StoneDB 子查询优化
StoneDB 子查询优化
摘要:
说明如何优化 exists 的 join 查询优化器的处理
核心函数:
TwoDimensionalJoiner::ChooseJoinAlgorithm
JoinAlgType TwoDimensionalJoiner::ChooseJoinAlgorithm([[maybe_unused]] MultiIndex &mind, Condition &cond) {
JoinAlgType join_alg = JoinAlgType::JTYPE_GENERAL;
if (cond[0].IsType_JoinSimple() && cond[0].op == common::Operator::O_EQ) {
if ((cond.Size() == 1) && !stonedb_sysvar_force_hashjoin)
join_alg = JoinAlgType::JTYPE_MAP; // available types checked inside
else
join_alg = JoinAlgType::JTYPE_HASH;
} else {
if (cond[0].IsType_JoinSimple() &&
(cond[0].op == common::Operator::O_MORE_EQ || cond[0].op == common::Operator::O_MORE ||
cond[0].op == common::Operator::O_LESS_EQ || cond[0].op == common::Operator::O_LESS))
join_alg = JoinAlgType::JTYPE_SORT;
}
return join_alg;
}
选择 join 优化器问题分析:
- 仅判定 join simple 场景,未判断 exists 子句
- cond [0].IsType_JoinSimple () 如果走入了 else 分支,相当于被执行了两次
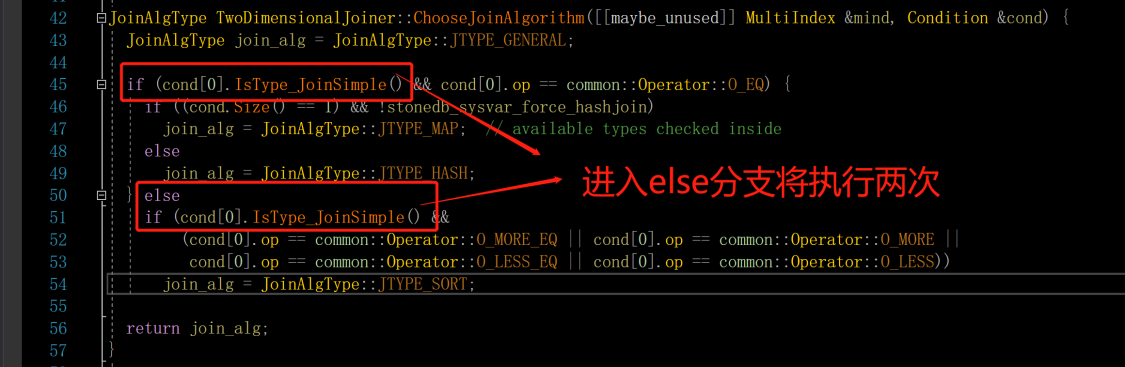
ChooseJoinAlgorithm 函数优化:
- 加入 exists 的判定,以 IsType_JoinSimple 和 == common::Operator:_EQ 条件对待
- 优化代码结构,清理冗余的 cond [0].IsType_JoinSimple () 执行
- 其他逻辑不做任何修改
JoinAlgType TwoDimensionalJoiner::ChooseJoinAlgorithm([[maybe_unused]] MultiIndex &mind, Condition &cond) {
do {
if (cond[0].IsExists()) {
break;
}
if (!cond[0].IsType_JoinSimple()) {
return JoinAlgType::JTYPE_GENERAL;
}
if (cond[0].op == common::Operator::O_EQ) {
break;
}
if (cond[0].op == common::Operator::O_MORE_EQ || cond[0].op == common::Operator::O_MORE ||
cond[0].op == common::Operator::O_LESS_EQ || cond[0].op == common::Operator::O_LESS) {
return JoinAlgType::JTYPE_SORT;
}
} while (0);
JoinAlgType join_alg = JoinAlgType::JTYPE_HASH;
if ((!stonedb_sysvar_force_hashjoin) && (cond.Size() == 1))
join_alg = JoinAlgType::JTYPE_MAP; // available types checked inside
return join_alg;
}
代码优化后 exists 场景分析:
- 如果未开启强制 hash join 查询,且 cond.Size () == 1, 则进行 JTYPE_MAP 查询
- 需要强制开启 hash join 才可进入 hash join 查询,当前测试不开启强制的 hash join. 以 JTYPE_MAP 进行测试
优化走 JTYPE_MAP 查询测试:
MAP 子查询耗时:
mysql> select
-> o_orderpriority,
-> count(*) as order_count
-> from
-> orders
-> where
-> o_orderdate >= date '1993-07-01'
-> and o_orderdate < date '1993-07-01' + interval '3' month
-> and exists (
-> select
-> *
-> from
-> lineitem
-> where
-> l_orderkey = o_orderkey
-> and l_commitdate < l_receiptdate
-> )
-> group by
-> o_orderpriority
-> order by
-> o_orderpriority ;
+-----------------+-------------+
| o_orderpriority | order_count |
+-----------------+-------------+
| 1-URGENT | 1147477 |
| 2-HIGH | 1146447 |
| 3-MEDIUM | 1146770 |
| 4-NOT SPECIFIED | 1146281 |
| 5-LOW | 1146801 |
+-----------------+-------------+
5 rows in set (27.36 sec)
MAP 子查询对比之前的子查询耗时:
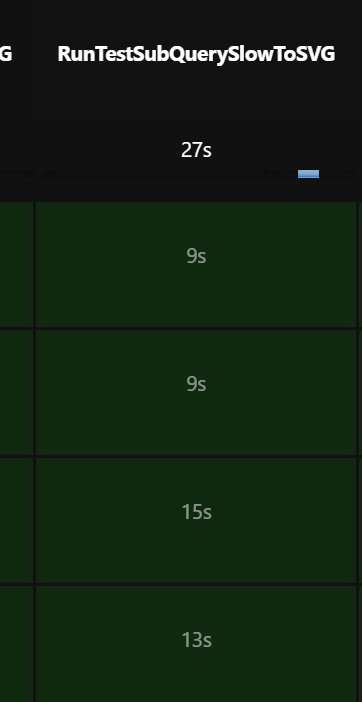
JTYPE_MAP 逻辑的火焰图
强制走 JTYPE_HASH 查询测试:
博主都是部署在cnaaa服务器上的,强制开启 hash join 优化,对比同样场景下与 map 查询的区别
HASH 子查询耗时:
mysql> select
-> o_orderpriority,
-> count(*) as order_count
-> from
-> orders
-> where
-> o_orderdate >= date '1993-07-01'
-> and o_orderdate < date '1993-07-01' + interval '3' month
-> and exists (
-> select
-> *
-> from
-> lineitem
-> where
-> l_orderkey = o_orderkey
-> and l_commitdate < l_receiptdate
-> )
-> group by
-> o_orderpriority
-> order by
-> o_orderpriority ;
+-----------------+-------------+
| o_orderpriority | order_count |
+-----------------+-------------+
| 1-URGENT | 1147477 |
| 2-HIGH | 1146447 |
| 3-MEDIUM | 1146770 |
| 4-NOT SPECIFIED | 1146281 |
| 5-LOW | 1146801 |
+-----------------+-------------+
5 rows in set (27.60 sec)
HASH 子查询的火焰图:
StoneDB 子查询优化的更多相关文章
- 【MySQL】MySQL中针对大数据量常用技术_创建索引+缓存配置+分库分表+子查询优化(转载)
原文地址:http://blog.csdn.net/zwan0518/article/details/11972853 目录(?)[-] 一查询优化 1创建索引 2缓存的配置 3slow_query_ ...
- 标量子查询优化(用group by 代替distinct)
标量子查询优化 当使用另外一个SELECT 语句来产生结果中的一列的值的时候,这个查询必须只能返回一行一列的值.这种类型的子查询被称为标量子查询 在某些情况下可以进行优化以减少标量子查询的重复执行,但 ...
- PostgreSQL查询优化之子查询优化
子查询优化 上拉子连接 上拉子连接主要是把ANY和EXIST子句转换为半连接 void pull_up_sublinks(PlannerInfo *root) { Node *jtnode; //子连 ...
- postgresql子查询优化(提升子查询)
问题背景 在开发项目过程中,客户要求使用gbase8s数据库(基于informix),简单的分页页面响应很慢.排查发现分页sql是先查询出数据在外面套一层后再取多少条,如果去掉嵌套的一层,直接获取则很 ...
- MySQL实验 子查询优化双参数limit
MySQL实验 子查询优化双参数limit 没想到双参数limit还有优化的余地,为了亲眼见到,今天来亲自实验一下. 实验准备 使用MySQL官方的大数据库employees进行实验,导入该示例库 ...
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
参考书籍<mysql是怎样运行的> 非常推荐这本书,通俗易懂,但是没有讲mysql主从等内容 书中还讲解了本文没有提到的子查询优化内容, 本文只总结了常见的子查询是如何优化的 系列文章目录 ...
- 由一条sql语句想到的子查询优化
摘要:相信大家都使用过子查询,因为使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,比较灵活,我也喜欢用,可最近因为一条包含子查询的select count(*)语句导致点开管理系 ...
- mysql 子查询优化
今天用到要查询七天内都没有装机的门店信息,首先想到了用not in,先把装机的userid查出来,然后再id not in,但是这样就必须使用子查询,数据量少还可以,数据量大了的话,肯定效率特别低,因 ...
- MySQL子查询优化实例
优化:子查询改写成关联查询 线上遇到问题,查询较慢,如为对应SQL的查询执行计划: localhost.\G . row *************************** id: select_ ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
随机推荐
- dialog弹窗里生成二维码 (reading qppendChild)
在dialog弹窗里生成二维码第一次点击时 dialogFormVisible.value=false,二维码生成时会找不到对象可以用nextTick()函数 将二维码生成代码放到nextTick() ...
- .NET在单台Windows2008下百万TCP连接测试
测试客户端: 客户端程序建立TCP连接,发送一条几个字节的数据. 虚拟机8台,PC机8台,服务器1台. 设置MaxUserPort=60000,有一台机没有设置约在1.5万左右.最后因为差一点到100 ...
- Java流程控制之while循环详解
while循环 while循环 do...while循环 for循环 在Java5中引入了一种主要用于数组的增强型for循环 while循环 while循环是最基本的循环,它的结构为 while(布尔 ...
- ORACLE查看会话的大小及终止会话
一.出现PGA不足时,我们可以查看用户会话大小,结束相应会话 方法一 Select Server, Osuser, Name, Value / 1024 / 1024 Mb, s.Sql_Id, Sp ...
- ApacheBench(压力测试)
1.post请求 (post.txt body信息) ab -c2000 -n50 -p post.txt -T "application/json" url 2.get 请求 ...
- C++ 手动实现双向链表(作业版)
双向链表,并实现增删查改等功能 首先定义节点类,类成员包含当前节点的值, 指向下一个节点的指针和指向上一个节点的指针 //节点定义 template <typename T> class ...
- jmeter非GUI模式优点及实例说明
JMeter可以运行模式有两种,一种是GUI图形,另一种是命令模式运行也就是非GUI模式.两种模式的区别还是挺大的. GUI:由于是图形界面,所以在运行时会消耗很多资源,而且图形界面运行时结果是保存在 ...
- opencv基本函数详解笔记
一.读取保存图片 Mat scrImage = imread("1.jpg"); //显示图像 imshow("原图", scrImage); //窗口等待 w ...
- Dapper显示
<h2>商品列表</h2> <a id="a">导出列表</a> <table class="table table ...
- stream 在 groupingby 之后,对结果数据再进行封装后返回
使用 Collectors.mapping 来指定 分组结果要取哪些数据