StoneDB 子查询优化
StoneDB 子查询优化
摘要:
说明如何优化 exists 的 join 查询优化器的处理
核心函数:
TwoDimensionalJoiner::ChooseJoinAlgorithm
JoinAlgType TwoDimensionalJoiner::ChooseJoinAlgorithm([[maybe_unused]] MultiIndex &mind, Condition &cond) {
JoinAlgType join_alg = JoinAlgType::JTYPE_GENERAL;
if (cond[0].IsType_JoinSimple() && cond[0].op == common::Operator::O_EQ) {
if ((cond.Size() == 1) && !stonedb_sysvar_force_hashjoin)
join_alg = JoinAlgType::JTYPE_MAP; // available types checked inside
else
join_alg = JoinAlgType::JTYPE_HASH;
} else {
if (cond[0].IsType_JoinSimple() &&
(cond[0].op == common::Operator::O_MORE_EQ || cond[0].op == common::Operator::O_MORE ||
cond[0].op == common::Operator::O_LESS_EQ || cond[0].op == common::Operator::O_LESS))
join_alg = JoinAlgType::JTYPE_SORT;
}
return join_alg;
}
选择 join 优化器问题分析:
- 仅判定 join simple 场景,未判断 exists 子句
- cond [0].IsType_JoinSimple () 如果走入了 else 分支,相当于被执行了两次
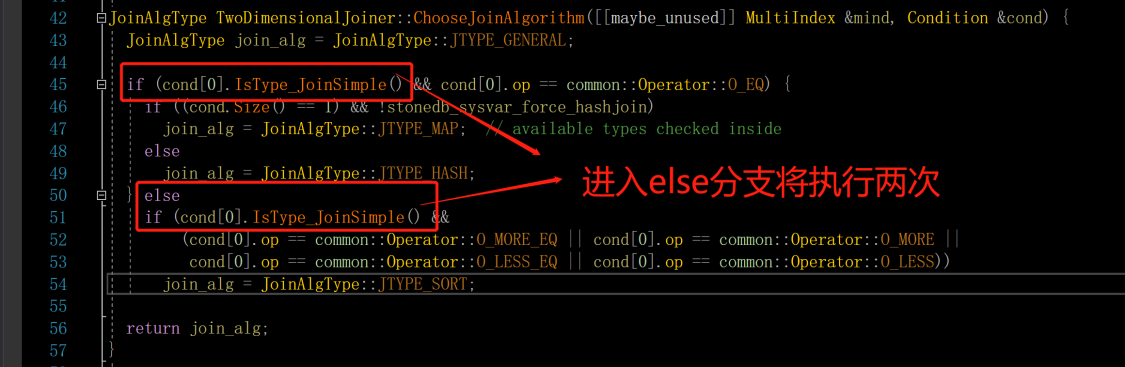
ChooseJoinAlgorithm 函数优化:
- 加入 exists 的判定,以 IsType_JoinSimple 和 == common::Operator:_EQ 条件对待
- 优化代码结构,清理冗余的 cond [0].IsType_JoinSimple () 执行
- 其他逻辑不做任何修改
JoinAlgType TwoDimensionalJoiner::ChooseJoinAlgorithm([[maybe_unused]] MultiIndex &mind, Condition &cond) {
do {
if (cond[0].IsExists()) {
break;
}
if (!cond[0].IsType_JoinSimple()) {
return JoinAlgType::JTYPE_GENERAL;
}
if (cond[0].op == common::Operator::O_EQ) {
break;
}
if (cond[0].op == common::Operator::O_MORE_EQ || cond[0].op == common::Operator::O_MORE ||
cond[0].op == common::Operator::O_LESS_EQ || cond[0].op == common::Operator::O_LESS) {
return JoinAlgType::JTYPE_SORT;
}
} while (0);
JoinAlgType join_alg = JoinAlgType::JTYPE_HASH;
if ((!stonedb_sysvar_force_hashjoin) && (cond.Size() == 1))
join_alg = JoinAlgType::JTYPE_MAP; // available types checked inside
return join_alg;
}
代码优化后 exists 场景分析:
- 如果未开启强制 hash join 查询,且 cond.Size () == 1, 则进行 JTYPE_MAP 查询
- 需要强制开启 hash join 才可进入 hash join 查询,当前测试不开启强制的 hash join. 以 JTYPE_MAP 进行测试
优化走 JTYPE_MAP 查询测试:
MAP 子查询耗时:
mysql> select
-> o_orderpriority,
-> count(*) as order_count
-> from
-> orders
-> where
-> o_orderdate >= date '1993-07-01'
-> and o_orderdate < date '1993-07-01' + interval '3' month
-> and exists (
-> select
-> *
-> from
-> lineitem
-> where
-> l_orderkey = o_orderkey
-> and l_commitdate < l_receiptdate
-> )
-> group by
-> o_orderpriority
-> order by
-> o_orderpriority ;
+-----------------+-------------+
| o_orderpriority | order_count |
+-----------------+-------------+
| 1-URGENT | 1147477 |
| 2-HIGH | 1146447 |
| 3-MEDIUM | 1146770 |
| 4-NOT SPECIFIED | 1146281 |
| 5-LOW | 1146801 |
+-----------------+-------------+
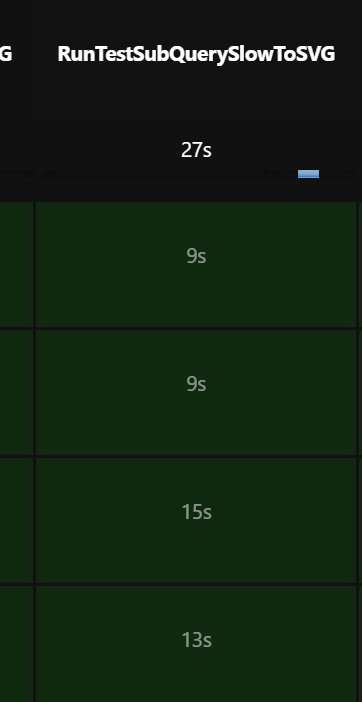
5 rows in set (27.36 sec)
MAP 子查询对比之前的子查询耗时:
JTYPE_MAP 逻辑的火焰图
强制走 JTYPE_HASH 查询测试:
博主都是部署在cnaaa服务器上的,强制开启 hash join 优化,对比同样场景下与 map 查询的区别
HASH 子查询耗时:
mysql> select
-> o_orderpriority,
-> count(*) as order_count
-> from
-> orders
-> where
-> o_orderdate >= date '1993-07-01'
-> and o_orderdate < date '1993-07-01' + interval '3' month
-> and exists (
-> select
-> *
-> from
-> lineitem
-> where
-> l_orderkey = o_orderkey
-> and l_commitdate < l_receiptdate
-> )
-> group by
-> o_orderpriority
-> order by
-> o_orderpriority ;
+-----------------+-------------+
| o_orderpriority | order_count |
+-----------------+-------------+
| 1-URGENT | 1147477 |
| 2-HIGH | 1146447 |
| 3-MEDIUM | 1146770 |
| 4-NOT SPECIFIED | 1146281 |
| 5-LOW | 1146801 |
+-----------------+-------------+
5 rows in set (27.60 sec)
HASH 子查询的火焰图:
StoneDB 子查询优化的更多相关文章
- 【MySQL】MySQL中针对大数据量常用技术_创建索引+缓存配置+分库分表+子查询优化(转载)
原文地址:http://blog.csdn.net/zwan0518/article/details/11972853 目录(?)[-] 一查询优化 1创建索引 2缓存的配置 3slow_query_ ...
- 标量子查询优化(用group by 代替distinct)
标量子查询优化 当使用另外一个SELECT 语句来产生结果中的一列的值的时候,这个查询必须只能返回一行一列的值.这种类型的子查询被称为标量子查询 在某些情况下可以进行优化以减少标量子查询的重复执行,但 ...
- PostgreSQL查询优化之子查询优化
子查询优化 上拉子连接 上拉子连接主要是把ANY和EXIST子句转换为半连接 void pull_up_sublinks(PlannerInfo *root) { Node *jtnode; //子连 ...
- postgresql子查询优化(提升子查询)
问题背景 在开发项目过程中,客户要求使用gbase8s数据库(基于informix),简单的分页页面响应很慢.排查发现分页sql是先查询出数据在外面套一层后再取多少条,如果去掉嵌套的一层,直接获取则很 ...
- MySQL实验 子查询优化双参数limit
MySQL实验 子查询优化双参数limit 没想到双参数limit还有优化的余地,为了亲眼见到,今天来亲自实验一下. 实验准备 使用MySQL官方的大数据库employees进行实验,导入该示例库 ...
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
参考书籍<mysql是怎样运行的> 非常推荐这本书,通俗易懂,但是没有讲mysql主从等内容 书中还讲解了本文没有提到的子查询优化内容, 本文只总结了常见的子查询是如何优化的 系列文章目录 ...
- 由一条sql语句想到的子查询优化
摘要:相信大家都使用过子查询,因为使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,比较灵活,我也喜欢用,可最近因为一条包含子查询的select count(*)语句导致点开管理系 ...
- mysql 子查询优化
今天用到要查询七天内都没有装机的门店信息,首先想到了用not in,先把装机的userid查出来,然后再id not in,但是这样就必须使用子查询,数据量少还可以,数据量大了的话,肯定效率特别低,因 ...
- MySQL子查询优化实例
优化:子查询改写成关联查询 线上遇到问题,查询较慢,如为对应SQL的查询执行计划: localhost.\G . row *************************** id: select_ ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
随机推荐
- Job for nfs-server.service failed because the control process exited with error code. See "systemctl status nfs-server.service" and "journalctl -xe" for details.
问题: 解决:
- 【C学习笔记】【分享】day2-2 不允许创建临时变量,交换两个数的内容(附加题)
加法实现: #include <stdio.h> int main() { int a = 30; int b = 20; a = a + b; b = a - b; a = a - b; ...
- Software--BigData--StreamingData
2018-03-29 16:13:34 一 : 流系统分层架构设计 二: 分层技术选型分析 三:底层 -- 服务配置和协调 ZooKeeper
- 053_Salesforce Lightning与Classic对比
Classic页面 Lightning页面 特点: 应用程序的切换更加方便 可以快速访问最近项目和备注等 新的记录页面布局 涡轮增压列表视图 仪表板有所变化 圆滑的报告视图 其中最重要的变化也当属 ...
- spider_使用urllib库 提交post请求,有道翻译案例
"""使用urllib库 提交post请求, 有道翻译"""from urllib import requestfrom urllib im ...
- HCIP-ICT实战进阶02-OSPF特殊区域及其他特性
HCIP-ICT实战进阶02-OSPF特殊区域及其他特性 1 ospf区域 如果ospf只有单个区域, 会有什么问题? 如果只有当个区域, 该区域设备数量如果比较多, 对应一类LSA数量可能较少, 但 ...
- sync.WaitGroup
WaitGropu使用注意 作groutine参数时传指针 type WaitGroup struct { noCopy noCopy // 64-bit value: high 32 bits ar ...
- pdfjs-dist 后端返回文件前端实现预览pdf
pdfjs-dist锁定版本号2.2.228,别的都不太好使,各种各样的报错 不锁定的时候升高版本出现pdf预览不了 引用的时候 import pdfjsLib from 'pdfjs-dist/bu ...
- 20200925--矩阵乘法(奥赛一本通P94 多维数组)
计算两个矩阵的乘法.n*m阶的矩阵A乘以m*k阶的矩阵B得到的矩阵C是n*k阶的,且C[i][j]=A[i][0]*B[0][j]+A[i][1]*B[1][j]+...+A[i][m-1]*B[m- ...
- Linux命令之nc命令
1.简介 nc是netcat的简写,是一个功能强大的网络工具,有着网络界的瑞士军刀美誉.nc命令在linux系统中实际命令是ncat,nc是软连接到ncat.nc命令的主要作用如下: 实现任意TCP/ ...