数据预处理:标准化(Standardization)
注:本文是人工智能研究网的学习笔记
常用的数据预处理方式
- Standardization, or mean removal and variance scaling
- Normalization: scaling individual to have unit norm
- Binarization: thresholding numerical features to get boolean values
- Encoding categorical feature
- Imputation of missing values
- Generating polynominal features
- Custom transformers
标准化(Standardization)
对sklearn中的很多机器学习算法,他们都有一个共同的要求:数据集的标准化(Standardization)。如果数
据集中某个特征的取值不服从保准的正态分布(Gaussian with zero mean and unit variance),则他们的
性能就会变得很差。
在实践中,我们经常忽略分布的形状(shape of the distribution)而仅仅通过除每个特征分量的均值
(Mean Removal)将数据变换到中心,然后通过除以特征分量的标准差对数据进行尺度缩放(variance scaling)。
举例来说,在学习器的目标函数中用到的很多元素(SVM中的RBF核函数,或线性代数中的L1和L2正则化)都假定了
所有特征分布在0周围而且每个分量的方差都差不多大。如果一旦某个特征分量的方差幅度远大于其他特征分量的
方差幅度,那么这个大方差特征分量将会主导目标函数的有优化过程,使得学习器无法正确的从其他特征上学习。
from sklearn import preprocessing
import numpy as np
X = np.array([[1, -1, 2], [2, 0, 0], [0, 1, -1]])
X_scaled = preprocessing.scale(X)
X_scaled
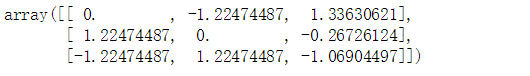
尺度调整之后的数据有0均值和单位方差(==1):
print(X_scaled.mean(axis=0))
print(X_scaled.std(axis=0))

Preprocessing模块进一步提供了一个类StandardScaler,该类实现了变换器(Transformer)的API用于
计算训练数据集的均值和标准差。然后将此均值与标准差用到对测试数据集的变换操作中去。所以这个标准化
的过程应该被应用到sklearn.pipeline.Pipeline的早期阶段。
scaler = preprocessing.StandardScaler().fit(X)
print(scaler)
print('--------')
print(scaler.mean_)
print('--------')
print(scaler.transform(X))

在上面的代码中,scaler实例已经训练完成,就可以再用来对新的数据执行在训练集上同样的变换操作。

我们还可以使用参数来进一步的自定义,with_mean=False, with_std=False来不去使用中心化和规模化。
把特征变换到指定范围内(Scaling feature to a range)
另外一种标准化是把特征的取值变换到指定的最小值和最大值之间,通常是[0,1]区间或每个特征分量的最大绝对值
被缩放为单位值,这样的变换可以使用MinMaxScaler或者MaxAbsScaler。
X_train = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_train_minmax

上面X_train上训练好的MinMaxScaler就可以通过transform函数被用到新的数据上,同样的缩放和平移操作被用到测试数据集
X_test = np.array([[-3., -1.,4. ]])
X_test_minmax = min_max_scaler.transform(X_test)
X_test_minmax

还可以通过MinMaxScaler对象的属性来获得在训练集上学习到的变换函数。
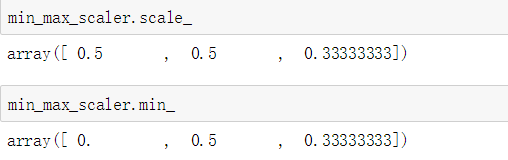
如果给MinMaxScaler对象一个显式的区间范围feature_range=(min,max),则其变换过程如下。
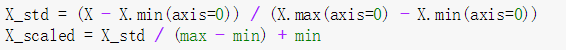
MaxAbsScaler的工作方式与MinMaxScaler很相似,但是其变换方式是让训练数据处于区间[-1,1]。这可以通过把每个特征分量除以其对应的最大值来做到。这种变换要求数据集已经被中心化到0或者是稀疏数据。
X_train = np.array([[1., -1., 2.],
[2., 0., 0. ],
[0., 1., -1.]])
max_abs_scaler = preprocessing.MaxAbsScaler()
X_train_maxabs = max_abs_scaler.fit_transform(X_train)
print(X_train_maxabs)
print('-------')
X_test = np.array([[-3., -1., 4.]])
X_test_maxabs = max_abs_scaler.transform(X_test)
print(X_test_maxabs)
print('-------')
print(max_abs_scaler.scale_)

缩放稀疏数据(Scaling sparse data)
中心化稀疏数据(Centering sparse data)将会破坏数据的稀疏型结构,因此很少这么做。然而,我们可以对稀疏的输入进行缩放(Scale sparse inputs),尤其是特征分量的尺度不一样的时候。
MaxAbsScaler和maxabs_scale都进行了一些特别的设计专门用于变换稀疏数据,是推荐的做法。
scale和StandardScaler也可以接受scipy.sparse矩阵作为输入,只要参数with_mean=False被显式的传入构造器就可以了,否则,会产生ValueErroe。
RobustScaler不能接受稀疏矩阵,但是你可以在稀疏输入上使用transform方法。
注意:变换器接受Compressed Sparse Rows和Compressed Sparse Columns格式(scipy.sparse.csr_marxi和scipy.sparse.csc_matrix)。其他任何的稀疏输入会被转换成Compressed Sparse Rows,为了避免不必要的内存拷贝,推荐使用CSR和CSC。最后,如果你的稀疏数据比较小,那么可以使用toarray方法吧稀疏数据转换成Numpy array。
Scaling data with outliers
如果数据中有很多的outliers(明显的噪点),均值和方差的估计就会有问题,所以使用均值和方法的数据集也会偶遇问题。
在这种情况下,可以使用robust_scale和RobustScaler,他们使用了更加鲁棒的方式来估计数据中心和范围。
数据预处理:标准化(Standardization)的更多相关文章
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- Python数据预处理—归一化,标准化,正则化
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常用的 ...
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并处以其方差.得到的结果是,对于每个属 ...
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并处以其方差.得到的结果是,对于每个属 ...
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并除以其方差.得到的结果是,对于每个属 ...
随机推荐
- Pythagorean Triples(Codeforces Round #368 (Div. 2) + 构建直角三角形)
题目链接: https://codeforces.com/contest/707/problem/C 题目: 题意: 告诉你直角三角形的一条边,要你输出另外两条边. 思路: 我们容易发现除2外的所有素 ...
- Django连接mysql常见错误
1045, "Access denied for user 'root'@'localhost' (using password: YES)" 数据库的密码或用户名不对,查看set ...
- CSS基础之选择器
一:CSS介绍 CSS(Cascading Style Sheet,层叠样式表)定义如何显示HTML元素. 当浏览器读到,一个样式表时,就会按照. 二:CSS语法 每个CSS有两部分组成:选择器和声明 ...
- D. Sum in the tree(树形+贪心)
题目链接;http://codeforces.com/contest/1099/problem/D 题目大意:给出一棵树,每个节点到根节点的路径上经过的所有点的权值之和,其深度为偶数的节点的信息全部擦 ...
- 修复TortoiseGit文件夹和文件图标不显示问题的多种解决办法以及重启之后TortoiseGit图标注册表又不见了的解决办法
一 首先进行第一种尝试 打开 regedit.exe ,准备修改注册表 找到 HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\ ...
- 聊天室(上篇)GatewayWorker 基础
前言 本文的目的是基于 GatewayWorker 官方手册,梳理一次 GatewayWorker,并在实践中与 MVC 框架整合的思路(附最终的项目源码).如果你已经理解了整合这一块儿的知识,那么就 ...
- 【Linux】Linux基本命令扫盲【转】
转自:http://www.cnblogs.com/lcw/p/3762927.html [VI使用] 1.在命令行模式 :在vi编辑器中将光标放在函数上,shift + k 可直接man手册 ...
- mysql -> 启动&多实例_03
常用的连接方式: 套接字: mysql -uroot -p123 -S /application/mysql/tmp/mysql.sock Tcp/Ip: mysql -uroot -p123 -h ...
- SpringCloud常用注解
一 @EnableDiscoveryClient,@EnableEurekaClient的区别 SpringCLoud中的“Discovery Service”有多种实现,比如:eureka, con ...
- Token机制,防止web页面重复提交
1.业务要求:页面的数据只能被点击提交一次 2.发生原因: 由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交 3.解决办法: 集群环境:采用token加redis(redis单线 ...