Storm 第三章 Storm编程案例及Stream Grouping详解
1 功能说明
设计一个topology,来实现对文档里面的单词出现的频率进行统计。整个topology分为三个部分:
SentenceSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
SplitBolt:负责将单行文本记录(句子)切分成单词
CountBolt:负责对单词的频率进行累加
2 代码实现
package com.ntjr.bigdata; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields; public class WrodCountTopolog {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, AuthorizationException {
//使用TopologyBuilder 构建一个topology
TopologyBuilder topologyBuilder = new TopologyBuilder();
//发送英文句子
topologyBuilder.setSpout("sentenceSpout", new SentenceSpout(), 2);
//将一行行的文本切分成单词
topologyBuilder.setBolt("splitBolt", new SplitBolt(), 2).shuffleGrouping("sentenceSpout");
//将单词的频率进行累加
topologyBuilder.setBolt("countBolt", new CountBolt(), 2).fieldsGrouping("splitBolt", new Fields("word"));
//启动topology的配置信息
Config config = new Config();
//定义集群分配多少个工作进程来执行这个topology
config.setNumWorkers(3); //本地模式提交topology
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mywordCount", config, topologyBuilder.createTopology()); //集群模式提交topology
StormSubmitter.submitTopologyWithProgressBar("mywordCount", config, topologyBuilder.createTopology()); } }
WrodCountTopolog.java
package com.ntjr.bigdata; import java.util.Map; import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; public class SentenceSpout extends BaseRichSpout { private static final long serialVersionUID = 1L;
// 用来收集Spout输出的tuple
private SpoutOutputCollector collector; @Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector; } // 该方法会循环调用
@Override
public void nextTuple() {
collector.emit(new Values("i am lilei love hanmeimei"));
} // 消息源可以发送多条消息流,该方法定义输出的消息类型的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("love")); } }
SentenceSpout.java
package com.ntjr.bigdata; import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; public class SplitBolt extends BaseRichBolt { private static final long serialVersionUID = 1L; private OutputCollector collector; // 该方法只会调用一次用来执行初始化
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector; } // 接收的参数时spout发出来的句子,一个句子就是一个tuple
@Override
public void execute(Tuple input) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
collector.emit(new Values(word, 1));
} } // 定义输出类型,输出类型为单词和单词的数目和collector.emit(new Values(word, 1));对应
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num")); } }
SplitBolt.java
package com.ntjr.bigdata; import java.util.HashMap;
import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple; public class CountBolt extends BaseRichBolt { private static final long serialVersionUID = 1L;
private OutputCollector collector;
// 用来保存最后的计算结果 key:单词,value:单词的个数
Map<String, Integer> map = new HashMap<String, Integer>(); // 该方法调用一次用来执行初始化
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector; } @Override
public void execute(Tuple input) {
String word = input.getString(0);
Integer num = input.getInteger(1); if (map.containsKey(word)) {
Integer count = map.get(word);
map.put(word, count + num);
} else {
map.put(word, num);
}
System.out.println("count:" + map);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
CountBolt.java
3 执行流程图
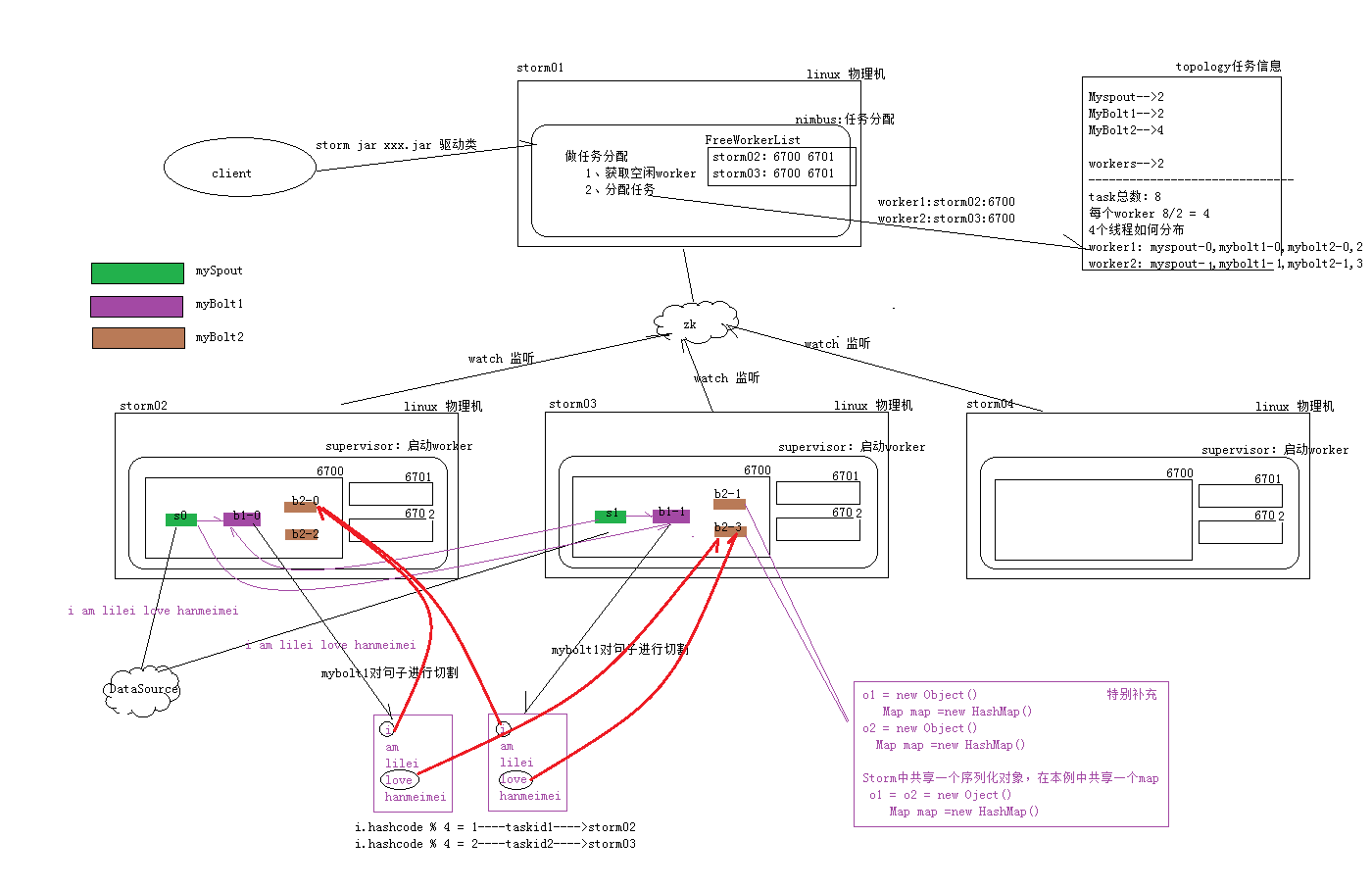
3 Stream Grouping详解
3.1 Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
3.2 Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
3.3 All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
3.4 Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
3.5 Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
3.6 Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。
消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
3.7 Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
Storm 第三章 Storm编程案例及Stream Grouping详解的更多相关文章
- Storm系列三: Storm消息可靠性保障
Storm系列三: Storm消息可靠性保障 在上一篇 Storm系列二: Storm拓扑设计 中我们已经设计了一个稍微复杂一点的拓扑. 而本篇就是在上一篇的基础上再做出一定的调整. 在这里先大概提一 ...
- Objective-C 基础教程第三章,面向对象编程基础知
目录 Objective-C 基础教程第三章,面向对象编程基础知 0x00 前言 0x01 间接(indirection) 0x02 面向对象编程中使用间接 面向过程编程 面向对象编程 0x03 OC ...
- Java程序设计(2021春)——第一章课后题(选择题+编程题)答案与详解
Java程序设计(2021春)--第一章课后题(选择题+编程题)答案与详解 目录 Java程序设计(2021春)--第一章课后题(选择题+编程题)答案与详解 第一章选择题 1.1 Java与面向对象程 ...
- Java程序设计(2021春)——第二章课后题(选择题+编程题)答案与详解
Java程序设计(2021春)--第二章课后题(选择题+编程题)答案与详解 目录 Java程序设计(2021春)--第二章课后题(选择题+编程题)答案与详解 第二章选择题 2.1 面向对象方法的特性 ...
- Java程序设计(2021春)——第四章接口与多态课后题(选择题+编程题)答案与详解
Java程序设计(2021春)--第四章接口与多态课后题(选择题+编程题)答案与详解 目录 Java程序设计(2021春)--第四章接口与多态课后题(选择题+编程题)答案与详解 第四章选择题 4.0 ...
- “全栈2019”Java多线程第三十章:尝试获取锁tryLock()方法详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- Java多线程编程中Future模式的详解
Java多线程编程中,常用的多线程设计模式包括:Future模式.Master-Worker模式.Guarded Suspeionsion模式.不变模式和生产者-消费者模式等.这篇文章主要讲述Futu ...
- Java多线程编程中Future模式的详解<转>
Java多线程编程中,常用的多线程设计模式包括:Future模式.Master-Worker模式.Guarded Suspeionsion模式.不变模式和生产者-消费者模式等.这篇文章主要讲述Futu ...
- “全栈2019”Java多线程第二十二章:饥饿线程(Starvation)详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
随机推荐
- Flask的数据库连接池 DBUtils
Flask是没有ORM的操作的,如果在flask中连接数据库有两种方式 一.pymysql 二.SQLAlchemy 是python操作数据库的以一个库,能够进行orm映射官网文档 sqlchemy ...
- 远程连接MySQL服务器
在CentOS虚拟机上安装好了MySQL服务以后,在windows上用Workbench客户端去连接时碰到很多问题,现在把解决过程记录一下. 1.在Windows上ping CentOS IP是可以p ...
- Hadoop HBase概念学习系列之优秀行键设计(十六)
我们通过行键访问HBase.尽管使用扫描过滤器可以一次性指明大量的键,但是HBase仅仅能够根据行键识别出一行. 优秀的行键设计可以保证良好的HBase性能. 1.行键存在于HBase中的每一个单元格 ...
- ZT eoe android4.2 Bluetooth记录01-结构和代码分布
android4.2 Bluetooth记录01-结构和代码分布 作者:cnhua5更新于 08月21日访问(697)评论(2) 在android4.2中,Google更换了android的蓝牙协议栈 ...
- 第一篇,编译生成libcef_dll_wrapper
因为工作原因需要在程序里面嵌入地图,在网上看了百度地图和高德地图都没有提供c++的接口,提供有web接口,那只好在程序里面嵌入web控件了,第一想到的是web browser控件,接着脑海里又想到IE ...
- python第三课——数据类型2
day03: 1.列表:list 特点:有序的(有索引.定义和显示顺序是一致的).可变的(既可以改变元素内容也可以自动扩容).可重复的. 可以存储任何的数据类型数据 定义个列表如下: lt = ['宋 ...
- ubuntu16.04中安装下载工具uget+aria2并配置chrome (stable版)
1.安装uGut sudo apt-get install uget 2.安装aria2 sudo apt-get install arias 3.配置uGet默认下载插件为aria2 菜单栏依次打开 ...
- Day2 CSS
什么是CSS 层叠样式表(cascading style sheet) 控制页面元素的显示方式.(添加样式) CSS语法 行间样式 行内式是在标记的style属性中设定CSS样式.这种方式没有体现出C ...
- 有关linqtosql和EF的区别
LINQ to SQL和Entity Framework都是一种包含LINQ功能的对象关系映射技术.他们之间的本质区别在于EF对数据库架构和我们查询的类型实行了更好的解耦.使用EF,我们查询的对象不再 ...
- Docker删除/停止容器
应用场景:某个相关的业务需要重启,容器太多了,一个一个通过命令行来关闭太麻烦了,直接一条命令直接搞定. 命令如下: $ docker ps // 查看所有正在运行容器 $ docker stop co ...