图书管理系统、聚合函数、分组查询、F与Q查询
图书管理系统
在针对数据路迁移失败时的问题, 一个数据库是只对应一个Django项目的,不要出现多个Django项目使用一个数据库 这样极其容易出现报错的得
1.表设计
首先要考虑普通字段崽考虑外键字段的数据库迁移、测试数据录入
当中自己先要确定一张最重要的表 书籍表
其他表数据:出版社表 作者表 作者详情表 还有多对多关系的由ORM自动创建的虚拟表
再对数据对数据录入时首先录入的得是出版社表和作者详情表,因为要考虑其他外键相关联 其他表先入的话没有数据来源无法录入的
2.首页搭建、展示
先路由层

再视图层中编写个home_func视图函数是要返回一个html页面的 再模型层中定义html文件homePage.html

g)
再确认主页面如何布局

要展示所有的图书信息

先要获取到所有的图书数据

要返回一个HTML页面 而且都是展示给用户看的信息 使用table表格标签
使用模板继承 在母板中圈出划定子板可修改的区域 block

母模板中至少应该标明三个区域:
页面内容、CSS样式区、JS代码区

继承页booklistPage在content编写的html会把母板写的替换掉
展示从1开始的有序数列 模板语法中的for循环 有一个特殊的关键 forloop(如果直接是主键展示的话将不会是有序的因为对有做修改的话将不是有序的)

这里要注意哦,时间是结构化时间无法展示,所以得对时间格式化。以及作者的展示,书跟作者是多对多的关系,一本书可能对应多个作者拿到的是,列表套多个对象

用标签的过滤器内置方法date对结构化时间做格式化处理

对作者for循环

在渲染中添加条件展示 模板语法for循环中关键字forloop

再添加编辑与删除按钮
书籍的添加
返回一个让用户可以输入书籍的相关数据的HTML页面

继承页bookAddPage在content编写的html会把母板写的替换掉
需要出版社和作者的全部数据

展示系统中的已有的出版社信息供选择和展示系统中已有的出版社信息供选择

再把用户选择的数据返回给后端

重定向redirect 在针对没有动态匹配的路由可以直接写

书籍编辑
首先要考虑在后端如何获取用户想要编辑的数据、前端如何展示出待编辑的数据?
用转换器路由匹配的方式

)
那么这时要注意在编写视图函数的时候传参

注意在添加作者以及出版社的时候要有默认值
根据编辑的书籍对象查询对应的出版社 与系统所有的出版社比对 如果有相同则添加默认选中的属性selected

作者默认选中

再传回到后端来

效果展示:
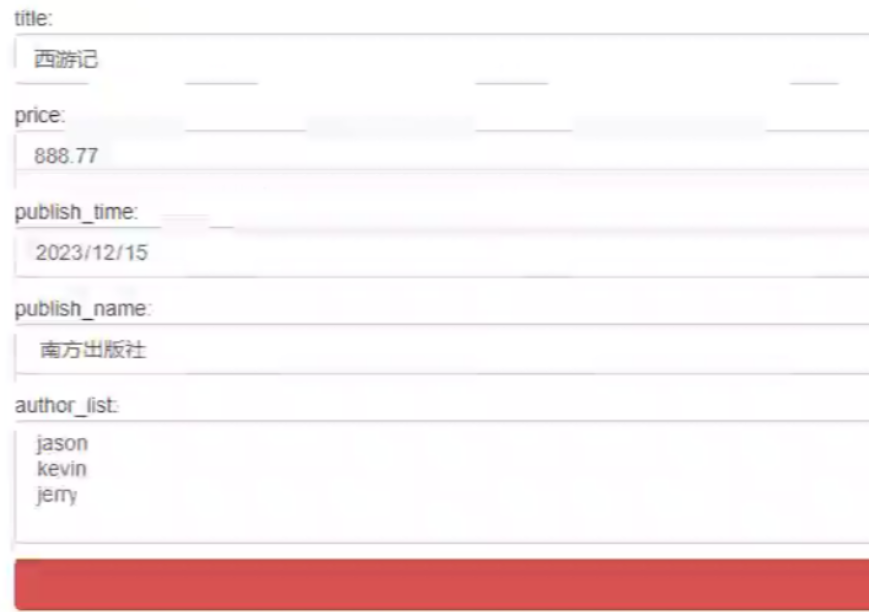
书籍删除
先编写删除接口

视图层视图函数

再对删除做一个二次确认 用到点击事件

聚合函数
聚合函数:
Max
Min
Sum
Count
Avg
在ORM中支持单独使用聚合函数 可以单独使用 关键字aggregate 需要导模块
from django.db.models import Max, Min, Sum, Count, Avg
res = models.Book.objects.aggregate(Max('price'), Count('pk'), 最小价格=Min('price'), allPrice=Sum('price'),平均价格=Avg('price'))
print(res)

分组查询
关键字annotate
如果在执行orm中出现有报错 并且有关键字sql_mode strict mode sql
移除sql_mode中的only_full_group_by
严格模式中将only_full_group_by模式移除
show variable like '%mode%';

按照表分组
models.表名.objects.annotate() 按照表分组
题目:统计每一本书的作者个数
分析:每一本数的作者个数肯定是按书来分组,从书籍表出发到作者表,外键是在书籍手里,所以是正向查询按外键字段
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
print(res)
# models后面点的什么 annotate就按照什么进行分组

题目:统计出每一个出版社卖的最便宜的书的价格
分析:每一个出版社肯定是按出版社来分组,从出版社表出发到书籍表,外键是在书籍手里,所以是反向查询按表名小写
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res)

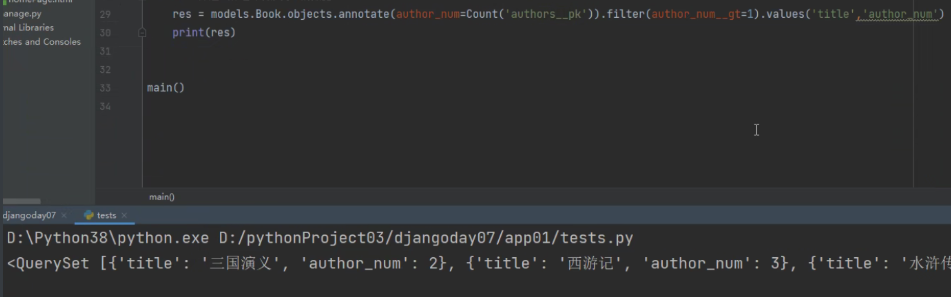
题目:统计不止一个作者的图书
分析:作者的图书不为1的 那么先要知道每一本书的作者个数 然后再筛选出大于1的。那么肯定是按书分组 从书表出发到作者表,外键在书籍手里,正向查询按外键字段
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title', 'author_num')
print(res)
题目:查询每个作者出的书的总价格
分析:每个作者肯定是按作者表分组,从作者表出发到书籍表,外键字段在书籍表,反向查询按表名小写
res = models.Author.objects.annotate(总价=Sum('book__price'),count_book=Count('book__pk')).values('name','总价','count_book')
print(res)

按照字段分组
按照values括号内指定的字段分组
models.表名.objects.values('字段名').annotate()
按出版社id分组

res = models.Book.objects.values('publish_id').annotate(count_pk=Count('pk')).values('publish_id', 'count_pk')
print(res)

F与Q查询
给表中添加两个字段 库存数与卖出总数
在当你的表中有数据你再给表中添加数据的时候 是会给提示的 原来表中是有数据的 添加了新的字段就不知道要给新添加的字段写什么数据

1是让你添加默认值 2是让你退出去 改模型层
给新添加的字段添加默认值

F查询
一般都是提供具体的数值

当查询条件不是明确的 要查询字段来自于其他字段 也需要从数据库中获取 就需要使用F查询
1.查询库存数大于卖出数的书籍
from django.db.models import F
res = models.Book.objects.filter(kucun__gt=F('maichu'))
print(res)
2.将所有书的价格涨800
models.Book.objects.update(price=F('price') + 800)
3.将所有书的名称后面追加爆款
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value('新款')))


Q查询
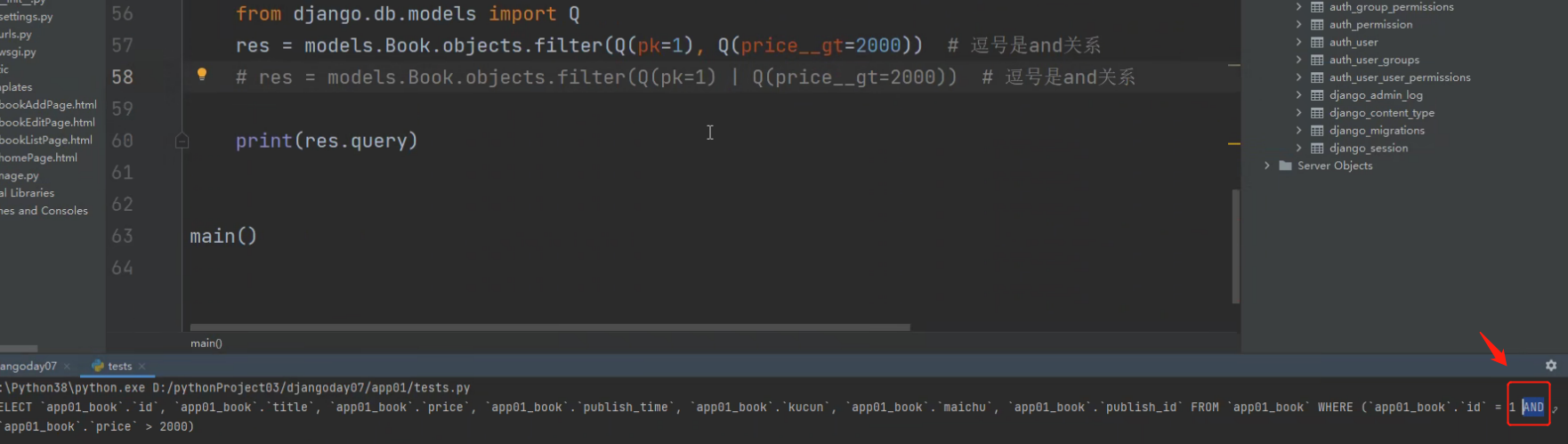
查询主键是1或者价格大于2000的书籍
将条件用Q包起来
逗号默认是and
查询主键是1和价格大于2000的书籍
res = models.Book.objects.filter(pk=1, price__gt=2000)
逗号默认是and关系
|是or
查询主键是1或者价格大于2000的书籍
from django.db.models import Q
res = models.Book.objects.filter(Q(pk=1) | Q(price__gt=2000)) # |是or
~是not
查询主键不是1或者价格大于2000的书籍
res = models.Book.objects.filter(~Q(pk=1) | Q(price__gt=2000)) # ~是not
print(res.query)

图书管理系统、聚合函数、分组查询、F与Q查询的更多相关文章
- Django 08 Django模型基础3(关系表的数据操作、表关联对象的访问、多表查询、聚合、分组、F、Q查询)
Django 08 Django模型基础3(关系表的数据操作.表关联对象的访问.多表查询.聚合.分组.F.Q查询) 一.关系表的数据操作 #为了能方便学习,我们进入项目的idle中去执行我们的操作,通 ...
- Django 聚合查询 分组查询 F与Q查询
一.聚合查询 需要导入模块:from django.db.models import Max, Min, Sum, Count, Avg 关键语法:aggregate(聚合结果别名 = 聚合函数(参数 ...
- Django模型系统——ORM中跨表、聚合、分组、F、Q
核心知识点: 1.明白表之间的关系 2.根据关联字段确定正反向,选择一种方式 在Django的ORM种,查询既可以通过查询的方向分为正向查询和反向查询,也可以通过不同的对象分为对象查询和Queryse ...
- Django orm进阶查询(聚合、分组、F查询、Q查询)、常见字段、查询优化及事务操作
Django orm进阶查询(聚合.分组.F查询.Q查询).常见字段.查询优化及事务操作 聚合查询 记住用到关键字aggregate然后还有几个常用的聚合函数就好了 from django.db.mo ...
- Django 聚合分组F与Q查询及choices
一.聚合查询 需要导入模块:from django.db.models import Max, Min, Sum, Count, Avg 关键语法:aggregate(聚合结果别名 = 聚合函数(参数 ...
- django----聚合查询 分组 F与Q查询 字段 及其 参数
目录 一.orm补充查询 聚合查询 1-1 分组查询 1-2 F与Q查询 1-3 二. 字段及其参数 常用字段 AutoField IntegerField CharField DateField D ...
- Django中多表的增删改查操作及聚合查询、F、Q查询
一.创建表 创建四个表:书籍,出版社,作者,作者详细信息 四个表之间关系:书籍和作者多对多,作者和作者详细信息一对一,出版社和书籍一对多 创建一对一的关系:OneToOne("要绑定关系的表 ...
- (day54)六、事务、分组、F、Q、常用字段、事务
目录 一.聚合查询aggregate 二.分组查询annotate 三.F与Q查询 (一)F查询 1. 查询库存数大于卖出数的书籍 2. 将所有书的价格上涨100块 3.将所有书的名称后面全部加上 & ...
- django基础之day05,F与Q查询,Q查询的高级用法
#F与Q查询 #*************************** F 查询 ******************** # F 查询数据库中的其他字段!!! #1.查询库存数大于卖出数的书籍 fr ...
- django F与Q查询 事务 only与defer
F与Q 查询 class Product(models.Model): name = models.CharField(max_length=32) #都是类实例化出来的对象 price = mode ...
随机推荐
- cAdvisor容器监控规则
其他说明参考host主机监控规则:https://www.cnblogs.com/sanduzxcvbnm/p/13589848.html 在prometheus主程序目录下的rules目录下新建do ...
- 关闭You have new mail in /var/spool/mail/root提醒
echo "unset MAILCHECK">> /etc/profile #以root权限执行 或者用sudo source /etc/profile cat /de ...
- vue中修改滚动条样式
这是一个在VUE中的设置滚动条样式的方法,该方法只适用于Chrome浏览器,亲测在火狐不适用 样式写在 APP.vue 中,可以用在全局,如果只用在那个盒子中,只需要在::前面加上盒子的class名就 ...
- 适用于移动端、PC 端 Vue.js 图片预览插件
1.安装:npm install --save vue-picture-preview 2.使用: (1)入口文件中main.js中全局引入: import Vue from 'vue' import ...
- day46-JDBC和连接池02
JDBC和连接池02 3.ResultSet[结果集] 基本介绍 表示数据库结果集的数据表,通常通过执行查询数据库的语句生成 ResultSet对象保持一个光标指向其当前的数据行,最初,光标位于第一行 ...
- Linux家族谱系
I II III VI unix linux Redhat Centos Debian Ubuntu SUSE Android BSD freeBSD NetBSD openBSD ...
- 题解 CF803A Maximal Binary Matrix
Luogu codeforces 前言 模拟赛原题.. 好好一道送分被我硬打成爆蛋.. \(\sf{Solution}\) 看了一波数据范围,感觉能 dfs 骗分. 骗成正解了. 大概就是将这个 \( ...
- 三、Kubernetes调度
一.Kubernetes调度 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: 公平:如何保证每个节点都 ...
- 物理服务器做系统盘centos
linux系统跟windows系统都是操作系统的一种,安装的方法也较多,一样可以通过制作u盘启动盘给linux系统安装.那么具体是如何安装linux?下面就给大家演示下u盘启动盘安装linux系统教程 ...
- mybatis-自定义映射resultMap
自定义映射resultMap resultMap处理字段和属性的映射关系 resultMap:设置自定义映射 属性: id:表示自定义映射的唯一标识,不能重复 type:查询的数据要映射的实体类的类型 ...