PGM学习之二 PGM模型的分类与简介
废话:和上一次的文章确实隔了太久,希望趁暑期打酱油的时间,将之前学习的东西深入理解一下,同时尝试用Python写相关的机器学习代码。
一 PGM模型的分类
通过上一篇文章的介绍,相信大家对PGM的定义和大致应用场景有了粗略的了解。那么接下来我们来深入了解下PGM。
首先要介绍的是Probabilistic models(概率模型),常用来描述不同的随机变量之前的关系,主要针对变量或变量间的相互不确定性的概率关系建模。总的来说,概率模型分为两类:
一类是参数模型-可以用有限个参数进行准确定义
参数模型是一组由有限维参数构成的分布集合
。其中
是参数,而
是其可行欧几里得子空间。概率模型可被用来描述一组可产生已知采样数据的分布集合。例如,假设数据产生于唯一参数的高斯分布,则我们可假设该概率模型为
。
二类是非参数模型-即无法采用有限参数进行准确定义的模型
无参数模型则是一组由无限维参数构成的概率分布函数集合,可被表示为
。相比于无参数模型和参数模型,半参数模型也由无限维参数构成,但其在分布函数空间内并不紧密。例如,一组混叠的高斯模型。确切的说,如果
是参数的维度,
是数据点的大小,如果随着
和
则
,则我们称之为半参数模型。
概率模型是所有数理统计问题的前提,选择合适的概率模型对于解决实际问题具有非常重要的意义。在选择模型时,需要考虑以下以及各因素:
- 所研究的随机现象的基本概率特征, 例如: 对称性, 矩条件
- 描述随机现象的随机变量是连续随机变量还是离散随机变量, 或者相关随机变量是否具有混合概率分布等复杂分布形式
- 对于参数模型, 问题的参数分布族是具有什么形式, 参数空间的选择
- 解决问题所要用到的统计量, 以及相应的假设检验方法
PGM即是概率模型的一种,通过利用有向图或者无向图来表示变量之前的概率关系,我们可以将复杂的概率模型转换为纯粹的代数运算。常见的PGM的分类如下图所示:

二 PGM模型中Factor的理解与运算
在进一步理解如此众多的PGM模型前,我们首先来回忆一下有关PGM中factors的知识。Factors可以叫做影响因子,在一个PGM模型中,一个Factor可以看做Graph中的一个节点;两个Factor之间的联系用图的边来表示。在PGM中,Factor是在高维空间中定义概率分布的基础和原子;在Factor上定义的操作是概率分布公式推导的基础。在由两个Factor构成的最简单的有向图的PGM模型里,Factor与概率的转化关系如下图所示:

简单的说,一个PGM模型最终可以建模表示成图中所有Factor的联合概率分布,然后根据Factor之间的运算规则,可以将该联合概率分布转化为可运算的概率分布的乘积。
如上图所示,Factor1有箭头指向Factor2,表示Factor1是Factor2的条件,那么P(Factor2)=P(Factor2|Factor1)。这种箭头表示的是Factor之间的联系,在有向图PGM模型中,若干个Factor和若干条箭头之间,Factor之间的相互影响,可以用Chain Rules(链式法则)来表示。那么接下来,我们来理解一下什么是Chain Rules。

上图中,P(G,D,I,S,L)是图右侧所示有向PGM模型的联合概率分布。在该模型中,Grade受Course Difficulty和Student Intelligence的影响;SAT受Student Intelligence的影响;Reference Letter受Grade的影响。
根据前述的运算规则,有:P(D,I,G,S,L)=P(D)*P(I)*P(G|I,D)*P(L|G)*P(S|I),也就是说,PGM模型的所有因子的联合概率分布,等于各因子概率的乘积。那么,如何根据各因子的概率分布计算PGM模型所代表的联合概率分布呢?以最简单的离线分布为例:

图中给出了每一个因子的分布,同时我们还知道:P(D,I,G,S,L)=P(D)*P(I)*P(G|I,D)*P(L|G)*P(S|I)。接下来我们计算联合概率分布:
P(D=0,I=1,G=3,S=1,L=1)=P(D=0)*P(I=1)*P(G=3|I=1,D=0)*P(L=1|G=3)*P(S=1|I=1)
=0.6*0.3*P(G=3|I=1,D=0)*P(L=1|G=3)*P(S=1|I=1)
=0.6*0.3*0.7*0.01*0.8
此外,在实际应用过程中,还将出现求两个联合概率分布乘积的情况。依旧以离散概率分布为例:

上图给出了两个联合概率分布的运算法则:
P(A,B,C)=P(A,B)*P(B,C)
三 贝叶斯网络的定义
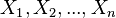 }及其n组条件概率分配(conditional probability distributions, or CPDs)的性质。举例而言,贝叶斯网络可用来表示疾病和其相关症状间的概率关系;倘若已知某种症状下,贝叶斯网络就可用来计算各种可能罹患疾病之发生概率。
}及其n组条件概率分配(conditional probability distributions, or CPDs)的性质。举例而言,贝叶斯网络可用来表示疾病和其相关症状间的概率关系;倘若已知某种症状下,贝叶斯网络就可用来计算各种可能罹患疾病之发生概率。
一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,抑或是隐变量、未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系或是非条件独立的;而节点中变量间若没有箭头相互连接一起的情况就称其随机变量彼此间为条件独立。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(descendants or children)”,两节点就会产生一个条件概率值。
令G = (I,E)表示一个有向无环图(DAG),其中I代表图形中所有的节点的集合,而E代表有向连接线段的集合,且令X = (Xi)i ∈ I为其有向无环图中的某一节点i所代表之随机变量,若节点X的联合概率分配可以表示成:
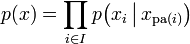
则称X为相对于一有向无环图G 的贝叶斯网络,其中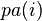 表示节点i之“因”。
表示节点i之“因”。
对任意的随机变量,其联合分配可由各自的局部条件概率分配相乘而得出:
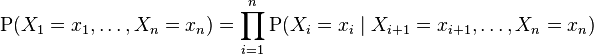
依照上式,我们可以将一贝叶斯网络的联合概率分配写成:
-
 , 对每个相对于Xi的“因”变量Xj 而言)
, 对每个相对于Xi的“因”变量Xj 而言)
上面两个表示式之差别在于条件概率的部分,在贝叶斯网络中,若已知其“因”变量下,某些节点会与其“因”变量条件独立,只有与“因”变量有关的节点才会有条件概率的存在。这就是后面我们要重点理解的,影响因子的推理规则。
PGM学习之二 PGM模型的分类与简介的更多相关文章
- WEB框架-Django框架学习(二)- 模型层
今日份整理为模型层 1.ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库, ...
- 性能测试学习之二 ——性能测试模型(PV计算模型)
PV计算模型 现有的PV计算公式是: 每台服务器每秒平均PV量 =( (总PV*80%)/(24*60*60*40%))/服务器数量 =2*(总PV)/* (24*60*60) /服务器数量 通过定积 ...
- Spring学习(二)Spring IoC 和 DI 简介
一.IOC(控制反转) 定义:反转控制 (Inversion Of Control)的缩写,即创建对象的反转控制. 正向控制:若要使用某个对象,需要自己去负责对象的创建. 反向控制:若要使用某个对象, ...
- 性能测试学习之三—— PV->TPS转换模型&TPS波动模型
PV->TPS转换模型 由上一篇“性能测试学习之二 ——性能测试模型(PV计算模型)“ 得知 TPS = ( (80%*总PV)/(24*60*60*(T/24)))/服务器数量 转换需要注意: ...
- PGM学习之七 MRF,马尔科夫随机场
之前自己做实验也用过MRF(Markov Random Filed,马尔科夫随机场),基本原理理解,但是很多细节的地方都不求甚解.恰好趁学习PGM的时间,整理一下在机器视觉与图像分析领域的MRF的相关 ...
- PGM学习之一
一 课程基本信息 本课程是由Prof.Daphne Koller主讲,同时得到了Prof. Kevin Murphy的支持,在coursera上公开传播.在本课程中,你将学习到PGM(Probabil ...
- Factorization Machines 学习笔记(二)模型方程
近期学习了一种叫做 Factorization Machines(简称 FM)的算法,它可对随意的实值向量进行预測.其主要长处包含: 1) 可用于高度稀疏数据场景:2) 具有线性的计算复杂度.本文 ...
- 机器学习-学习笔记(二) --> 模型评估与选择
目录 一.经验误差与过拟合 二.评估方法 模型评估方法 1. 留出法(hold-out) 2. 交叉验证法(cross validation) 3. 自助法(bootstrapping) 调参(par ...
- 机器学习&数据挖掘笔记_21(PGM练习五:图模型的近似推理)
前言: 这次练习完成的是图模型的近似推理,参考的内容是coursera课程:Probabilistic Graphical Models . 上次实验PGM练习四:图模型的精确推理 中介绍的是图模型的 ...
随机推荐
- .net mvc中session的锁机制
今天遇到个奇怪的问题, 一个秒杀商品系统, 大量秒杀请求进来, 到了action居然是单线程执行! 这样产生的效果就是“这个系统好慢啊!!”. 可是我没有加lock,为什么会变成单线程执行呢? 找资料 ...
- 把模块有关联的放在一个文件夹中 在python2中调用文件夹名会直接失败 在python3中调用会成功,但是调用不能成功的解决方案
把模块有关联的放在一个文件夹中 在python2中调用文件夹名会直接失败在python3中调用会成功,但是调用不能成功 解决办法是: 在该文件夹下加入空文件__init__.py python2会把该 ...
- JavaWeb项目学习教程(2) 系统数据库设计
最开始本来想写一个管理系统,因为考虑到期末来临,我女朋友就可以看着教程然后学一些东西,然后可以自己慢慢手敲代码.但无奈自己也太懒,两个月过后,我才开始继续写这个博客,而现在我都已经开学了.不过博客还是 ...
- selenium 基本常用操作
from selenium import webdriverfrom selenium.webdriver.common.action_chains import ActionChains #鼠标操作 ...
- 从一个简单的寻路问题深入Q-learning
这第一篇随笔实际上在我的科学网博客上是首发,我重新拿到博客园再发一次是希望以此作为我学习Q-learning的一个新的开始.以后这边主技术,科学网博客主理论.我也会将科学网那边技术类的文章转过来的.希 ...
- 获400 万美元 A 轮融资,ShipBob 想帮助小微企业享受Amazon Prime 级配送服务 2016-06-18
Weiss认为,无论零售市场的发展走向如何波动,ShipBob公司都能够获得坚实的成长表现. 在线销售实体商品的小型企业当然希望利用种种方式取悦客户,但面对着Amazon Prime迅如闪电且价格实惠 ...
- killall命令详解
基础命令学习目录首页 原文链接:https://blog.csdn.net/tanga842428/article/details/52474250 Linux系统中的killall命令用于杀死指定名 ...
- 查看jdk使用的是什么垃圾收集器
一.方法一 打印虚拟机所有参数 [root@localhost ~]# java -XX:+PrintFlagsFinal -version | grep : uintx InitialHeap ...
- 学习记录 div悬停在顶部 。div阻止冒泡
如何让一个div可点击,并且div里面的a元素也能点击? 楼主应该是想要这样的,阻止事件冒泡 点击里面的a的时候不触发外面的div的点击事件 <script type="text/ja ...
- 互评Alpha版本—SkyHunter
1.根据NABCD评论作品: N(Need,需求):飞机大战题材的游戏对80,90后的人来说算是童年的记忆,可以在闲暇之余打开电脑玩一会儿.但是面向初中生,高中生的话这种PC小游戏可能不会那么适合 ...