ABAP READ内表新老语法对比
1、读取内表行新语法
740新语法中,对标READ,提出了新的语法,如下:
1.1、根据字段值查找
"-----------------------------@斌将军-----------------------------
"老语法
READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs.
IF sy-subrc EQ 0. ENDIF. "新语法
ls_acd = lt_acd[ rbukrs = gs_acd-rbukrs ].
"-----------------------------@斌将军-----------------------------
1.2、按索引查找
"-----------------------------@斌将军-----------------------------
"老语法
READ TABLE lt_acd INTO ls_acd INDEX 1.
IF sy-subrc EQ 0. ENDIF. "新语法
ls_acd = lt_acd[ 1 ].
"-----------------------------@斌将军-----------------------------
1.3、判断记录是否存在
"-----------------------------@斌将军-----------------------------
"老语法
READ TABLE lt_acd WITH KEY rbukrs = gs_acd-rbukrs TRANSPORTING NO FIELDS.
IF sy-subrc EQ 0. ENDIF. "新语法
IF LINE_EXISTS( lt_acd[ rbukrs = gs_acd-rbukrs ] ). ENDIF.
"-----------------------------@斌将军-----------------------------
1.4、获取行索引
"-----------------------------@斌将军-----------------------------
"老语法
READ TABLE lt_acd WITH KEY rbukrs = gs_acd-rbukrs TRANSPORTING NO FIELDS.
IF sy-subrc EQ 0.
WRITE:SY-TABIX.
ENDIF. "新语法
LV_INDEX = LINE_INDEX( lt_acd[ rbukrs = gs_acd-rbukrs ] ).
"-----------------------------@斌将军-----------------------------
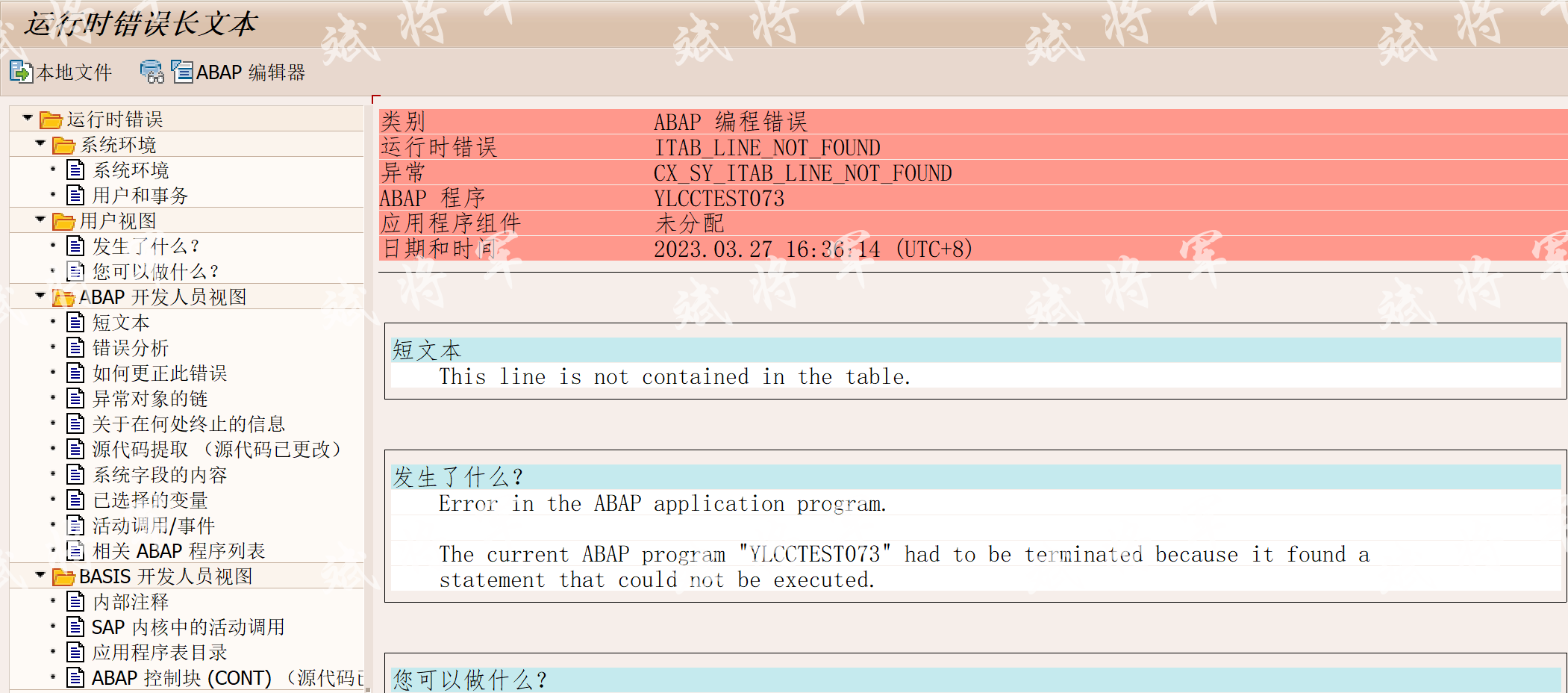
需要特别注意的是,新语法必须用TRY CATCH,或在查询前,用LINE_EXISTS()判断是否存在,否则将会导致DUMP
TRY .
ls_acd = lt_acd[ rbukrs = '333' ].
CATCH cx_sy_itab_line_not_found .
MESSAGE '未找到数据' TYPE 'E' .
ENDTRY. "或 IF line_exists( lt_acd[ rbukrs = '333' ] ).
ls_acd = lt_acd[ rbukrs = '333' ].
ELSE.
MESSAGE '未找到数据' TYPE 'E' .
ENDIF.
2.效率对比
由于老语法可以使用二分法查找,因此在效率上将会有差异。
现编写一个实例,循环2万条数据GT_ACD,并循环查询有14万条数据的LT_ACD中对应的值。下边测试各种情况下的查询速度
2.1、新语法
"-----------------------------@斌将军-----------------------------
"1.测试新语法------------------------------------
GET TIME STAMP FIELD lv_current1.
CLEAR:lv_index.
LOOP AT gt_acd INTO gs_acd.
lv_index = lv_index + 1.
TRY .
ls_acd = lt_acd[ rbukrs = gs_acd-rbukrs gjahr = gs_acd-gjahr belnr = gs_acd-belnr docln = gs_acd-docln ].
CATCH cx_sy_itab_line_not_found .
MESSAGE '未找到数据' TYPE 'E' .
ENDTRY.
ENDLOOP.
GET TIME STAMP FIELD lv_current2.
"-----------------------------@斌将军-----------------------------
结果:

2.2、老语法READ
"-----------------------------@斌将军-----------------------------
"2.测试老语法------------------------------------
GET TIME STAMP FIELD lv_current1.
CLEAR:lv_index.
LOOP AT gt_acd INTO gs_acd.
lv_index = lv_index + 1.
READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs
gjahr = gs_acd-gjahr
belnr = gs_acd-belnr
docln = gs_acd-docln.
IF sy-subrc EQ 0. ENDIF.
ENDLOOP.
GET TIME STAMP FIELD lv_current2.
"-----------------------------@斌将军-----------------------------
结果:

2.3、老语法READ二分查找
"-----------------------------@斌将军-----------------------------
GET TIME STAMP FIELD lv_current1.
CLEAR:lv_index.
SORT lt_acd BY rbukrs gjahr belnr docln.
LOOP AT gt_acd INTO gs_acd. READ TABLE lt_acd INTO ls_acd WITH KEY rbukrs = gs_acd-rbukrs
gjahr = gs_acd-gjahr
belnr = gs_acd-belnr
docln = gs_acd-docln BINARY SEARCH.
IF sy-subrc EQ 0.
lv_index = lv_index + 1.
ENDIF.
ENDLOOP.
GET TIME STAMP FIELD lv_current2.
"-----------------------------@斌将军-----------------------------
结果:< 1S

2.4、新语法+排序表
"-----------------------------@斌将军-----------------------------
"4.测试新语法+排序表------------------------------------
lt_acd_sort = lt_acd.
GET TIME STAMP FIELD lv_current1.
CLEAR:lv_index.
LOOP AT gt_acd INTO gs_acd.
lv_index = lv_index + 1.
TRY .
ls_acd = lt_acd_sort[ rbukrs = gs_acd-rbukrs gjahr = gs_acd-gjahr belnr = gs_acd-belnr docln = gs_acd-docln ].
CATCH cx_sy_itab_line_not_found .
MESSAGE '未找到数据' TYPE 'E' .
ENDTRY.
ENDLOOP.
GET TIME STAMP FIELD lv_current2.
"-----------------------------@斌将军-----------------------------
结果:< 1S

综上所述:不使用二分查找,则新老语法都很慢。使用二分查找或新语法搭配排序表,则速度都有非常明显的提升
- 中文(简体)
- 中文(繁体)
- 丹麦语
- 乌克兰语
- 乌尔都语
- 亚美尼亚语
- 俄语
- 保加利亚语
- 克罗地亚语
- 冰岛语
- 加泰罗尼亚语
- 匈牙利语
- 卡纳达语
- 印地语
- 印尼语
- 古吉拉特语
- 哈萨克语
- 土耳其语
- 威尔士语
- 孟加拉语
- 尼泊尔语
- 布尔语(南非荷兰语)
- 希伯来语
- 希腊语
- 库尔德语
- 德语
- 意大利语
- 拉脱维亚语
- 挪威语
- 捷克语
- 斯洛伐克语
- 斯洛文尼亚语
- 旁遮普语
- 日语
- 普什图语
- 毛利语
- 法语
- 波兰语
- 波斯语
- 泰卢固语
- 泰米尔语
- 泰语
- 海地克里奥尔语
- 爱沙尼亚语
- 瑞典语
- 立陶宛语
- 缅甸语
- 罗马尼亚语
- 老挝语
- 芬兰语
- 英语
- 荷兰语
- 萨摩亚语
- 葡萄牙语
- 西班牙语
- 越南语
- 阿塞拜疆语
- 阿姆哈拉语
- 阿尔巴尼亚语
- 阿拉伯语
- 韩语
- 马尔加什语
- 马拉地语
- 马拉雅拉姆语
- 马来语
- 马耳他语
- 高棉语
一律不翻译英语
一律不翻译i.cnblogs.com
ABAP READ内表新老语法对比的更多相关文章
- ABAP 动态内表添加单元格颜色字段
*动态内表alv显示时要求某些单元格显示颜色 *wa_fldcat-datatype不能添加LVC_T_SCOL类型,在创建好内表之后,再添加颜色列. DATA: wa_fldcat TYPE lvc ...
- 转载: ABAP动态内表操作
顾名思义,动态表的列是可以根据数据的变化而变化的,会使报表显示更简洁漂亮. 以下是实现方法. ------------------------------------------- 1, 创建动态内表 ...
- 转ABAP将内表行列转换实例(动态内表) .
把内表的行列转换,网上的例子很多,但是新人想看懂,几乎很难,所以总结下我是怎么完成的. 比如:你的内表如图: 你想让内表最后展示成这样:如图: 那么完成之后会是这样: 完成这个过程,得用到动态内表.看 ...
- ABAP 动态内表 动态ALV
DATA: DY_TABLE TYPE REF TO DATA, DY_WA TYPE REF TO DATA. FIELD-SYMBOLS: <DYN_TABLE> TYPE TABLE ...
- SAP ABAP: 把内表数据以excel或csv格式,通过前台或者后台的方式上传至FTP服务器
今天接到一个FTP的需求,就是每天晚上把当天某个报表的数据自动保存excel上传到FTP服务器. SAP已经有现成的FTP函数使用,可以通过函数的方式来实现,实现前先准备一些数据: User:登录FT ...
- express新旧语法对比
备个份, 原文: http://stackoverflow.com/questions/25550819/error-most-middleware-like-bodyparser-is-no-lon ...
- abap将内表数据导出为excel文件
一个不错的方案: WHEN 'EXPORT'. "导出数据 DATA : GT_TEMP TYPE TABLE OF TY_ITEM WITH HEADER LINE. LOOP AT GT ...
- ffmpeg新老接口对比
http://blog.csdn.net/leixiaohua1020/article/details/41013567
- ABAP 7.4 新语法-内嵌生命和内表操作(转)
转自:https://www.cnblogs.com/mingdashu/p/6744637.html ABAP 7.4 新语法-内嵌生命和内表操作 1.内嵌声明 2.内表操作 3.opensql ...
- 2019.11.07【每天学点SAP小知识】Day2 - ABAP 7.40新语法 - 内表
今天学习一下内表的表达式在ABAP 7.4之后的语法: SELECT * FROM mara INTO TABLE @DATA(gt_mara)UP TO 10 ROWS. DATA gt_mara_ ...
随机推荐
- 前端element ui 文件base64加密字符串 上传
<el-form-item label="附件" prop="attachment"> <el-upload :multiple=" ...
- bert一些思考
bert结构 首先是embdding lookup,[batch * seq]-->[batch, seq, hidden] 然后是加个mask embdding和type embdding和p ...
- P77 3.12
#P77 3.12 #一年365天,初始水平值为1.0,每工作一天水平增加N, #不工作时水平不下降,一周连续工作4天,请编写程序运算 #结果并填写表格 n = 1.0 for j in range ...
- python音乐分类--knn
1 #利用knn算法分类音乐,将音乐进行情绪分类 2 #将音乐分为兴奋的(excited), 愤怒的(angry),悲伤的(sorrowful),轻松的(relaxed) 3 4 #可分离因素 5 # ...
- Bug的前后台分类及定位技巧
必备工具:Firefox debug工具 一般浏览器F12即可 如何区分页面的bug问题归属:前端or后端 前端bug主要分为3个类别:HTML,CSS,Javascript三类问题 给个最大的区 ...
- 第一次作业:https://edu.cnblogs.com/campus/qdu/DS2020/homework/11165
大家好,我是信息与计算科学一班的刘宝龙.爱好是看动漫,玩游戏,听音乐,不喜欢户外运动,是一个二次元宅男.但是喜欢交朋友,希望能与班里所有的同学建立良好的同学关系. 自己的强项是与人的交流与沟通,还有遇 ...
- JVM - 1.内存结构
1 内存结构 1.1 程序计数器 1.1.1 作用 在执行的过程中 , 记住下一条jvm指令的执行地址 物理上通过寄存器实现 1.1.2 特性 每个线程都有自己的程序计数器 - 线程私有 不会存在内存 ...
- django_静态文件
**************************************************************************************************** ...
- c++ProgrammingConcept
本文做为总章简单介绍自己的c++学习过程(学习书籍:c++编程思想) 第三章:c++中的c(part1) 第三章:c++中的c(part2)
- 图模配置文件之 flow.json
flow.json文件是用来配置图模导入时,各种不同的图模导入时,分别应该使用哪个映射文件对模型进行处理.在不同地区使用不同的格式的图模文件时,需要修改flow.json中相关的配置,来适应相应的图模 ...