())))
comm.annos +="\n\t@Id"
fields += [comm]
}
}
def javaClassName(str, capitalize) {
def s = com.intellij.psi.codeStyle.NameUtil.splitNameIntoWords(str)
.collect { Case.LOWER.apply(it).capitalize() }
.join("")
.replaceAll(/[^\p{javaJavaIdentifierPart}[_]]/, "_")
s = s[1..s.size() - 1]
capitalize || s.length() == 1? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
def javaName(str, capitalize) {
def s = com.intellij.psi.codeStyle.NameUtil.splitNameIntoWords(str)
.collect { Case.LOWER.apply(it).capitalize() }
.join("")
.replaceAll(/[^\p{javaJavaIdentifierPart}[_]]/, "_")
capitalize || s.length() == 1? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
def isNotEmpty(content) {
return content != null && content.toString().trim().length() > 0
}
static String changeStyle(String str, boolean toCamel){
if(!str || str.size() <= 1)
return str
if(toCamel){
String r = str.toLowerCase().split('_').collect{cc -> Case.LOWER.apply(cc).capitalize()}.join('')
return r[0].toLowerCase() + r[1..-1]
}else{
str = str[0].toLowerCase() + str[1..-1]
return str.collect{cc -> ((char)cc).isUpperCase() ? '_' + cc.toLowerCase() : cc}.join('')
}
}
static String genSerialID()
{
return "\tprivate static final long serialVersionUID = "+Math.abs(new Random().nextLong())+"L;"
}IDEA快速生成数据库表的实体类的更多相关文章
- idea 从数据库快速生成Spring Data JPA实体类
第一步,调出 Persistence 窗口. File—>Project Structure—>model—> + —>JPA 第二步:打开 Persistence窗口 配置 ...
- sts使用mybatis插件直接生成数据库表的mapper类及配置文件
首先点击help------>Eclipse Marketplace----->在find中搜索mybatis下面图片的第一个 点击installed 还需要一个配置文件generator ...
- 用T4模版生成对应数据库表的实体类
<#@ template debug="false" hostspecific="false" language="C#" #> ...
- NetCore使用使用Scaffold-DbContext命令生成数据库表实体类
一.为了模拟项目,本处创建了一个NetCore的Web项目.打算在Models文件夹下生成数据库表的实体类. 二.在程序包管理控制台,输入“Scaffold-DbContext "Serve ...
- JPA中建立数据库表和实体间映射小结
在JPA中,映射数据库表和实体的时候,需要注意一些细节如下, 实体类要用@Entity的注解: 要用 @Id 来注解一个主键: 如果跟数据库相关联,要用@Table注解相关数据库表: 实体类中字段需要 ...
- hibernate笔记--通过SchemaExport生成数据库表
方法比较简单,项目中只需要两个java类(一个实体类,如User,一个工具类),两个配置文件(hibernate必须的两个配置文件hibernate.cfg.xml,与User.hbm.xml),即可 ...
- 【动软.Net代码生成器】连接MySQL生成C#的POCO实体类(Model)
首先是工具的下载地址: 动软.Net代码生成器 该工具官网自带完整教程: 文档:http://www.maticsoft.com/help/ 例子:http://www.maticsoft.com/h ...
- Hibernate生成数据库表
首先创建实体类 import java.util.Date; public class ProductionEntity { public Integer getId() { return id; } ...
- Mybatis总结之如何自动生成数据库表结构
一般情况下,用Mybatis的时候是先设计表结构再进行实体类以及映射文件编写的,特别是用代码生成器的时候. 但有时候不想用代码生成器,也不想定义表结构,那怎么办? 这个时候就会想到Hibernate, ...
随机推荐
- vant自动上传图片/文件
vant自动上传文件/图片 vant上传图片与elementUI有所不同,没有自动上传功能,所以与后端进行接口对接的时候可以在after-read中将文件进行上传 html页面 <!-- 上传图 ...
- 中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问
截止2022年,中国联通用户规模达到4.6亿,占据了全中国人口的30%,随着5G的推广普及,运营商IT系统普遍面临着海量用户.海量话单.多样化业务.组网模式等一系列变革的冲击. 当前,联通每天处理话单 ...
- Http 前端向后端传递List参数
场景 在日常项目开发中,前端向后端传参时,可能会遇到需要传 List 类型的参数.比如批量删除时将多个 ID 以集合的形式传给后台. 前端传参 此时前端传参有两种方式: 1.多个同名 key key ...
- 【RocketMQ】事务的实现原理
事务的使用 RocketMQ事务的使用场景 单体架构下的事务 在单体系统的开发过程中,假如某个场景下需要对数据库的多张表进行操作,为了保证数据的一致性,一般会使用事务,将所有的操作全部提交或者在出错的 ...
- 浅谈 Raft 分布式一致性协议|图解 Raft
前言 本篇文章将模拟一个KV数据读写服务,从提供单一节点读写服务,到结合分布式一致性协议(Raft)后,逐步扩展为一个分布式的,满足一致性读写需求的读写服务的过程. 其中将配合引入Raft协议的种种概 ...
- CF600E Lomsat gelral (dfs序+莫队)
题面 题解 看到网上写了很多DSU和线段树合并的题解,笔者第一次做也是用的线段树合并,但在原题赛的时候却怕线段树合并调不出来,于是就用了更好想更好调的莫队. 这里笔者就说说莫队怎么做吧. 我们可以通过 ...
- openstack中Cinder组件简解
一,Cinder组件介绍 概念 cinder组件作用: 块存储服务,为运行实例提供稳定的数据块存储服务 块存储服务,提供对 volume 从创建到删除整个生命周期的管理 二,常用操作 1.Volume ...
- Kingbase V8R6集群安装部署案例---脚本在线一键缩容
案例说明: KingbaseES V8R6支持图形化方式在线缩容,但是在一些生产环境,在服务器不支持图形化界面的情况下 ,只能通过脚本命令行的方式执行集群的部署或在线缩容. Tips: Kingb ...
- KingbaseES V8R6C5B041 sys_backup.sh单实例备份案例
数据库版本: test=# select version(); version ---------------------------------------------------------- ...
- KingbaseES 创建只读(read_only)用户
数据库版本: prod=> select version(); version --------------------------------------------------------- ...