孤的Scrapy官文阅读进程
上月底开始学习Scrapy爬虫框架,看了一些中文文档,讲应用、讲基础的,对其有一些了解了。终于在28日打开Scrapy的官网,并制作了其文档的思维导图,进而开启了其文档的阅读之旅。
本文展示了从6月28日到7月3日每天阅读过的Scrapy文档,记录其整个过程和读后感。
不过,这是第一次做这样的记录,目的是想完整地学习Scrapy,要是可行、高效,后续可以应用到其它方面。
阅读过程
颜色变化表示当天阅读。
-6月28日
-6月29日
-6月30日
-7月1日
-7月2日
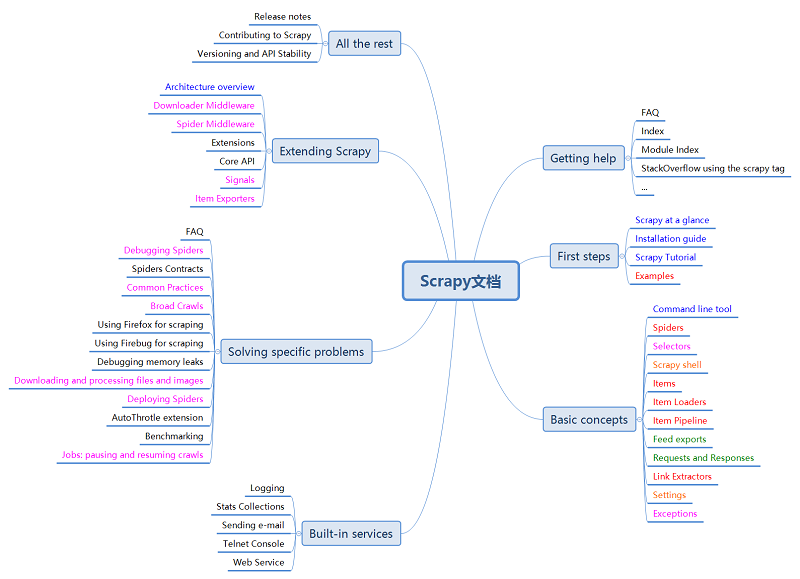
-7月3日
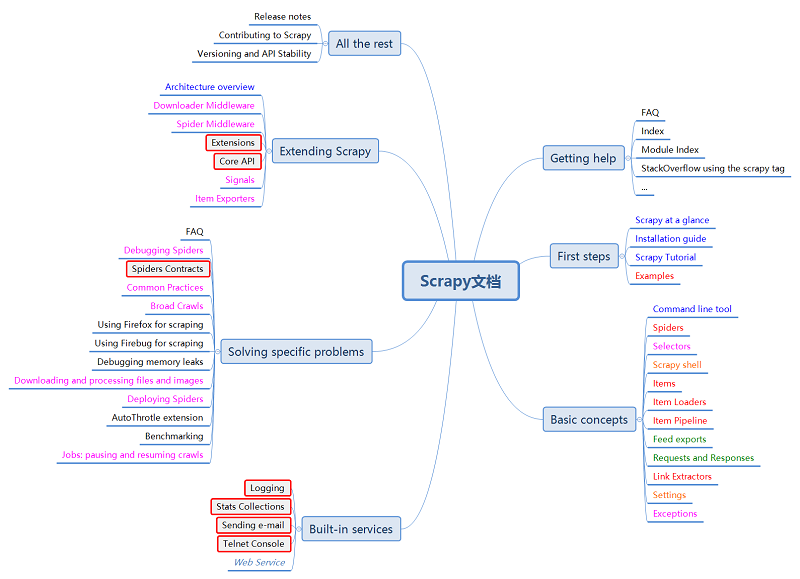
6天,可以说大部分文档都读过了吧,期间也有一些简单的练手。其中,前面阅读速度较慢——有很多东西都需要斟酌,后面的7月2日、3日读的就比较快了,一咬咬牙,文档就读完了。
读后感
1.学习新的东西,开始都会比较慢,也会比较难——因为有很多新【知识点】,而后面因为对相关新【知识点】了解的多了、透了,阅读效率也就提高了;
2.学习新的东西,并不是一下子、一小时、一天就可以学到的,它需要更多的时间 和 耐心,否则,开始的艰难期会容易产生负面情绪,比如,烦躁,这样就很难真正地学好新的东西了,淡定点,慢慢来会比较快(歌名吗)?
3.英文能力需要提高,阅读IT类文档的水平也需要提高,涉及到两个方面——英文阅读硬实力和对IT技术的理解,怎么提高呢?目前孤的想法是,多读英文技术文档,熟能生巧,经常接触的话,可以增加自己的熟悉感,负面情绪会少很多,甚至没有;多看看英文网站,没事时就背背单词、听听英文听力,当然,这都需要时间;另外,多这样学习几次就好勒,GitHub要常用;这是长期任务;
4.学习 还得和 练习、复习(包括总结)搭配才好;比如本次阅读Scrapy文档,虽然6天时间阅读完了,但练习的比较少,加上理解的一些问题,其实自己现在并不能说是完全掌握Scrapy,还差得远呢;复习,在阅读文档期间就相当于重复看文档,找到其中【不理解的】地方,再次投入精时去理解,这也是需要总结的,什么地方学透了,什么地方没有,自己心中要有数,知道继续攻坚克难的方向;
5.Scrapy的文档更多是技术性的,对于实际的应用,比如,孤想爬取微博、博客园、知乎的内容,帮助并不是很“直接”,这个或许要自己去dig,当然,多看看其它技术博文——取经、站在他人的肩膀上;
6.学习的最终目的是什么呢?灵活运用、学以致用(开发应用、系统、平台)、融会贯通,不外乎此三条吧!嗯,谋生(赚钱)、干事,嘿!
7.接下来,练习、使用、总结、提高,开发几个应用出来!
8.Scrapy文档或许缺少更实际的项目应用,需要dig!
9.坚持写技术博文,样式更美观大方的博文、对读者更有用的博文、对自己整理知识体系更有用的博文!赏心悦目!
一些疑问
疑问1,
Scrapy项目上线后,怎么检测到 源站点 的网页结构发生变化了呢,并及时开发相关人员 进行更新?
变化可能包括:
1.页面结构变化,改版了;
2.验证方式改变,新的验证码;
3.其它;
疑问2,
很多站点会禁止爬虫程序爬取数据,虽然可以突破robots.txt协议,但是,是否可以更道德一些呢?和站点签订协议,付费爬取数据(也可能是对方提供数据接口(API))?
疑问3,
哪些站点是可以爬取数据的?哪些站点是不可以的?仅仅根据robots.txt的规则怕是不够的吧?怎么做到合理、合法?对哦,爬取网站数据不会犯法吧?
疑问4,
Scrapy官文没有介绍怎么突破JavaScript脚本验证、跳转(微博遇到),应该是需要其它工具来做这件事情吧!看过其它的一些文档,提到过洋葱路由器(TOR)、Selenium、PhantomJS等,还需dig。
疑问5,
爬取那么多数据,哪些是有用的呢?或许,做爬虫的公司是知道的,或许,自己摸索久了也就知道了!
继续探索!
孤的Scrapy官文阅读进程的更多相关文章
- Scrapy官网程序执行示例
Windows 10家庭中文版本,Python 3.6.4,Scrapy 1.5.0, Scrapy已经安装很久了,前面也看了不少Scrapy的资料,自己尝试使其抓取微博的数据时,居然连登录页面(首页 ...
- Spring官网阅读(十七)Spring中的数据校验
文章目录 Java中的数据校验 Bean Validation(JSR 380) 使用示例 Spring对Bean Validation的支持 Spring中的Validator 接口定义 UML类图 ...
- Linux 源码阅读 进程管理
Linux 源码阅读 进程管理 版本:2.6.24 1.准备知识 1.1 Linux系统中,进程是最小的调度单位: 1.2 PCB数据结构:task_struct (Location:linux-2. ...
- Spring官网阅读 | 总结篇
接近用了4个多月的时间,完成了整个<Spring官网阅读>系列的文章,本文主要对本系列所有的文章做一个总结,同时也将所有的目录汇总成一篇文章方便各位读者来阅读. 下面这张图是我整个的写作大 ...
- Spring官网阅读(十八)Spring中的AOP
文章目录 什么是AOP AOP中的核心概念 切面 连接点 通知 切点 引入 目标对象 代理对象 织入 Spring中如何使用AOP 1.开启AOP 2.申明切面 3.申明切点 切点表达式 excecu ...
- Spring官网阅读(十六)Spring中的数据绑定
文章目录 DataBinder UML类图 使用示例 源码分析 bind方法 doBind方法 applyPropertyValues方法 获取一个属性访问器 通过属性访问器直接set属性值 1.se ...
- Spring官网阅读(三)自动注入
上篇文章我们已经学习了1.4小结中关于依赖注入跟方法注入的内容.这篇文章我们继续学习这结中的其他内容,顺便解决下我们上篇文章留下来的一个问题-----注入模型. 文章目录 前言: 自动注入: 自动注入 ...
- Google Android官方文档进程与线程(Processes and Threads)翻译
android的多线程在开发中已经有使用过了,想再系统地学习一下,找到了android的官方文档,介绍进程与线程的介绍,试着翻译一下. 原文地址:http://developer.android.co ...
- Spring官网阅读(十一)ApplicationContext详细介绍(上)
文章目录 ApplicationContext 1.ApplicationContext的继承关系 2.ApplicationContext的功能 Spring中的国际化(MessageSource) ...
随机推荐
- 洛谷 P4128 [SHOI2006]有色图 解题报告
P4128 [SHOI2006]有色图 题目描述 如果一张无向完全图(完全图就是任意两个不同的顶点之间有且仅有一条边相连)的每条边都被染成了一种颜色,我们就称这种图为有色图.如果两张有色图有相同数量的 ...
- Ansible基础概述
一.Ansible简介 Ansible基于Python语言实现,由paramiko和PyYAML两个关键模块构建.Ansible的编排引擎可以出色地完成配置管理,流程控制,资源部署等多方面工作.Ans ...
- Java的内存结构
Java中的内存结构 运行时数据区域的划分: 程序计数器(PC寄存器) 程序计数器(Program Counter Register)是一块较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器 ...
- android studio gradle dependencies 包存放在哪儿?
在AndroidStudio中的"External Libraries"下有引用的library的列表, 选择某个library右键->"Library Prope ...
- bzoj : 4504: K个串 区间修改主席树
4504: K个串 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 268 Solved: 110[Submit][Status][Discuss] ...
- 【纪中集训2019.3.12】Z的礼物
题意 已知\(a_{i} = \sum_{j=1}^{i} \{^{i} _{j} \}b_{j}\), 给出\(a_{1} 到 a_{n}\) : 求\(b_{l} 到 b_{r}\)在\(1e9+ ...
- React-Router 动画 Animation
React-Router动画实际上和React动画没什么区别,都是使用 'react-addons-css-transition-group' 这个组件:但是,和普通的 React-Router 的 ...
- CentOS 6.6搭建LNMP环境
一.安装前 1.关闭linux的安全机制 vim /etc/selinux/config SELINUX=enforcing 改为 SELINUX=disabled 2.关闭iptables防火墙 ...
- bzoj 刷题计划~_~
bzoj 2818 两个互质的数的gcd=1,所以他们同时乘一个素数那么他们的gcd=这个素数,所以枚举素数p找n/p以内有多少对互质数,用欧拉函数. bzoj 2809 可并堆,对于每一个子树显然是 ...
- 利用Azure Media Services Explorer发布VOD视频
1.连接Media Services账号, 填入Media Services的账号以及Account Key 如果使用中国的Azure的话,需要在Endpoint节上更改一下,因为国内的Azure的接 ...