KVM,QEMU,libvirt入门学习笔记【转】
转自:http://blog.csdn.net/julykobe/article/details/27571387
注:本文内容均来自网络,我只是在此做了一些摘抄和整理的工作,来源均有注明。
0、虚拟化
虚拟化简介
我们首先简要介绍一下虚拟化,阐述 QEMU 的搭建背景。
本文中介绍的虚拟化实际上指的是平台虚拟化。在物理硬件上,控制程序可能是主机操作系统或管理程序(见图 1)。在某些情况下,主机操作系统就是管理程序。来宾操作系统位于管理程序中。在某些情况下,来宾操作系统与控制程序使用相同的 CPU,而在另外一些情况下,则可能不同(比如 PowerPC
来宾操作系统在 x86 硬件上运行)。
图 1. 平台虚拟化的基本架构

您可以通过多种方法实现虚拟化,但是最常见的有三种。第一种称为本地虚拟化(或全虚拟化)。在这种虚拟化中,管理程序实现基本的隔离元素,将物理硬件与来宾操作系统相分离。这种技术首次出现于 1966 年 IBM® CP-40 虚拟机/虚拟内存操作系统中,另外 VMware ESX Server
也使用了此技术。
另一种流行的虚拟化技术称为半虚拟化。在半虚拟化中,控制程序实现了管理程序的应用程序接口(API),它将由来宾操作系统使用。Xen 和 Linux Kernel-based Virtual Machine (KVM) 都使用了半虚拟化技术。
第三种有用的技术称为仿真。仿真,顾名思义,通过模拟完整的硬件环境来虚拟化来宾平台。仿真可通过多种方法实现,即使在同一个解决方案中也是如此。通过仿真实现虚拟化的技术有 QEMU 和 Bochs。
1、KVM
KVM是Kernel-based Virtual Machine的缩写。从Linux kernel 2.6.20开始就包含在Linux内核代码之中,使用这个或者更高版本内核的Linux发行版,就直接可以使用KVM。KVM依赖于host
CPU的虚拟化功能的支持(Intel-VT & AMD-V),类似于Xen的HVM,对于guest OS的内核没有任何的要求,可以直接支持创建Linux和Windows的虚拟机。
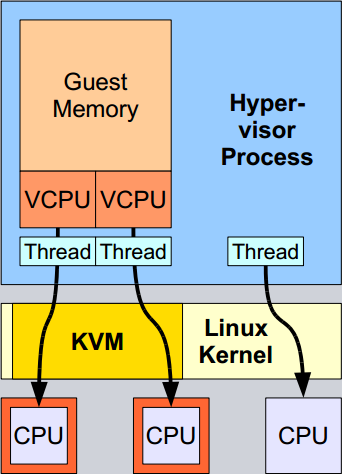
RAM的地址空间映射到qemu-kvm进程的内存地址空间,这样进程就可以很容易的对于guest
OS的RAM进行控制,当guest需要使用RAM时,qemu-kvm就在自己的进程内存空间中划分一段给guest用。对于guest
OS设置了MaxMemory和CurrentMemory之后,guest
OS的RAM上限也就有了,就是MaxMemory,如果当前的guest实际使用不了那么多RAM,就可以将CurrentMemory调小,将多余的内存还给host,guest中看到的内存大小就是CurrentMemory,这就是Memory
Balloon特性。

Machine Monitor),并且在原有Linux操作系统两种执行模式(用户模式和内核模式)的基础上,增加了一种客户模式(拥有自己的内核模式和用户模式),这三种模式不同的分工分别是:
OS,把底层的Linux操作系统称为Host OS。在KVM模型中,每一个Guest
OS对Linux来说是一个标准的进程,可以使用Linux的进程管理指令管理,例如用taskset指定运行于某个特定的CPU,也可以用kill终止虚拟机的运行。

OS发生外部中断或者影子页表缺页之类的事件,暂停Guest OS的运行,退出客户模式进入内核做一些必要的处理,而后重新进入客户模式。继续执行客户代码;如果发生I/0事件或者信号队列中有信号到达,就会进入用户模式处理。
2、QEMU
刚才讲KVM的时候一直说进程可以通过KVM模块创建虚拟机,那个所谓的进程其实就是QEMU。KVM团队维护了一个QEMU的分支版本(qemu-kvm),使QEMU可以利用KVM在x86架构上加速,提供更好的性能。qeum-kvm版本的目标是将所有的特性都合入上游的QEMU版本,之后这个版本会废弃,直接使用QEMU主干版本。
OS的性能要优于qemu;qemu配置项指的就是完全的QEMU虚拟化,没有硬件加速,主要用于比较老式的CPU和操作系统环境,或者是在虚拟机中创建虚拟机的情况,当然完全的QEMU虚拟化性能要比qemu-kvm差一些。
- 模拟(emulator)
- 虚拟化(virtualizer)
模拟:就是在一种CPU架构上模拟另一种CPU架构,运行程序。例如:在x86环境上模拟ARM的运行环境,执行ARM程序,或者在PowerPC环境上模拟x86指令集。
虚拟化:就是在host OS上运行guest OS的指令,并为guest OS提供虚拟的CPU、RAM、IO和外围设备。
ioctl(KVM_RUN)switch (exit_reason) {case KVM_EXIT_IO: /* ... */case KVM_EXIT_HLT: /* ... */}
109 1673 1 1 May04 ? 00:26:24 /usr/bin/qemu-system-x86_64 -name instance-00000002 -S -machine pc-i440fx-trusty,accel=tcg,usb=off -m 2048 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid f3fdf038-ffad-4d66-a1a9-4cd2b83021c8 -smbios type=1,manufacturer=OpenStack Foundation,product=OpenStack Nova,version=2014.2,serial=564d2353-c165-6238-8f82-bfdb977e31fe,uuid=f3fdf038-ffad-4d66-a1a9-4cd2b83021c8 -no-user-config -nodefaults -chardev socket,id=charmonitor,path=/var/lib/libvirt/qemu/instance-00000002.monitor,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc -no-shutdown -boot strict=on -device piix3-usb-uhci,id=usb,bus=pci.0,addr=0x1.0x2 -drive file=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none -device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1 -drive file=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/disk.config,if=none,id=drive-ide0-1-1,readonly=on,format=raw,cache=none -device ide-cd,bus=ide.1,unit=1,drive=drive-ide0-1-1,id=ide0-1-1 -netdev tap,fd=26,id=hostnet0 -device virtio-net-pci,netdev=hostnet0,id=net0,mac=fa:16:3e:db:86:d4,bus=pci.0,addr=0x3 -chardev file,id=charserial0,path=/opt/stack/data/nova/instances/f3fdf038-ffad-4d66-a1a9-4cd2b83021c8/console.log -device isa-serial,chardev=charserial0,id=serial0 -chardev pty,id=charserial1 -device isa-serial,chardev=charserial1,id=serial1 -vnc 127.0.0.1:1 -k en-us -device cirrus-vga,id=video0,bus=pci.0,addr=0x2 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5QEMU 支持两种操作模式:用户模式仿真和系统模式仿真。用户模式仿真 允许一个 CPU 构建的进程在另一个 CPU 上执行(执行主机 CPU 指令的动态翻译并相应地转换 Linux 系统调用)。系统模式仿真 允许对整个系统进行仿真,包括处理器和配套的外围设备。
在 x86 主机系统上仿真 x86 代码时,使用 QEMU 加速器 可以实现近似本地的性能。这让我们能够直接在主机 CPU 上执行仿真代码(在 Linux 上通过 kernel 模块执行)。
但是从技术角度看,QEMU 的有趣之处在于其快速、可移植的动态翻译程序。动态翻译程序 允许在运行时将用于目标(来宾)CPU 的指令转换为用于主机 CPU,从而实现仿真。这可以通过一种强制方法实现(将指令从一个 CPU 映射到另一个 CPU),但是情况并非总是这样简单,在某些情况下,根据所翻译的架构,可能需要使用多个指令或行为更改。
QEMU 实现动态翻译的方法是,首先将目标指令转换为微操作。这些微操作是一些编译成对象的 C 代码。然后构建核心翻译程序。它将目标指令映射到微操作以进行动态翻译。这不仅可产生高效率,而且还可以移植。
QEMU 的动态翻译程序还缓存了翻译后的代码块,使翻译程序的内存开销最小化。当初次使用目标代码块时,翻译该块并将其存储为翻译后的代码块。 QEMU 将最近使用的翻译后的代码块缓存在一个 16 MB 的块中。 QEMU 甚至可以通过在缓存中将翻译后的代码块变为无效来支持代码的自我修改。
3、libvirt
- The KVM/QEMU Linux hypervisor
- The Xen hypervisor on Linux and Solaris hosts.
- The LXC Linux container system
- The OpenVZ Linux container system
- The User Mode Linux paravirtualized kernel
- The VirtualBox hypervisor
- The VMware ESX and GSX hypervisors
- The VMware Workstation and Player hypervisors
- The Microsoft Hyper-V hypervisor
- The IBM PowerVM hypervisor
- The Parallels hypervisor
- The Bhyve hypervisor

libvirt 比较和用例模型

图 使用 libvirtd 控制远程虚拟机监控程序
表 1. libvirt 支持的虚拟机监控程序
| 虚拟机监控程序 | 描述 |
|---|---|
| Xen | 面向 IA-32,IA-64 和 PowerPC 970 架构的虚拟机监控程序 |
| QEMU | 面向各种架构的平台仿真器 |
| Kernel-based Virtual Machine (KVM) | Linux 平台仿真器 |
| Linux Containers(LXC) | 用于操作系统虚拟化的 Linux(轻量级)容器 |
| OpenVZ | 基于 Linux 内核的操作系统级虚拟化 |
| VirtualBox | x86 虚拟化虚拟机监控程序 |
| User Mode Linux | 面向各种架构的 Linux 平台仿真器 |
| Test | 面向伪虚拟机监控程序的测试驱动器 |
| Storage | 存储池驱动器(本地磁盘,网络磁盘,iSCSI 卷) |
参考:
- Kvm Qemu Libvirt:http://kiwik.github.io/openstack/2014/05/04/KVM-QEMU-libvirt/#
- KVM虚拟机分析: http://wenku.baidu.com/link?url=1sEgxHLl-pYpSavmRJXwFq3QYHENQPvEX7QMUQ7zf9UL1Qkio1YNUVKhF-697vqk4O7DDjuEPc0NLbHfoiMbOkGo4zdmRjVjftWlkNa1AJy
- 使用QEMU进行系统仿真: https://www.ibm.com/developerworks/cn/linux/l-qemu/
- Libvirt虚拟化库剖析: https://www.ibm.com/developerworks/cn/linux/l-libvirt/
- Libvirt架构及源码分析(一) : http://blog.chinaunix.net/uid-20940095-id-3813601.html
KVM,QEMU,libvirt入门学习笔记【转】的更多相关文章
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
- PyQt4入门学习笔记(一)
PyQt4入门学习笔记(一) 一直没有找到什么好的pyqt4的教程,偶然在google上搜到一篇不错的入门文档,翻译过来,留以后再复习. 原始链接如下: http://zetcode.com/gui/ ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Scala入门学习笔记三--数组使用
前言 本篇主要讲Scala的Array.BufferArray.List,更多教程请参考:Scala教程 本篇知识点概括 若长度固定则使用Array,若长度可能有 变化则使用ArrayBuffer 提 ...
- OpenCV入门学习笔记
OpenCV入门学习笔记 参照OpenCV中文论坛相关文档(http://www.opencv.org.cn/) 一.简介 OpenCV(Open Source Computer Vision),开源 ...
- KVM+Qemu+Libvirt实战
上一篇的文章是为了给这一篇文件提供理论的基础,在这篇文章中我将带大家一起来实现在linux中虚拟出ubuntu的server版来 我们需要用KVM+Qemu+Libvirt来进行kvm全虚拟化,创建虚 ...
随机推荐
- Charles的HTTPS抓包方法及原理分析
原文地址:http://www.jianshu.com/p/870451cb4eb0 背景 作为移动平台的RD,项目开发过程中一项比较重要的甩锅技能——抓包应该大家都比较熟悉了,毕竟有些bug可能是由 ...
- Mininet 系列实验(三)
实验内容 基础 Mininet 可视化界面进行自定义拓扑及拓扑设备自定义设置,实现自定义脚本应用. 参考 Mininet可视化应用 实验环境 虚拟机: Oracle VM VirtualBox Ubu ...
- HDU.5692 Snacks ( DFS序 线段树维护最大值 )
HDU.5692 Snacks ( DFS序 线段树维护最大值 ) 题意分析 给出一颗树,节点标号为0-n,每个节点有一定权值,并且规定0号为根节点.有两种操作:操作一为询问,给出一个节点x,求从0号 ...
- HDU.1847 Good Luck in CET-4 Everybody! ( 博弈论 SG分析)
HDU.1847 Good Luck in CET-4 Everybody! ( 博弈论 SG分析) 题意分析 简单的SG分析 题意分析 简单的nim 博弈 博弈论快速入门 代码总览 //#inclu ...
- gitlab相关
1.gitlab的概述 1.gitlab是什么 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的web服务. 基础功能免费,高级功能收费 2.为什么要使用gitla ...
- Webpack 配置示例
Webpack 作为前端构建工具,对于大型网站开发,大大提升了开发效率.要使用webpack需要先安装webpack工具: 先来看一个最简单的命令 $ webpack main.js bundle.j ...
- Dubbo、Zookeeper集群搭建及Rose使用心得(一)
接触这个两三月了,是时候总结一下使用的方法以及心得体会了.我是一个菜鸟,下面写的如有错误,还请各位前辈指出.废话不多说,正式开始. 一.简介 Dubbo是Alibaba开源的分布式服务框架,它最大的特 ...
- django中的转义
什么是html转义? 所谓html转义就是将 html关键字(包括标签,特殊字符等) 进行过滤替换.过滤替换格式如下: 接下来我们通过实例演示django中转义的细节以及如何关闭转义 一 dja ...
- 科学计算三维可视化---Mlab基础(数据可视化)
推文:科学计算三维可视化---TVTK库可视化实例 使用相关函数:科学计算三维可视化---Mlab基础(管线控制函数) 一:mlab.pipeline中标量数据可视化 通过持续实例,来感受mlab对数 ...
- 基本UDP套接字编程
概述 使用TCP编写的应用程序和使用UDP编写的应用程序之间存在一些本质差异,其原因在于这两个传输层之间的差别:UDP是无连接不可靠的数据报协议,非常不同于TCP提供的面向连接的可靠字节流.然而相比T ...