Kafka 之 Streams
Kafka 之 Streams
一、概述
1.1 Kafka Streams
Kafka Streams。Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。
1.2 Kafka Streams特点
1)功能强大
高扩展性,弹性,容错
2)轻量级
无需专门的集群
一个库,而不是框架
3)完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
4)实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
1.3 为什么要有Kafka Stream
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?主要有如下原因。
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。

第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。但是Kafka作为类库不占用系统资源。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
二、Kafka Stream数据清洗案例
0)需求:
实时处理单词带有”>>>”前缀的内容。例如输入”atguigu>>>ximenqing”,最终处理成“ximenqing”
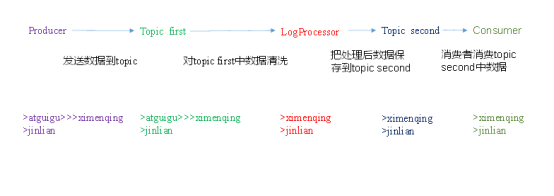
2)案例实操
(1)创建一个工程,并添加jar包
(2)创建主类
package com.libt.kafka.stream;
import java.util.Properties;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder; public class Application { public static void main(String[] args) { // 定义输入的topic
String from = "first";
// 定义输出的topic
String to = "second"; // 设置参数
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop1:9092"); StreamsConfig config = new StreamsConfig(settings); // 构建拓扑
TopologyBuilder builder = new TopologyBuilder(); builder.addSource("SOURCE", from)
.addProcessor("PROCESS", new ProcessorSupplier<byte[], byte[]>() { @Override
public Processor<byte[], byte[]> get() {
// 具体分析处理
return new LogProcessor();
}
}, "SOURCE")
.addSink("SINK", to, "PROCESS"); // 创建kafka stream
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
(3)具体业务处理
package com.libt.kafka.stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext; public class LogProcessor implements Processor<byte[], byte[]> { private ProcessorContext context; @Override
public void init(ProcessorContext context) {
this.context = context;
} @Override
public void process(byte[] key, byte[] value) {
String input = new String(value); // 如果包含“>>>”则只保留该标记后面的内容
if (input.contains(">>>")) {
input = input.split(">>>")[1].trim();
// 输出到下一个topic
context.forward("logProcessor".getBytes(), input.getBytes());
}else{
context.forward("logProcessor".getBytes(), input.getBytes());
}
} @Override
public void punctuate(long timestamp) { } @Override
public void close() { }
}
(4)运行程序
(5)在hadoop1上启动生产者
[hadoop1 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop1:9092 --topic first >hello>>>world
>h>>>hello
>hahaha
(6)在hadoop2上启动消费者
[hadoop2 kafka]$ bin/kafka-console-consumer.sh \
--zookeeper hadoop1:2181 --from-beginning --topic second world
atguigu
hahaha
Kafka 之 Streams的更多相关文章
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- Kafka Streams | 流,实时处理和功能
1.目标 在我们之前的Kafka教程中,我们讨论了Kafka中的ZooKeeper.今天,在这个Kafka Streams教程中,我们将学习Kafka中Streams的实际含义.此外,我们将看到Kaf ...
- 翻译 - Kafka Streams 介绍(一)
2019独角兽企业重金招聘Python工程师标准>>> 资料 [原文地址](http://kafka.apache.org/11/documentation/streams/) 正文 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka Ecosystem(Kafka生态)
http://kafka.apache.org/documentation/#ecosystem https://cwiki.apache.org/confluence/display/KAFKA/E ...
- Kafka 0.11.0.0 实现 producer的Exactly-once 语义(英文)
Exactly-once Semantics are Possible: Here’s How Kafka Does it I’m thrilled that we have hit an excit ...
- How Cigna Tuned Its Spark Streaming App for Real-time Processing with Apache Kafka
Explore the configuration changes that Cigna’s Big Data Analytics team has made to optimize the perf ...
- Streaming SQL for Apache Kafka
KSQL是基于Kafka的Streams API进行构建的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的.完全交互式的SQL接口,用于处理Kafka的数据. KSQL是一套基于Apa ...
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
随机推荐
- python--函数--参数传入分类
1. 位置参数 调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致. 2. 关键字参数 好处:不用记住形参位置. 所谓关键字就是"键-值"绑定,调用函数时,进行传递. 特 ...
- Maven 聚合工程
第一步: 创建Maven聚合工程: 父工程Maven工程的打包方式必须为pom 创建一个Maven工程 修改父工程的pom.xml,设置打包方式为pom <?xml version=" ...
- 【PHP库】phpseclib - sftp远程文件操作
需求场景说明 对接的三方商家需要进行文件传输,并且对方提供的方式是 sftp 的服务器账号,我们需根据他们提供的目录进行下载和上传指定文件. 安装 composer require phpseclib ...
- Luogu2858[USACO06FEB]奶牛零食Treats for the Cows (区间DP)
我是个傻逼,这么水的题都会T #include <iostream> #include <cstdio> #include <cstring> #include & ...
- TS 泛型推断好难啊,看看你能写出来不
前言 最近做东西都在用ts,有时候写比较复杂的功能,如果不熟悉,类型写起来还是挺麻烦的.有这样一个功能,在这里,我们就不以我们现有的业务来举例了,我们还是已Animal举例,来说明场景.通过一个工厂来 ...
- Druid学习之查询语法
写在前面 最近一段时间都在做druid实时数据查询的工作,本文简单将官网上的英文文档加上自己的理解翻译成中文,同时将自己遇到的问题及解决方法list下,防止遗忘. 本文的demo示例均来源于官网. D ...
- 四 多例模式【Multition Pattern】 来自CBF4LIFE 的设计模式
出现在明朝,那三国期间的算不算,不算,各自称帝,各有各的地盘,国号不同.大家还记得那首诗<石灰吟>吗?作者是谁?于谦,他是被谁杀死的?明英宗朱祁镇,对,就是那个在土木堡之变中被瓦刺俘虏的皇 ...
- 如何做raid级别磁盘(rhel和centos系统皆可)
添加磁盘,自己需要多少磁盘即可添加多少数量 此处只添加了三块200MB大小的磁盘 此处三块磁盘,只有两块做raid,一块与raid磁盘为实验测读写速率,不测速率可三块都做raid. 进入虚拟机给三个磁 ...
- 【Vue学习笔记】—— vuex的语法 { }
学习笔记 作者:o_Ming vuex Vuex ++ state ++ (用于存储全局数据) 组件访问 state 中的全局数据的方式1: this.$store.state.全局数据 组件访问 s ...
- haodoop数据压缩
压缩概述 压缩技术能够有效减少底层存储系统(HDFS)读写字节数.压缩提高了网络宽带和磁盘空间的效率.在运行MR程序时,I/O操作,网络数据传输,Shuffle和Merge要花大量的时间,尤其是数据规 ...